 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildfireVLM: AI-powered Analysis for Early Wildfire Detection and Risk Assessment Using Satellite Imagery
Feb 09, 2026Wildfires are a growing threat to ecosystems, human lives, and infrastructure, with their frequency and intensity rising due to climate change and human activities. Early detection is critical, yet satellite-based monitoring remains challenging due to faint smoke signals, dynamic weather conditions, and the need for real-time analysis over large areas. We introduce WildfireVLM, an AI framework that combines satellite imagery wildfire detection with language-driven risk assessment. We construct a labeled wildfire and smoke dataset using imagery from Landsat-8/9, GOES-16, and other publicly available Earth observation sources, including harmonized products with aligned spectral bands. WildfireVLM employs YOLOv12 to detect fire zones and smoke plumes, leveraging its ability to detect small, complex patterns in satellite imagery. We integrate Multimodal Large Language Models (MLLMs) that convert detection outputs into contextualized risk assessments and prioritized response recommendations for disaster management. We validate the quality of risk reasoning using an LLM-as-judge evaluation with a shared rubric. The system is deployed using a service-oriented architecture that supports real-time processing, visual risk dashboards, and long-term wildfire tracking, demonstrating the value of combining computer vision with language-based reasoning for scalable wildfire monitoring.
DUNE: A Machine Learning Deep UNet++ based Ensemble Approach to Monthly, Seasonal and Annual Climate Forecasting
Aug 12, 2024



Capitalizing on the recent availability of ERA5 monthly averaged long-term data records of mean atmospheric and climate fields based on high-resolution reanalysis, deep-learning architectures offer an alternative to physics-based daily numerical weather predictions for subseasonal to seasonal (S2S) and annual means. A novel Deep UNet++-based Ensemble (DUNE) neural architecture is introduced, employing multi-encoder-decoder structures with residual blocks. When initialized from a prior month or year, this architecture produced the first AI-based global monthly, seasonal, or annual mean forecast of 2-meter temperatures (T2m) and sea surface temperatures (SST). ERA5 monthly mean data is used as input for T2m over land, SST over oceans, and solar radiation at the top of the atmosphere for each month of 40 years to train the model. Validation forecasts are performed for an additional two years, followed by five years of forecast evaluations to account for natural annual variability. AI-trained inference forecast weights generate forecasts in seconds, enabling ensemble seasonal forecasts. Root Mean Squared Error (RMSE), Anomaly Correlation Coefficient (ACC), and Heidke Skill Score (HSS) statistics are presented globally and over specific regions. These forecasts outperform persistence, climatology, and multiple linear regression for all domains. DUNE forecasts demonstrate comparable statistical accuracy to NOAA's operational monthly and seasonal probabilistic outlook forecasts over the US but at significantly higher resolutions. RMSE and ACC error statistics for other recent AI-based daily forecasts also show superior performance for DUNE-based forecasts. The DUNE model's application to an ensemble data assimilation cycle shows comparable forecast accuracy with a single high-resolution model, potentially eliminating the need for retraining on extrapolated datasets.
An Ensemble Approach for Compressive Sensing with Quantum
Jun 08, 2020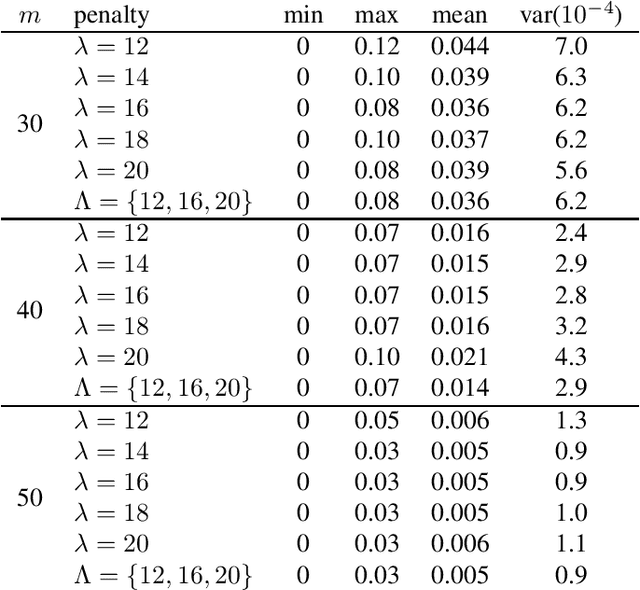
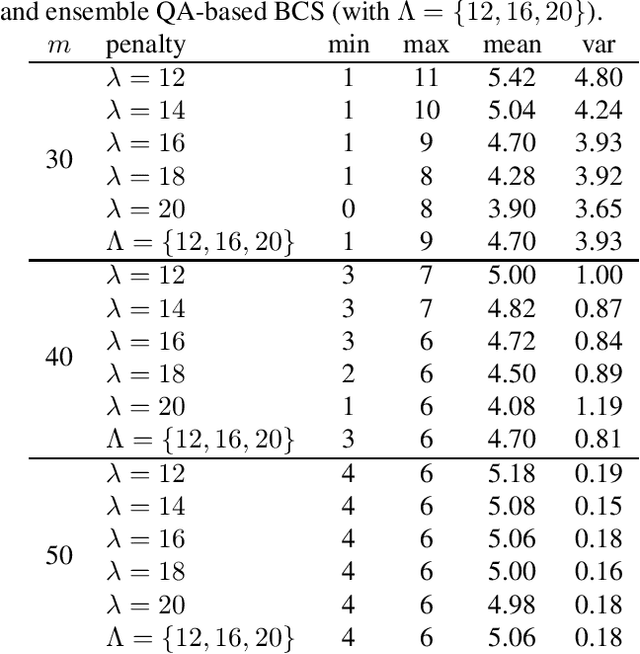
We leverage the idea of a statistical ensemble to improve the quality of quantum annealing based binary compressive sensing. Since executing quantum machine instructions on a quantum annealer can result in an excited state, rather than the ground state of the given Hamiltonian, we use different penalty parameters to generate multiple distinct quadratic unconstrained binary optimization (QUBO) functions whose ground state(s) represent a potential solution of the original problem. We then employ the attained samples from minimizing all corresponding (different) QUBOs to estimate the solution of the problem of binary compressive sensing. Our experiments, on a D-Wave 2000Q quantum processor, demonstrated that the proposed ensemble scheme is notably less sensitive to the calibration of the penalty parameter that controls the trade-off between the feasibility and sparsity of recoveries.
A Hybrid Quantum enabled RBM Advantage: Convolutional Autoencoders For Quantum Image Compression and Generative Learning
Jan 31, 2020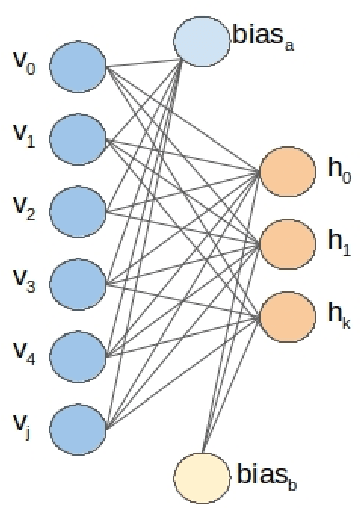

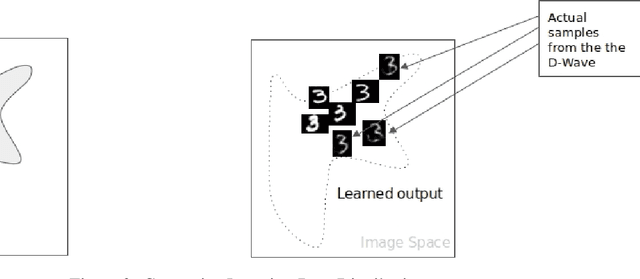

Understanding how the D-Wave quantum computer could be used for machine learning problems is of growing interest. Our work evaluates the feasibility of using the D-Wave as a sampler for machine learning. We describe a hybrid system that combines a classical deep neural network autoencoder with a quantum annealing Restricted Boltzmann Machine (RBM) using the D-Wave. We evaluate our hybrid autoencoder algorithm using two datasets, the MNIST dataset and MNIST Fashion dataset. We evaluate the quality of this method by using a downstream classification method where the training is based on quantum RBM-generated samples. Our method overcomes two key limitations in the current 2000-qubit D-Wave processor, namely the limited number of qubits available to accommodate typical problem sizes for fully connected quantum objective functions and samples that are binary pixel representations. As a consequence of these limitations we are able to show how we achieved nearly a 22-fold compression factor of grayscale 28 x 28 sized images to binary 6 x 6 sized images with a lossy recovery of the original 28 x 28 grayscale images. We further show how generating samples from the D-Wave after training the RBM, resulted in 28 x 28 images that were variations of the original input data distribution, as opposed to recreating the training samples. We formulated an MNIST classification problem using a deep convolutional neural network that used samples from a quantum RBM to train the MNIST classifier and compared the results with an MNIST classifier trained with the original MNIST training data set, as well as an MNIST classifier trained using classical RBM samples. Our hybrid autoencoder approach indicates advantage for RBM results relative to the use of a current RBM classical computer implementation for image-based machine learning and even more promising results for the next generation D-Wave quantum system.
Reinforcement Quantum Annealing: A Quantum-Assisted Learning Automata Approach
Jan 01, 2020


We introduce the reinforcement quantum annealing (RQA) scheme in which an intelligent agent interacts with a quantum annealer that plays the stochastic environment role of learning automata and tries to iteratively find better Ising Hamiltonians for the given problem of interest. As a proof-of-concept, we propose a novel approach for reducing the NP-complete problem of Boolean satisfiability (SAT) to minimizing Ising Hamiltonians and show how to apply the RQA for increasing the probability of finding the global optimum. Our experimental results on two different benchmark SAT problems (namely factoring pseudo-prime numbers and random SAT with phase transitions), using a D-Wave 2000Q quantum processor, demonstrated that RQA finds notably better solutions with fewer samples, compared to state-of-the-art techniques in the realm of quantum annealing.
Ontology-Grounded Topic Modeling for Climate Science Research
Jul 31, 2018


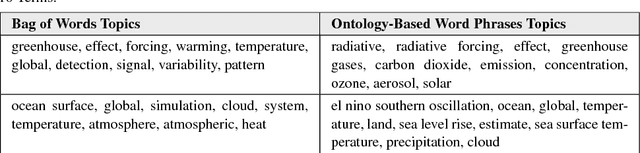
In scientific disciplines where research findings have a strong impact on society, reducing the amount of time it takes to understand, synthesize and exploit the research is invaluable. Topic modeling is an effective technique for summarizing a collection of documents to find the main themes among them and to classify other documents that have a similar mixture of co-occurring words. We show how grounding a topic model with an ontology, extracted from a glossary of important domain phrases, improves the topics generated and makes them easier to understand. We apply and evaluate this method to the climate science domain. The result improves the topics generated and supports faster research understanding, discovery of social networks among researchers, and automatic ontology generation.