 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2VIS: Amodal-Aware Approach to Video Instance Segmentation
Dec 02, 2024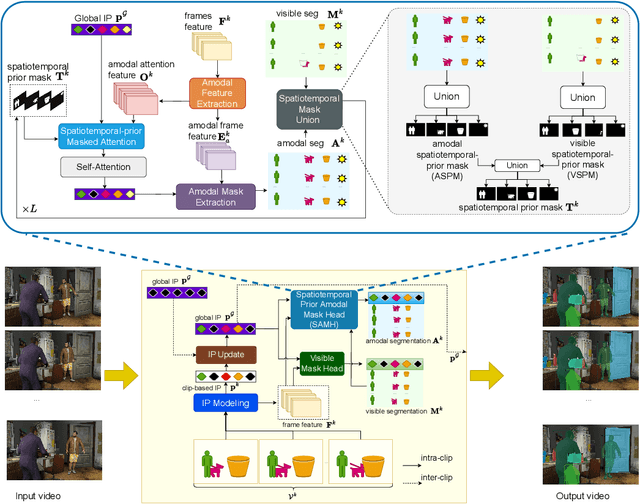
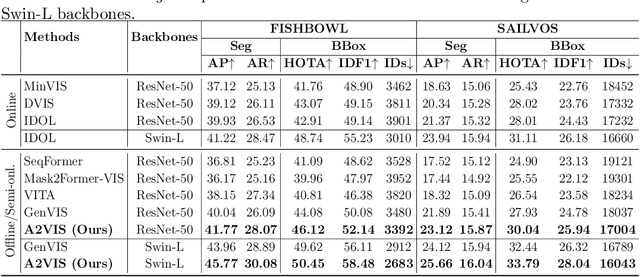
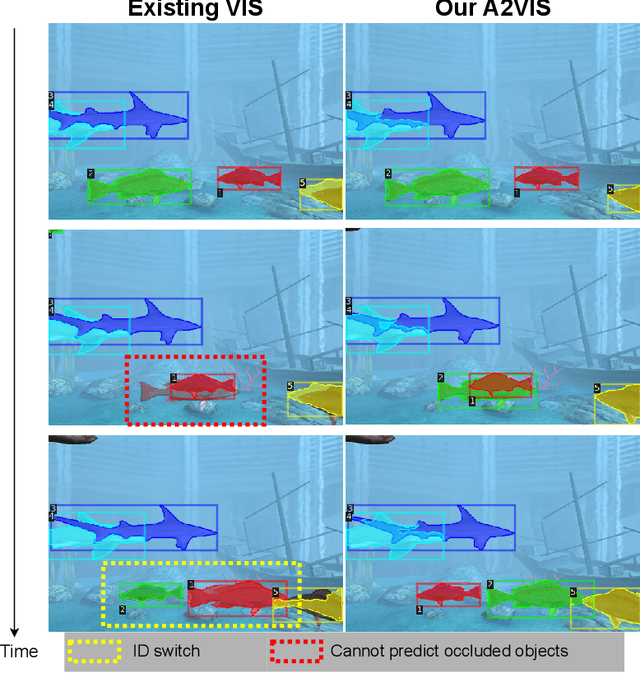
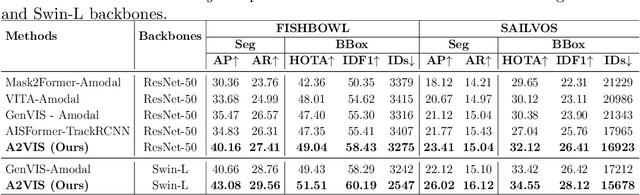
Handling occlusion remains a significant challenge for video instance-level tasks like Multiple Object Tracking (MOT) and Video Instance Segmentation (VIS). In this paper, we propose a novel framework, Amodal-Aware Video Instance Segmentation (A2VIS), which incorporates amodal representations to achieve a reliable and comprehensive understanding of both visible and occluded parts of objects in a video. The key intuition is that awareness of amodal segmentation through spatiotemporal dimension enables a stable stream of object information. In scenarios where objects are partially or completely hidden from view, amodal segmentation offers more consistency and less dramatic changes along the temporal axis compared to visible segmentation. Hence, both amodal and visible information from all clips can be integrated into one global instance prototype. To effectively address the challenge of video amodal segmentation, we introduce the spatiotemporal-prior Amodal Mask Head, which leverages visible information intra clips while extracting amodal characteristics inter clips. Through extensive experiments and ablation studies, we show that A2VIS excels in both MOT and VIS tasks in identifying and tracking object instances with a keen understanding of their full shape.
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Mar 22, 2024Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer