 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Latent Value: Taxonomy-Guided Recovery of High-Performing Data from Low-Tier Web Corpora
Jun 05, 2026Dominant web data curation pipelines for pretraining collapse document quality into a single composite score, systematically missing high-value content along dimensions the scorer underweights. We present a taxonomy-driven framework that recovers this value by filtering along semantically meaningful dimensions that composite scores fail to capture. First, building on the ESSENTIAL-WEB taxonomy, we introduce two novel dimensions: timeliness and cultural specificity, both of which show low pairwise NMI with existing ones. We annotate 14M documents using Qwen2.5 32B and distill into a lightweight 0.5B model. To enable rapid corpus-wide annotation, we additionally train a 73M multi-task MLP on E5 embeddings, achieving 50x inference throughput. Second, to navigate the combinatorial explosion of filter configurations, we introduce a compute-efficient two-pass framework: Pass 1 identifies the strongest dimension signals at small scale; Pass 2 constructs and evaluates conjunctive and disjunctive compound filters from the top performers - identifying high-performing configurations at a fraction of full scaling-law cost. Applying the selected filters to deprioritized web data, taxonomy-filtered subsets outperform their unfiltered baselines and even surpass the highest-quality tier. On mid-tier data, our best filter improves over its unfiltered baseline by 12.1% on reasoning, 9.5% on coding, and 2.0% on knowledge benchmarks, exceeding unfiltered top-tier data by 6.7% on reasoning and 13.7% on coding. Furthermore, filtered data from two tiers below the typical production threshold improves by 22.3% on reasoning and 19.5% on coding over its unfiltered baseline, surpassing top-tier data on coding benchmarks. These results establish that vast latent value remains locked in deprioritized web data, and that multi-dimensional taxonomy filtering is a principled, compute-efficient key to unlocking it.
T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
May 04, 2026Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
ByteFlow: Language Modeling through Adaptive Byte Compression without a Tokenizer
Mar 03, 2026Modern language models still rely on fixed, pre-defined subword tokenizations. Once a tokenizer is trained, the LM can only operate at this fixed level of granularity, which often leads to brittle and counterintuitive behaviors even in otherwise strong reasoning models. We introduce \textbf{ByteFlow Net}, a new hierarchical architecture that removes tokenizers entirely and instead enables models to learn their own segmentation of raw byte streams into semantically meaningful units. ByteFlow Net performs compression-driven segmentation based on the coding rate of latent representations, yielding adaptive boundaries \emph{while preserving a static computation graph via Top-$K$ selection}. Unlike prior self-tokenizing methods that depend on brittle heuristics with human-designed inductive biases, ByteFlow Net adapts its internal representation granularity to the input itself. Experiments demonstrate that this compression-based chunking strategy yields substantial performance gains, with ByteFlow Net outperforming both BPE-based Transformers and previous byte-level architectures. These results suggest that end-to-end, tokenizer-free modeling is not only feasible but also more effective, opening a path toward more adaptive and information-grounded language models.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Jun 01, 2023

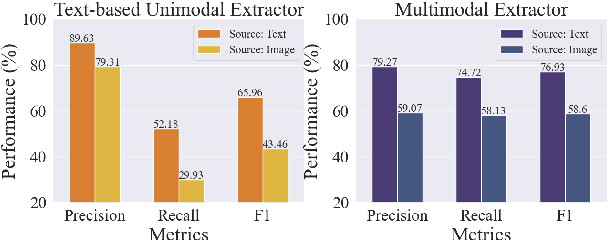
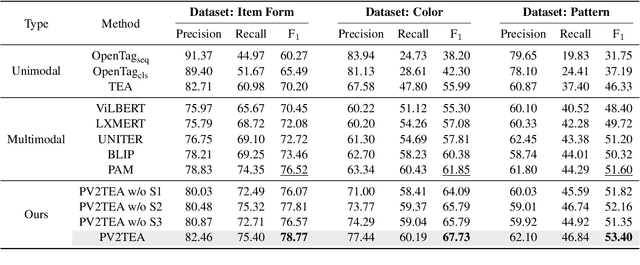
Information extraction, e.g., attribute value extraction, has been extensively studied and formulated based only on text. However, many attributes can benefit from image-based extraction, like color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty. In this paper, we aim to patch the visual modality to the textual-established attribute information extractor. The cross-modality integration faces several unique challenges: (C1) images and textual descriptions are loosely paired intra-sample and inter-samples; (C2) images usually contain rich backgrounds that can mislead the prediction; (C3) weakly supervised labels from textual-established extractors are biased for multimodal training. We present PV2TEA, an encoder-decoder architecture equipped with three bias reduction schemes: (S1) Augmented label-smoothed contrast to improve the cross-modality alignment for loosely-paired image and text; (S2) Attention-pruning that adaptively distinguishes the visual foreground; (S3) Two-level neighborhood regularization that mitigates the label textual bias via reliability estimation. Empirical results on real-world e-Commerce datasets demonstrate up to 11.74% absolute (20.97% relatively) F1 increase over unimodal baselines.
End-to-End Conversational Search for Online Shopping with Utterance Transfer
Sep 12, 2021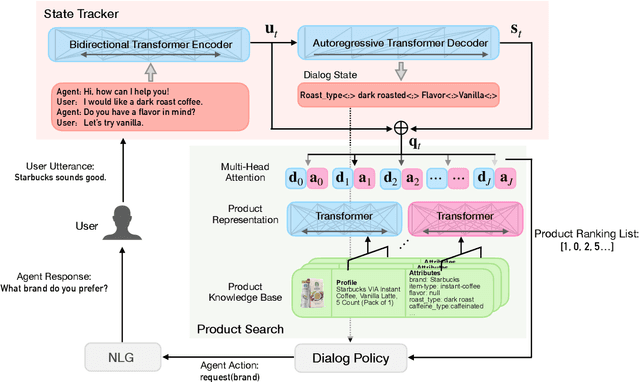
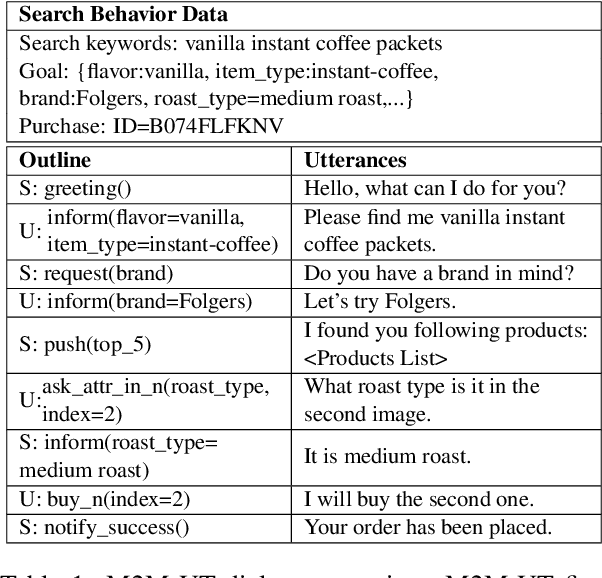
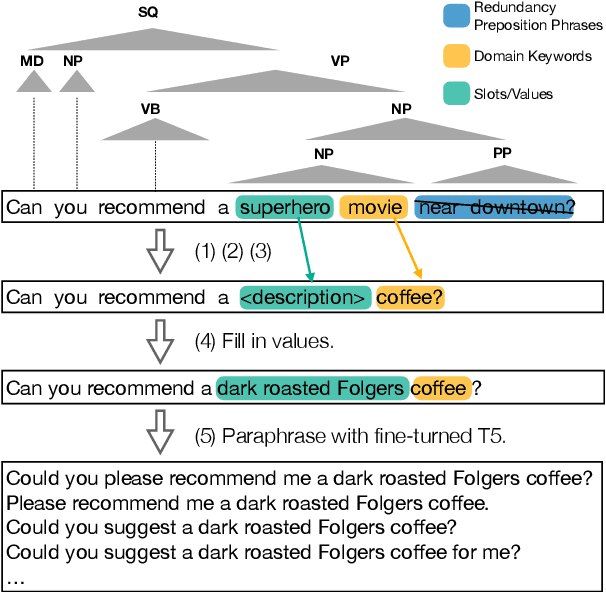

Successful conversational search systems can present natural, adaptive and interactive shopping experience for online shopping customers. However, building such systems from scratch faces real word challenges from both imperfect product schema/knowledge and lack of training dialog data.In this work we first propose ConvSearch, an end-to-end conversational search system that deeply combines the dialog system with search. It leverages the text profile to retrieve products, which is more robust against imperfect product schema/knowledge compared with using product attributes alone. We then address the lack of data challenges by proposing an utterance transfer approach that generates dialogue utterances by using existing dialog from other domains, and leveraging the search behavior data from e-commerce retailer. With utterance transfer, we introduce a new conversational search dataset for online shopping. Experiments show that our utterance transfer method can significantly improve the availability of training dialogue data without crowd-sourcing, and the conversational search system significantly outperformed the best tested baseline.
PAM: Understanding Product Images in Cross Product Category Attribute Extraction
Jun 08, 2021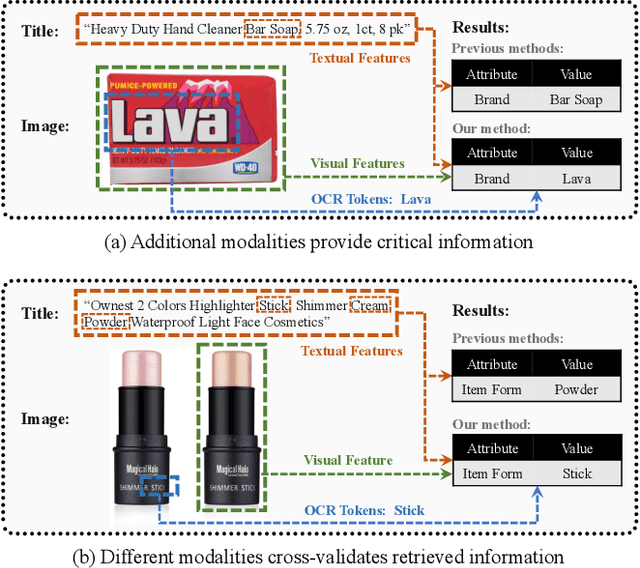
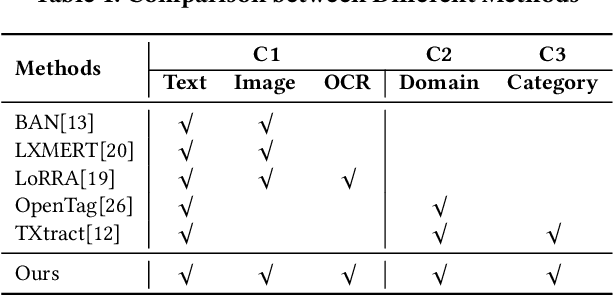

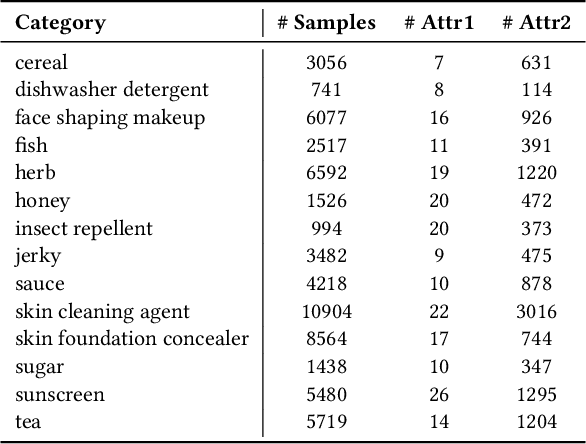
Understanding product attributes plays an important role in improving online shopping experience for customers and serves as an integral part for constructing a product knowledge graph. Most existing methods focus on attribute extraction from text description or utilize visual information from product images such as shape and color. Compared to the inputs considered in prior works, a product image in fact contains more information, represented by a rich mixture of words and visual clues with a layout carefully designed to impress customers. This work proposes a more inclusive framework that fully utilizes these different modalities for attribute extraction. Inspired by recent works in visual question answering, we use a transformer based sequence to sequence model to fuse representations of product text, Optical Character Recognition (OCR) tokens and visual objects detected in the product image. The framework is further extended with the capability to extract attribute value across multiple product categories with a single model, by training the decoder to predict both product category and attribute value and conditioning its output on product category. The model provides a unified attribute extraction solution desirable at an e-commerce platform that offers numerous product categories with a diverse body of product attributes. We evaluated the model on two product attributes, one with many possible values and one with a small set of possible values, over 14 product categories and found the model could achieve 15% gain on the Recall and 10% gain on the F1 score compared to existing methods using text-only features.
AdaTag: Multi-Attribute Value Extraction from Product Profiles with Adaptive Decoding
Jun 04, 2021

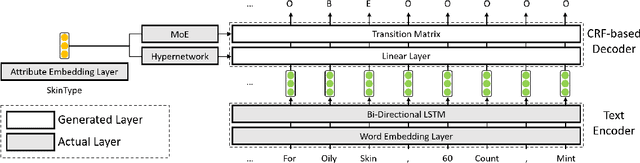
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model's capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.
Adversarial Multitask Learning for Joint Multi-Feature and Multi-Dialect Morphological Modeling
Oct 28, 2019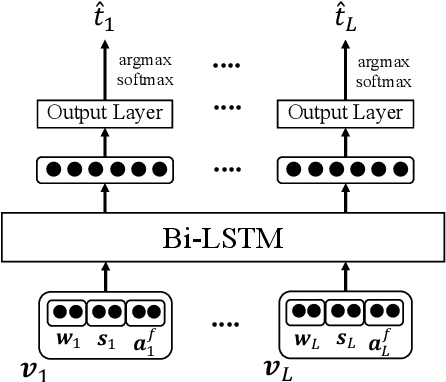
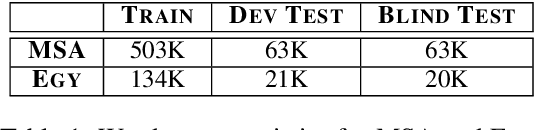
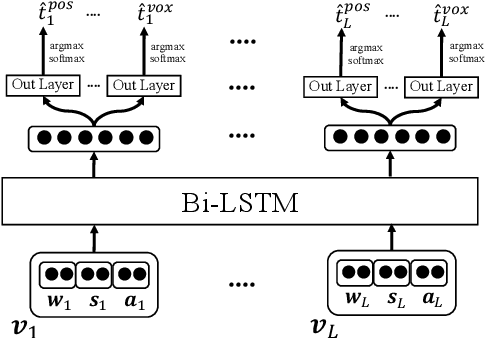
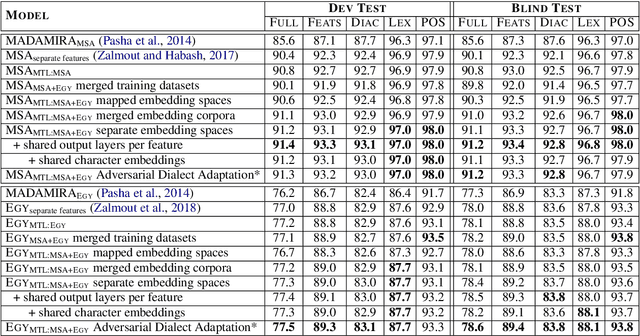
Morphological tagging is challenging for morphologically rich languages due to the large target space and the need for more training data to minimize model sparsity. Dialectal variants of morphologically rich languages suffer more as they tend to be more noisy and have less resources. In this paper we explore the use of multitask learning and adversarial training to address morphological richness and dialectal variations in the context of full morphological tagging. We use multitask learning for joint morphological modeling for the features within two dialects, and as a knowledge-transfer scheme for cross-dialectal modeling. We use adversarial training to learn dialect invariant features that can help the knowledge-transfer scheme from the high to low-resource variants. We work with two dialectal variants: Modern Standard Arabic (high-resource "dialect") and Egyptian Arabic (low-resource dialect) as a case study. Our models achieve state-of-the-art results for both. Furthermore, adversarial training provides more significant improvement when using smaller training datasets in particular.
Joint Diacritization, Lemmatization, Normalization, and Fine-Grained Morphological Tagging
Oct 05, 2019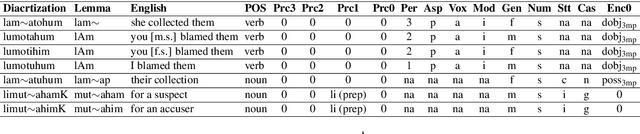
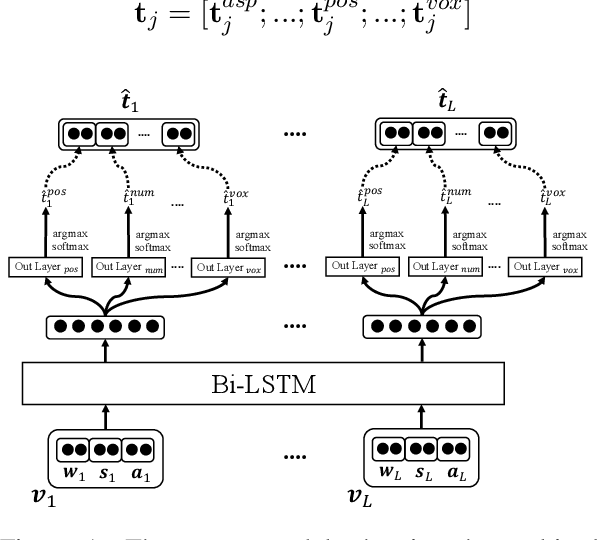


Semitic languages can be highly ambiguous, having several interpretations of the same surface forms, and morphologically rich, having many morphemes that realize several morphological features. This is further exacerbated for dialectal content, which is more prone to noise and lacks a standard orthography. The morphological features can be lexicalized, like lemmas and diacritized forms, or non-lexicalized, like gender, number, and part-of-speech tags, among others. Joint modeling of the lexicalized and non-lexicalized features can identify more intricate morphological patterns, which provide better context modeling, and further disambiguate ambiguous lexical choices. However, the different modeling granularity can make joint modeling more difficult. Our approach models the different features jointly, whether lexicalized (on the character-level), where we also model surface form normalization, or non-lexicalized (on the word-level). We use Arabic as a test case, and achieve state-of-the-art results for Modern Standard Arabic, with 20% relative error reduction, and Egyptian Arabic (a dialectal variant of Arabic), with 11% reduction.