 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised HOI Detection from Interaction Labels Only and Language/Vision-Language Priors
Paper and Code
Mar 09, 2023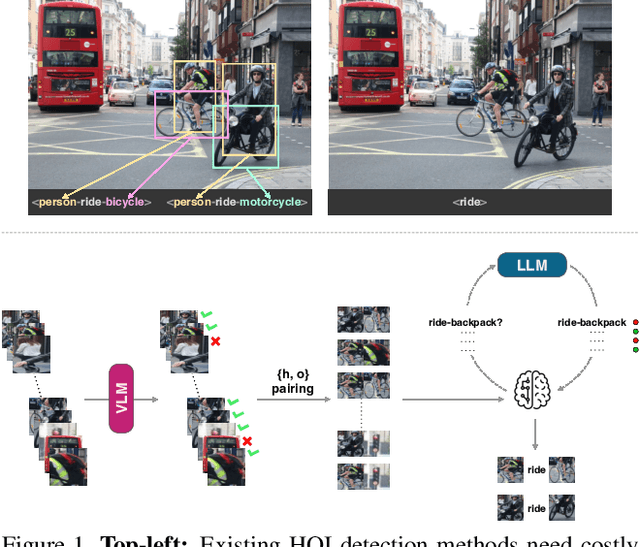
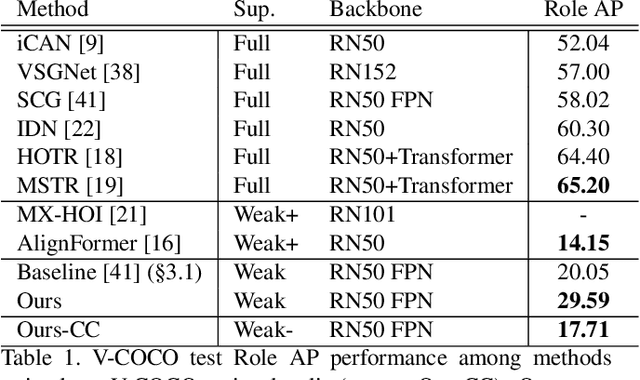
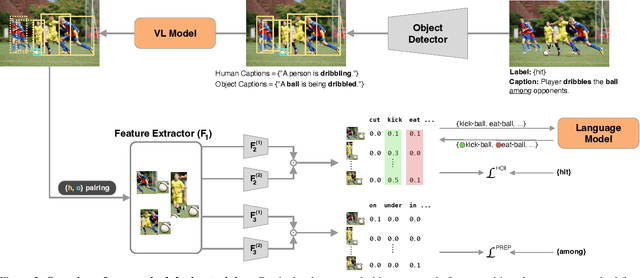
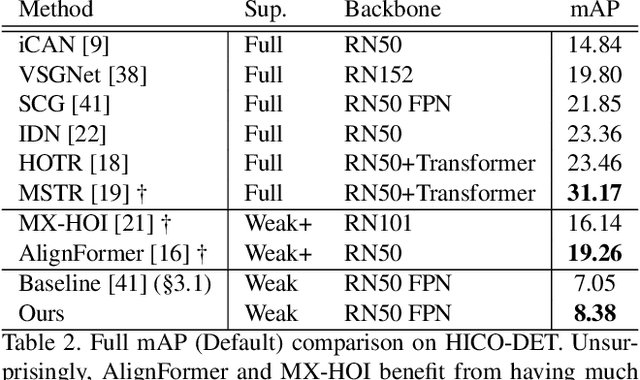
Human-object interaction (HOI) detection aims to extract interacting human-object pairs and their interaction categories from a given natural image. Even though the labeling effort required for building HOI detection datasets is inherently more extensive than for many other computer vision tasks, weakly-supervised directions in this area have not been sufficiently explored due to the difficulty of learning human-object interactions with weak supervision, rooted in the combinatorial nature of interactions over the object and predicate space. In this paper, we tackle HOI detection with the weakest supervision setting in the literature, using only image-level interaction labels, with the help of a pretrained vision-language model (VLM) and a large language model (LLM). We first propose an approach to prune non-interacting human and object proposals to increase the quality of positive pairs within the bag, exploiting the grounding capability of the vision-language model. Second, we use a large language model to query which interactions are possible between a human and a given object category, in order to force the model not to put emphasis on unlikely interactions. Lastly, we use an auxiliary weakly-supervised preposition prediction task to make our model explicitly reason about space. Extensive experiments and ablations show that all of our contributions increase HOI detection performance.