 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAGAN: Adversarial Approach To Learning Domain Invariant Language Features
Paper and Code
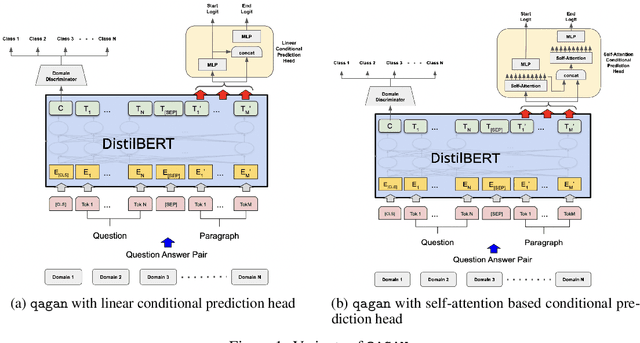
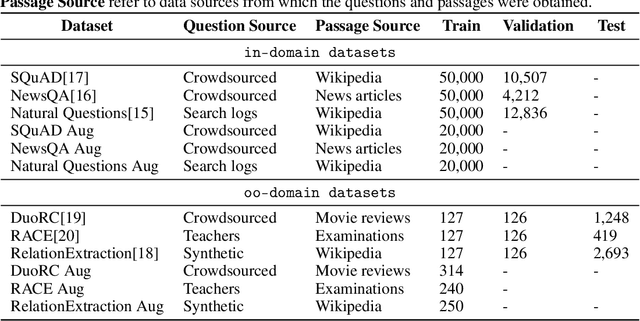
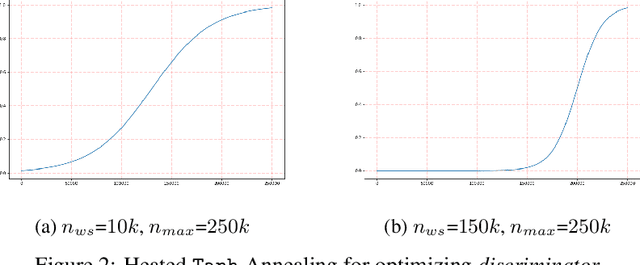

Training models that are robust to data domain shift has gained an increasing interest both in academia and industry. Question-Answering language models, being one of the typical problem in Natural Language Processing (NLP) research, has received much success with the advent of large transformer models. However, existing approaches mostly work under the assumption that data is drawn from same distribution during training and testing which is unrealistic and non-scalable in the wild. In this paper, we explore adversarial training approach towards learning domain-invariant features so that language models can generalize well to out-of-domain datasets. We also inspect various other ways to boost our model performance including data augmentation by paraphrasing sentences, conditioning end of answer span prediction on the start word, and carefully designed annealing function. Our initial results show that in combination with these methods, we are able to achieve $15.2\%$ improvement in EM score and $5.6\%$ boost in F1 score on out-of-domain validation dataset over the baseline. We also dissect our model outputs and visualize the model hidden-states by projecting them onto a lower-dimensional space, and discover that our specific adversarial training approach indeed encourages the model to learn domain invariant embedding and bring them closer in the multi-dimensional space.