 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe For Building a Compliant Real Estate Chatbot
Oct 07, 2024In recent years, there has been significant effort to align large language models with human preferences. This work focuses on developing a chatbot specialized in the real estate domain, with an emphasis on incorporating compliant behavior to ensure it can be used without perpetuating discriminatory practices like steering and redlining, which have historically plagued the real estate industry in the United States. Building on prior work, we present a method for generating a synthetic general instruction-following dataset, along with safety data. Through extensive evaluations and benchmarks, we fine-tuned a llama-3-8B-instruct model and demonstrated that we can enhance it's performance significantly to match huge closed-source models like GPT-4o while making it safer and more compliant. We open-source the model, data and code to support further development and research in the community.
Measuring Stereotypes using Entity-Centric Data
May 16, 2023



Stereotypes inform how we present ourselves and others, and in turn how we behave. They are thus important to measure. Recent work has used projections of embeddings from Distributional Semantic Models (DSMs), such as BERT, to perform these measurements. However, DSMs capture cognitive associations that are not necessarily relevant to the interpersonal nature of stereotyping. Here, we propose and evaluate three novel, entity-centric methods for learning stereotypes from Twitter and Wikipedia biographies. Models are trained by leveraging the fact that multiple phrases are applied to the same person, magnifying the person-centric nature of the learned associations. We show that these models outperform existing approaches to stereotype measurement with respect to 1) predicting which identities people apply to themselves and others, and 2) quantifying stereotypes on salient social dimensions (e.g. gender). Via a case study, we also show the utility of these models for future questions in computational social science.
Answering Questions Over Knowledge Graphs Using Logic Programming Along with Language Models
Mar 03, 2023Question Answering over Knowledge Graphs (KGQA) is the task of answering natural language questions over a knowledge graph (KG). This task requires a model to reason over multiple edges of the KG to reach the right answer. In this work, we present a method to equip large language models (LLMs) with classic logical programming languages to provide an explainable solution to the problem. Our goal is to extract the representation of the question in the form of a Prolog query, which can then be used to answer the query programmatically. To demonstrate the effectiveness of this approach, we use the MetaQA dataset and show that our method finds the correct answer entities for all the questions in the test dataset.
Incentives in Two-sided Matching Markets with Prediction-enhanced Preference-formation
Sep 16, 2021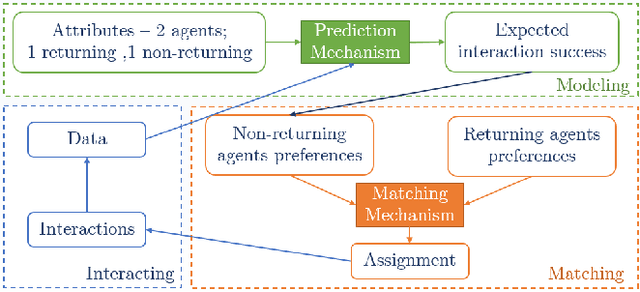

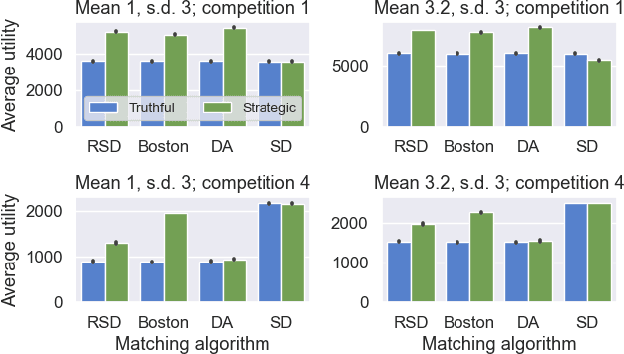

Two-sided matching markets have long existed to pair agents in the absence of regulated exchanges. A common example is school choice, where a matching mechanism uses student and school preferences to assign students to schools. In such settings, forming preferences is both difficult and critical. Prior work has suggested various prediction mechanisms that help agents make decisions about their preferences. Although often deployed together, these matching and prediction mechanisms are almost always analyzed separately. The present work shows that at the intersection of the two lies a previously unexplored type of strategic behavior: agents returning to the market (e.g., schools) can attack future predictions by interacting short-term non-optimally with their matches. Here, we first introduce this type of strategic behavior, which we call an `adversarial interaction attack'. Next, we construct a formal economic model that captures the feedback loop between prediction mechanisms designed to assist agents and the matching mechanism used to pair them. This economic model allows us to analyze adversarial interaction attacks. Finally, using school choice as an example, we build a simulation to show that, as the trust in and accuracy of predictions increases, schools gain progressively more by initiating an adversarial interaction attack. We also show that this attack increases inequality in the student population.
MDR Cluster-Debias: A Nonlinear WordEmbedding Debiasing Pipeline
Jun 20, 2020

Existing methods for debiasing word embeddings often do so only superficially, in that words that are stereotypically associated with, e.g., a particular gender in the original embedding space can still be clustered together in the debiased space. However, there has yet to be a study that explores why this residual clustering exists, and how it might be addressed. The present work fills this gap. We identify two potential reasons for which residual bias exists and develop a new pipeline, MDR Cluster-Debias, to mitigate this bias. We explore the strengths and weaknesses of our method, finding that it significantly outperforms other existing debiasing approaches on a variety of upstream bias tests but achieves limited improvement on decreasing gender bias in a downstream task. This indicates that word embeddings encode gender bias in still other ways, not necessarily captured by upstream tests.
When do Word Embeddings Accurately Reflect Surveys on our Beliefs About People?
Apr 25, 2020



Social biases are encoded in word embeddings. This presents a unique opportunity to study society historically and at scale, and a unique danger when embeddings are used in downstream applications. Here, we investigate the extent to which publicly-available word embeddings accurately reflect beliefs about certain kinds of people as measured via traditional survey methods. We find that biases found in word embeddings do, on average, closely mirror survey data across seventeen dimensions of social meaning. However, we also find that biases in embeddings are much more reflective of survey data for some dimensions of meaning (e.g. gender) than others (e.g. race), and that we can be highly confident that embedding-based measures reflect survey data only for the most salient biases.
Theory In, Theory Out: The uses of social theory in machine learning for social science
Jan 15, 2020
Research at the intersection of machine learning and the social sciences has provided critical new insights into social behavior. At the same time, a variety of critiques have been raised ranging from technical issues with the data used and features constructed, problematic assumptions built into models, their limited interpretability, and their contribution to bias and inequality. We argue such issues arise primarily because of the lack of social theory at various stages of the model building and analysis. In the first half of this paper, we walk through how social theory can be used to answer the basic methodological and interpretive questions that arise at each stage of the machine learning pipeline. In the second half, we show how theory can be used to assess and compare the quality of different social learning models, including interpreting, generalizing, and assessing the fairness of models. We believe this paper can act as a guide for computer and social scientists alike to navigate the substantive questions involved in applying the tools of machine learning to social data.