 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolding the Structure of a Document using Deep Learning
Paper and Code
Sep 29, 2019

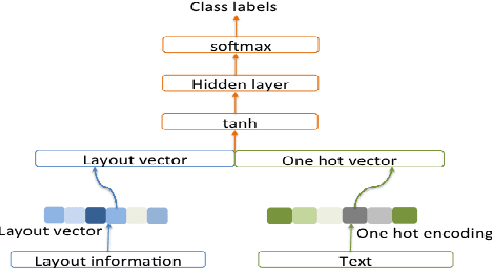

Understanding and extracting of information from large documents, such as business opportunities, academic articles, medical documents and technical reports, poses challenges not present in short documents. Such large documents may be multi-themed, complex, noisy and cover diverse topics. We describe a framework that can analyze large documents and help people and computer systems locate desired information in them. We aim to automatically identify and classify different sections of documents and understand their purpose within the document. A key contribution of our research is modeling and extracting the logical and semantic structure of electronic documents using deep learning techniques. We evaluate the effectiveness and robustness of our framework through extensive experiments on two collections: more than one million scholarly articles from arXiv and a collection of requests for proposal documents from government sources.