 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Auxiliary Information for Person Re-Identification -- A Tutorial Overview
Nov 15, 2022


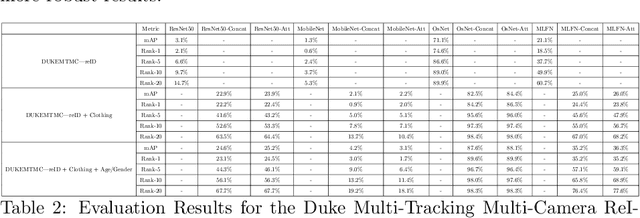
Person re-identification (re-id) is a pivotal task within an intelligent surveillance pipeline and there exist numerous re-id frameworks that achieve satisfactory performance in challenging benchmarks. However, these systems struggle to generate acceptable results when there are significant differences between the camera views, illumination conditions, or occlusions. This result can be attributed to the deficiency that exists within many recently proposed re-id pipelines where they are predominately driven by appearance-based features and little attention is paid to other auxiliary information that could aid the re-id. In this paper, we systematically review the current State-Of-The-Art (SOTA) methods in both uni-modal and multimodal person re-id. Extending beyond a conceptual framework, we illustrate how the existing SOTA methods can be extended to support these additional auxiliary information and quantitatively evaluate the utility of such auxiliary feature information, ranging from logos printed on the objects carried by the subject or printed on the clothes worn by the subject, through to his or her behavioural trajectories. To the best of our knowledge, this is the first work that explores the fusion of multiple information to generate a more discriminant person descriptor and the principal aim of this paper is to provide a thorough theoretical analysis regarding the implementation of such a framework. In addition, using model interpretation techniques, we validate the contributions from different combinations of the auxiliary information versus the original features that the SOTA person re-id models extract. We outline the limitations of the proposed approaches and propose future research directions that could be pursued to advance the area of multi-modal person re-id.