 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat metrics of participation balance predict outcomes of collaborative learning with a robot?
May 17, 2024

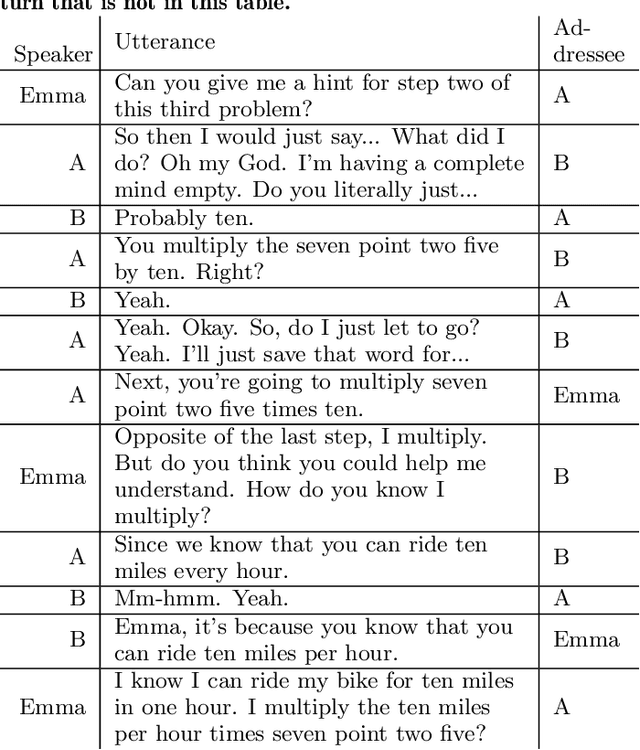
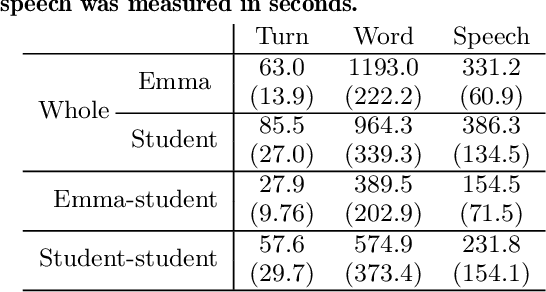
One of the keys to the success of collaborative learning is balanced participation by all learners, but this does not always happen naturally. Pedagogical robots have the potential to facilitate balance. However, it remains unclear what participation balance robots should aim at; various metrics have been proposed, but it is still an open question whether we should balance human participation in human-human interactions (HHI) or human-robot interactions (HRI) and whether we should consider robots' participation in collaborative learning involving multiple humans and a robot. This paper examines collaborative learning between a pair of students and a teachable robot that acts as a peer tutee to answer the aforementioned question. Through an exploratory study, we hypothesize which balance metrics in the literature and which portions of dialogues (including vs. excluding robots' participation and human participation in HHI vs. HRI) will better predict learning as a group. We test the hypotheses with another study and replicate them with automatically obtained units of participation to simulate the information available to robots when they adaptively fix imbalances in real-time. Finally, we discuss recommendations on which metrics learning science researchers should choose when trying to understand how to facilitate collaboration.
Modeling Non-Cooperative Dialogue: Theoretical and Empirical Insights
Jul 15, 2022
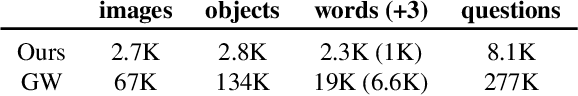


Investigating cooperativity of interlocutors is central in studying pragmatics of dialogue. Models of conversation that only assume cooperative agents fail to explain the dynamics of strategic conversations. Thus, we investigate the ability of agents to identify non-cooperative interlocutors while completing a concurrent visual-dialogue task. Within this novel setting, we study the optimality of communication strategies for achieving this multi-task objective. We use the tools of learning theory to develop a theoretical model for identifying non-cooperative interlocutors and apply this theory to analyze different communication strategies. We also introduce a corpus of non-cooperative conversations about images in the GuessWhat?! dataset proposed by De Vries et al. (2017). We use reinforcement learning to implement multiple communication strategies in this context and find empirical results validate our theory.
Domain-robust VQA with diverse datasets and methods but no target labels
Mar 29, 2021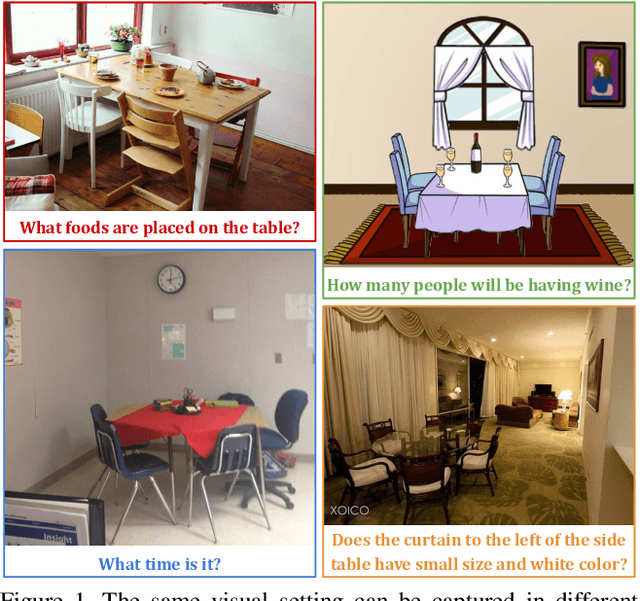


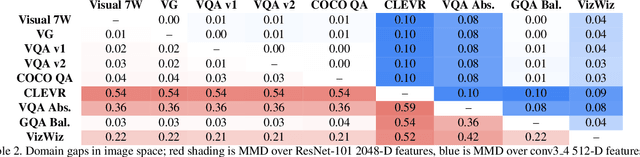
The observation that computer vision methods overfit to dataset specifics has inspired diverse attempts to make object recognition models robust to domain shifts. However, similar work on domain-robust visual question answering methods is very limited. Domain adaptation for VQA differs from adaptation for object recognition due to additional complexity: VQA models handle multimodal inputs, methods contain multiple steps with diverse modules resulting in complex optimization, and answer spaces in different datasets are vastly different. To tackle these challenges, we first quantify domain shifts between popular VQA datasets, in both visual and textual space. To disentangle shifts between datasets arising from different modalities, we also construct synthetic shifts in the image and question domains separately. Second, we test the robustness of different families of VQA methods (classic two-stream, transformer, and neuro-symbolic methods) to these shifts. Third, we test the applicability of existing domain adaptation methods and devise a new one to bridge VQA domain gaps, adjusted to specific VQA models. To emulate the setting of real-world generalization, we focus on unsupervised domain adaptation and the open-ended classification task formulation.