 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESC-Judge: A Framework for Comparing Emotional Support Conversational Agents
May 18, 2025


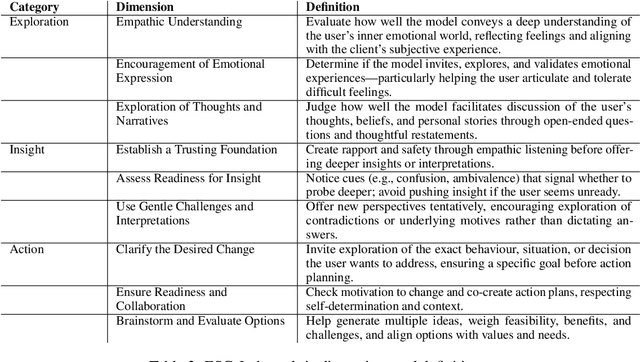
Large language models (LLMs) increasingly power mental-health chatbots, yet the field still lacks a scalable, theory-grounded way to decide which model is most effective to deploy. We present ESC-Judge, the first end-to-end evaluation framework that (i) grounds head-to-head comparisons of emotional-support LLMs in Clara Hill's established Exploration-Insight-Action counseling model, providing a structured and interpretable view of performance, and (ii) fully automates the evaluation pipeline at scale. ESC-Judge operates in three stages: first, it synthesizes realistic help-seeker roles by sampling empirically salient attributes such as stressors, personality, and life history; second, it has two candidate support agents conduct separate sessions with the same role, isolating model-specific strategies; and third, it asks a specialized judge LLM to express pairwise preferences across rubric-anchored skills that span the Exploration, Insight, and Action spectrum. In our study, ESC-Judge matched PhD-level annotators on 85 percent of Exploration, 83 percent of Insight, and 86 percent of Action decisions, demonstrating human-level reliability at a fraction of the cost. All code, prompts, synthetic roles, transcripts, and judgment scripts are released to promote transparent progress in emotionally supportive AI.
A Recipe For Building a Compliant Real Estate Chatbot
Oct 07, 2024In recent years, there has been significant effort to align large language models with human preferences. This work focuses on developing a chatbot specialized in the real estate domain, with an emphasis on incorporating compliant behavior to ensure it can be used without perpetuating discriminatory practices like steering and redlining, which have historically plagued the real estate industry in the United States. Building on prior work, we present a method for generating a synthetic general instruction-following dataset, along with safety data. Through extensive evaluations and benchmarks, we fine-tuned a llama-3-8B-instruct model and demonstrated that we can enhance it's performance significantly to match huge closed-source models like GPT-4o while making it safer and more compliant. We open-source the model, data and code to support further development and research in the community.
Steering Conversational Large Language Models for Long Emotional Support Conversations
Feb 16, 2024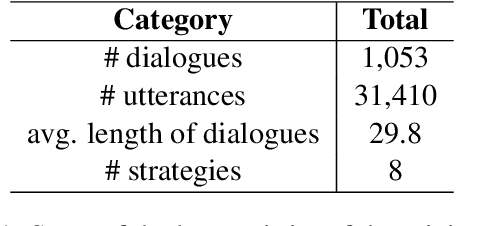
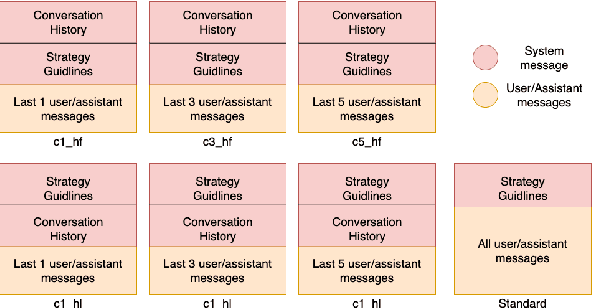

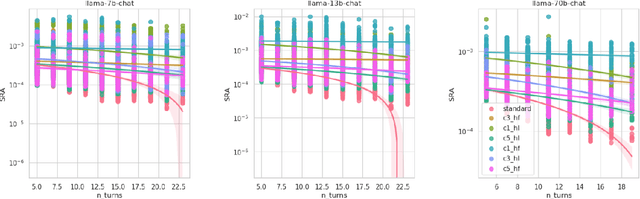
In this study, we address the challenge of consistently following emotional support strategies in long conversations by large language models (LLMs). We introduce the Strategy-Relevant Attention (SRA) metric, a model-agnostic measure designed to evaluate the effectiveness of LLMs in adhering to strategic prompts in emotional support contexts. By analyzing conversations within the Emotional Support Conversations dataset (ESConv) using LLaMA models, we demonstrate that SRA is significantly correlated with a model's ability to sustain the outlined strategy throughout the interactions. Our findings reveal that the application of SRA-informed prompts leads to enhanced strategic adherence, resulting in conversations that more reliably exhibit the desired emotional support strategies over longer conversations. Furthermore, we contribute a comprehensive, multi-branch synthetic conversation dataset for ESConv, featuring a variety of strategy continuations informed by our optimized prompting method. The code and data are publicly available on our Github.
Measuring Stereotypes using Entity-Centric Data
May 16, 2023



Stereotypes inform how we present ourselves and others, and in turn how we behave. They are thus important to measure. Recent work has used projections of embeddings from Distributional Semantic Models (DSMs), such as BERT, to perform these measurements. However, DSMs capture cognitive associations that are not necessarily relevant to the interpersonal nature of stereotyping. Here, we propose and evaluate three novel, entity-centric methods for learning stereotypes from Twitter and Wikipedia biographies. Models are trained by leveraging the fact that multiple phrases are applied to the same person, magnifying the person-centric nature of the learned associations. We show that these models outperform existing approaches to stereotype measurement with respect to 1) predicting which identities people apply to themselves and others, and 2) quantifying stereotypes on salient social dimensions (e.g. gender). Via a case study, we also show the utility of these models for future questions in computational social science.
Answering Questions Over Knowledge Graphs Using Logic Programming Along with Language Models
Mar 03, 2023Question Answering over Knowledge Graphs (KGQA) is the task of answering natural language questions over a knowledge graph (KG). This task requires a model to reason over multiple edges of the KG to reach the right answer. In this work, we present a method to equip large language models (LLMs) with classic logical programming languages to provide an explainable solution to the problem. Our goal is to extract the representation of the question in the form of a Prolog query, which can then be used to answer the query programmatically. To demonstrate the effectiveness of this approach, we use the MetaQA dataset and show that our method finds the correct answer entities for all the questions in the test dataset.