 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Construction in a Misogynist Incels Forum
Jul 09, 2023



Online communities of involuntary celibates (incels) are a prominent source of misogynist hate speech. In this paper, we use quantitative text and network analysis approaches to examine how identity groups are discussed on incels-dot-is, the largest black-pilled incels forum. We find that this community produces a wide range of novel identity terms and, while terms for women are most common, mentions of other minoritized identities are increasing. An analysis of the associations made with identity groups suggests an essentialist ideology where physical appearance, as well as gender and racial hierarchies, determine human value. We discuss implications for research into automated misogynist hate speech detection.
A Weakly Supervised Classifier and Dataset of White Supremacist Language
Jun 27, 2023



We present a dataset and classifier for detecting the language of white supremacist extremism, a growing issue in online hate speech. Our weakly supervised classifier is trained on large datasets of text from explicitly white supremacist domains paired with neutral and anti-racist data from similar domains. We demonstrate that this approach improves generalization performance to new domains. Incorporating anti-racist texts as counterexamples to white supremacist language mitigates bias.
Measuring Stereotypes using Entity-Centric Data
May 16, 2023



Stereotypes inform how we present ourselves and others, and in turn how we behave. They are thus important to measure. Recent work has used projections of embeddings from Distributional Semantic Models (DSMs), such as BERT, to perform these measurements. However, DSMs capture cognitive associations that are not necessarily relevant to the interpersonal nature of stereotyping. Here, we propose and evaluate three novel, entity-centric methods for learning stereotypes from Twitter and Wikipedia biographies. Models are trained by leveraging the fact that multiple phrases are applied to the same person, magnifying the person-centric nature of the learned associations. We show that these models outperform existing approaches to stereotype measurement with respect to 1) predicting which identities people apply to themselves and others, and 2) quantifying stereotypes on salient social dimensions (e.g. gender). Via a case study, we also show the utility of these models for future questions in computational social science.
How Hate Speech Varies by Target Identity: A Computational Analysis
Oct 19, 2022

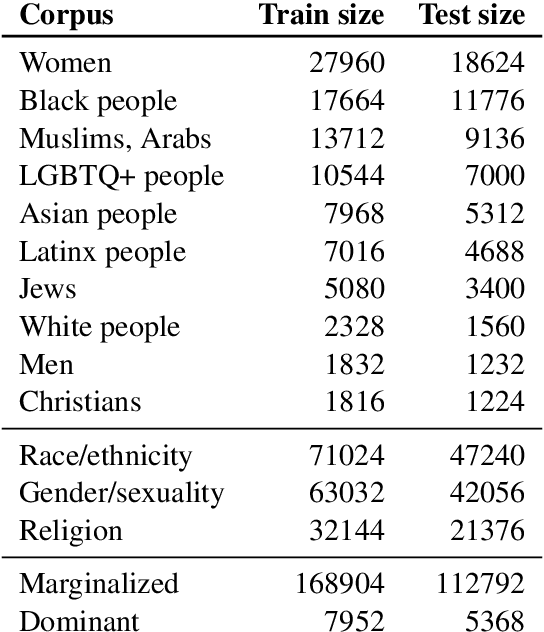
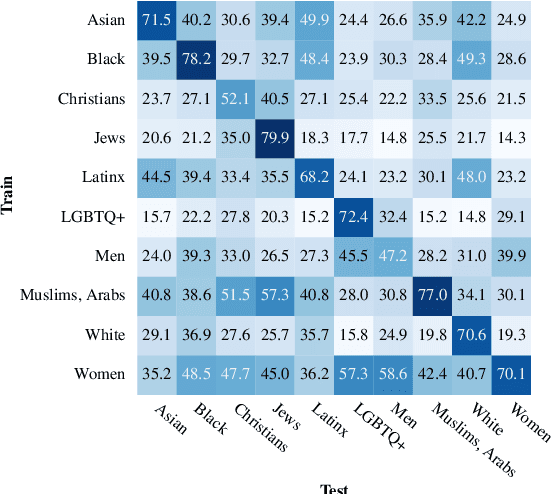
This paper investigates how hate speech varies in systematic ways according to the identities it targets. Across multiple hate speech datasets annotated for targeted identities, we find that classifiers trained on hate speech targeting specific identity groups struggle to generalize to other targeted identities. This provides empirical evidence for differences in hate speech by target identity; we then investigate which patterns structure this variation. We find that the targeted demographic category (e.g. gender/sexuality or race/ethnicity) appears to have a greater effect on the language of hate speech than does the relative social power of the targeted identity group. We also find that words associated with hate speech targeting specific identities often relate to stereotypes, histories of oppression, current social movements, and other social contexts specific to identities. These experiments suggest the importance of considering targeted identity, as well as the social contexts associated with these identities, in automated hate speech classification.