 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Generate or Discriminate? Methodological Considerations for Measuring Cultural Alignment in LLMs
Jan 06, 2026Socio-demographic prompting (SDP) - prompting Large Language Models (LLMs) using demographic proxies to generate culturally aligned outputs - often shows LLM responses as stereotypical and biased. While effective in assessing LLMs' cultural competency, SDP is prone to confounding factors such as prompt sensitivity, decoding parameters, and the inherent difficulty of generation over discrimination tasks due to larger output spaces. These factors complicate interpretation, making it difficult to determine if the poor performance is due to bias or the task design. To address this, we use inverse socio-demographic prompting (ISDP), where we prompt LLMs to discriminate and predict the demographic proxy from actual and simulated user behavior from different users. We use the Goodreads-CSI dataset (Saha et al., 2025), which captures difficulty in understanding English book reviews for users from India, Mexico, and the USA, and test four LLMs: Aya-23, Gemma-2, GPT-4o, and LLaMA-3.1 with ISDP. Results show that models perform better with actual behaviors than simulated ones, contrary to what SDP suggests. However, performance with both behavior types diminishes and becomes nearly equal at the individual level, indicating limits to personalization.
Bridging AI and Carbon Capture: A Dataset for LLMs in Ionic Liquids and CBE Research
May 17, 2025



Large Language Models (LLMs) have demonstrated exceptional performance in general knowledge and reasoning tasks across various domains. However, their effectiveness in specialized scientific fields like Chemical and Biological Engineering (CBE) remains underexplored. Addressing this gap requires robust evaluation benchmarks that assess both knowledge and reasoning capabilities in these niche areas, which are currently lacking. To bridge this divide, we present a comprehensive empirical analysis of LLM reasoning capabilities in CBE, with a focus on Ionic Liquids (ILs) for carbon sequestration - an emerging solution for mitigating global warming. We develop and release an expert - curated dataset of 5,920 examples designed to benchmark LLMs' reasoning in this domain. The dataset incorporates varying levels of difficulty, balancing linguistic complexity and domain-specific knowledge. Using this dataset, we evaluate three open-source LLMs with fewer than 10 billion parameters. Our findings reveal that while smaller general-purpose LLMs exhibit basic knowledge of ILs, they lack the specialized reasoning skills necessary for advanced applications. Building on these results, we discuss strategies to enhance the utility of LLMs for carbon capture research, particularly using ILs. Given the significant carbon footprint of LLMs, aligning their development with IL research presents a unique opportunity to foster mutual progress in both fields and advance global efforts toward achieving carbon neutrality by 2050.
From Knowledge to Reasoning: Evaluating LLMs for Ionic Liquids Research in Chemical and Biological Engineering
May 11, 2025Although Large Language Models (LLMs) have achieved remarkable performance in diverse general knowledge and reasoning tasks, their utility in the scientific domain of Chemical and Biological Engineering (CBE) is unclear. Hence, it necessitates challenging evaluation benchmarks that can measure LLM performance in knowledge- and reasoning-based tasks, which is lacking. As a foundational step, we empirically measure the reasoning capabilities of LLMs in CBE. We construct and share an expert-curated dataset of 5,920 examples for benchmarking LLMs' reasoning capabilities in the niche domain of Ionic Liquids (ILs) for carbon sequestration, an emergent solution to reducing global warming. The dataset presents different difficulty levels by varying along the dimensions of linguistic and domain-specific knowledge. Benchmarking three less than 10B parameter open-source LLMs on the dataset suggests that while smaller general-purpose LLMs are knowledgeable about ILs, they lack domain-specific reasoning capabilities. Based on our results, we further discuss considerations for leveraging LLMs for carbon capture research using ILs. Since LLMs have a high carbon footprint, gearing them for IL research can symbiotically benefit both fields and help reach the ambitious carbon neutrality target by 2050. Dataset link: https://github.com/sougata-ub/llms_for_ionic_liquids
Women, Infamous, and Exotic Beings: What Honorific Usages in Wikipedia Reveal about the Socio-Cultural Norms
Jan 07, 2025Honorifics serve as powerful linguistic markers that reflect social hierarchies and cultural values. This paper presents a large-scale, cross-linguistic exploration of usage of honorific pronouns in Bengali and Hindi Wikipedia articles, shedding light on how socio-cultural factors shape language. Using LLM (GPT-4o), we annotated 10, 000 articles of real and fictional beings in each language for several sociodemographic features such as gender, age, fame, and exoticness, and the use of honorifics. We find that across all feature combinations, use of honorifics is consistently more common in Bengali than Hindi. For both languages, the use non-honorific pronouns is more commonly observed for infamous, juvenile, and exotic beings. Notably, we observe a gender bias in use of honorifics in Hindi, with men being more commonly referred to with honorifics than women.
Steering Conversational Large Language Models for Long Emotional Support Conversations
Feb 16, 2024
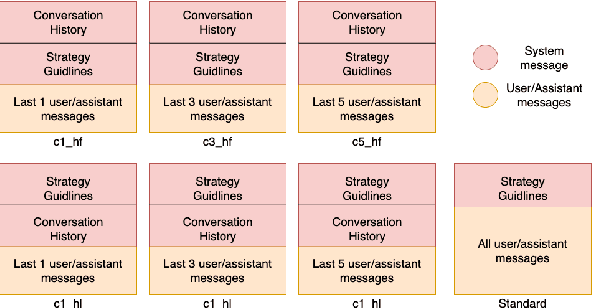

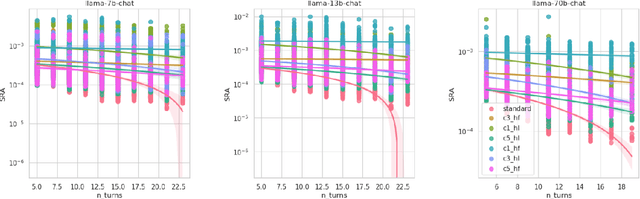
In this study, we address the challenge of consistently following emotional support strategies in long conversations by large language models (LLMs). We introduce the Strategy-Relevant Attention (SRA) metric, a model-agnostic measure designed to evaluate the effectiveness of LLMs in adhering to strategic prompts in emotional support contexts. By analyzing conversations within the Emotional Support Conversations dataset (ESConv) using LLaMA models, we demonstrate that SRA is significantly correlated with a model's ability to sustain the outlined strategy throughout the interactions. Our findings reveal that the application of SRA-informed prompts leads to enhanced strategic adherence, resulting in conversations that more reliably exhibit the desired emotional support strategies over longer conversations. Furthermore, we contribute a comprehensive, multi-branch synthetic conversation dataset for ESConv, featuring a variety of strategy continuations informed by our optimized prompting method. The code and data are publicly available on our Github.
Consolidating Strategies for Countering Hate Speech Using Persuasive Dialogues
Jan 15, 2024Hateful comments are prevalent on social media platforms. Although tools for automatically detecting, flagging, and blocking such false, offensive, and harmful content online have lately matured, such reactive and brute force methods alone provide short-term and superficial remedies while the perpetrators persist. With the public availability of large language models which can generate articulate synthetic and engaging content at scale, there are concerns about the rapid growth of dissemination of such malicious content on the web. There is now a need to focus on deeper, long-term solutions that involve engaging with the human perpetrator behind the source of the content to change their viewpoint or at least bring down the rhetoric using persuasive means. To do that, we propose defining and experimenting with controllable strategies for generating counter-arguments to hateful comments in online conversations. We experiment with controlling response generation using features based on (i) argument structure and reasoning-based Walton argument schemes, (ii) counter-argument speech acts, and (iii) human characteristics-based qualities such as Big-5 personality traits and human values. Using automatic and human evaluations, we determine the best combination of features that generate fluent, argumentative, and logically sound arguments for countering hate. We further share the developed computational models for automatically annotating text with such features, and a silver-standard annotated version of an existing hate speech dialog corpora.
Rudolf Christoph Eucken at SemEval-2023 Task 4: An Ensemble Approach for Identifying Human Values from Arguments
May 09, 2023The subtle human values we acquire through life experiences govern our thoughts and gets reflected in our speech. It plays an integral part in capturing the essence of our individuality and making it imperative to identify such values in computational systems that mimic human actions. Computational argumentation is a field that deals with the argumentation capabilities of humans and can benefit from identifying such values. Motivated by that, we present an ensemble approach for detecting human values from argument text. Our ensemble comprises three models: (i) An entailment-based model for determining the human values based on their descriptions, (ii) A Roberta-based classifier that predicts the set of human values from an argument. (iii) A Roberta-based classifier to predict a reduced set of human values from an argument. We experiment with different ways of combining the models and report our results. Furthermore, our best combination achieves an overall F1 score of 0.48 on the main test set.
ArgU: A Controllable Factual Argument Generator
May 09, 2023Effective argumentation is essential towards a purposeful conversation with a satisfactory outcome. For example, persuading someone to reconsider smoking might involve empathetic, well founded arguments based on facts and expert opinions about its ill-effects and the consequences on one's family. However, the automatic generation of high-quality factual arguments can be challenging. Addressing existing controllability issues can make the recent advances in computational models for argument generation a potential solution. In this paper, we introduce ArgU: a neural argument generator capable of producing factual arguments from input facts and real-world concepts that can be explicitly controlled for stance and argument structure using Walton's argument scheme-based control codes. Unfortunately, computational argument generation is a relatively new field and lacks datasets conducive to training. Hence, we have compiled and released an annotated corpora of 69,428 arguments spanning six topics and six argument schemes, making it the largest publicly available corpus for identifying argument schemes; the paper details our annotation and dataset creation framework. We further experiment with an argument generation strategy that establishes an inference strategy by generating an ``argument template'' before actual argument generation. Our results demonstrate that it is possible to automatically generate diverse arguments exhibiting different inference patterns for the same set of facts by using control codes based on argument schemes and stance.
Diving Deep into Modes of Fact Hallucinations in Dialogue Systems
Jan 11, 2023



Knowledge Graph(KG) grounded conversations often use large pre-trained models and usually suffer from fact hallucination. Frequently entities with no references in knowledge sources and conversation history are introduced into responses, thus hindering the flow of the conversation -- existing work attempt to overcome this issue by tweaking the training procedure or using a multi-step refining method. However, minimal effort is put into constructing an entity-level hallucination detection system, which would provide fine-grained signals that control fallacious content while generating responses. As a first step to address this issue, we dive deep to identify various modes of hallucination in KG-grounded chatbots through human feedback analysis. Secondly, we propose a series of perturbation strategies to create a synthetic dataset named FADE (FActual Dialogue Hallucination DEtection Dataset). Finally, we conduct comprehensive data analyses and create multiple baseline models for hallucination detection to compare against human-verified data and already established benchmarks.
Using Multi-Encoder Fusion Strategies to Improve Personalized Response Selection
Aug 30, 2022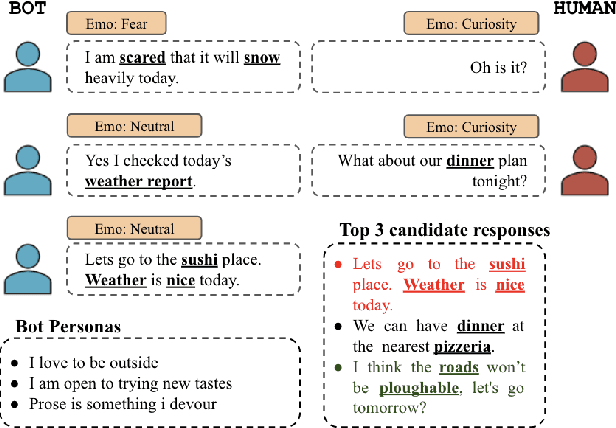

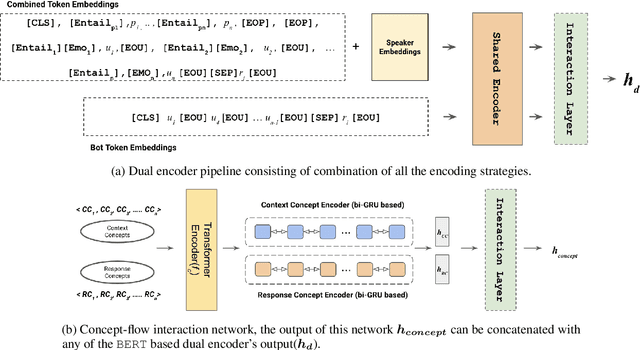
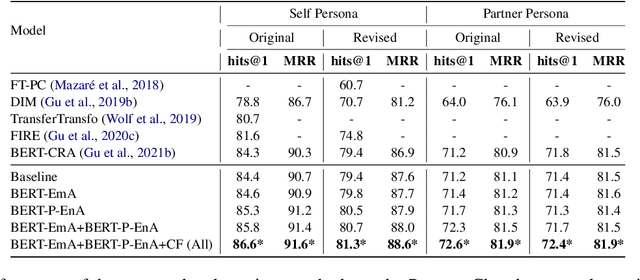
Personalized response selection systems are generally grounded on persona. However, there exists a co-relation between persona and empathy, which is not explored well in these systems. Also, faithfulness to the conversation context plunges when a contradictory or an off-topic response is selected. This paper attempts to address these issues by proposing a suite of fusion strategies that capture the interaction between persona, emotion, and entailment information of the utterances. Ablation studies on the Persona-Chat dataset show that incorporating emotion and entailment improves the accuracy of response selection. We combine our fusion strategies and concept-flow encoding to train a BERT-based model which outperforms the previous methods by margins larger than 2.3 % on original personas and 1.9 % on revised personas in terms of hits@1 (top-1 accuracy), achieving a new state-of-the-art performance on the Persona-Chat dataset.