 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-efficient Crowdsourcing for Span-based Sequence Labeling: Worker Selection and Data Augmentation
Paper and Code
May 11, 2023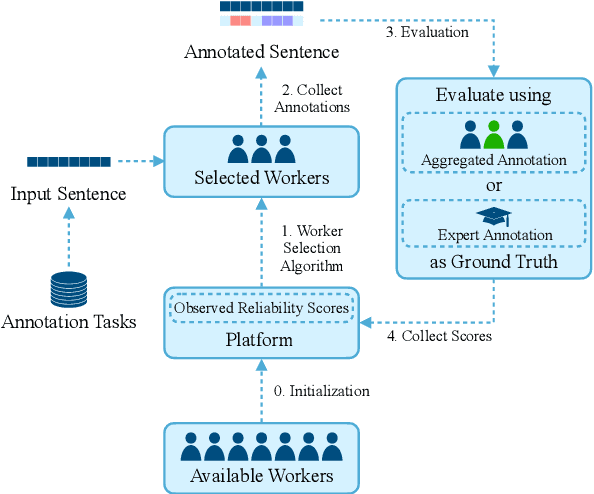

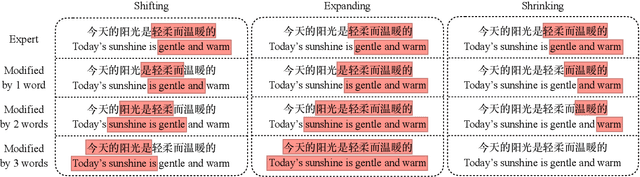
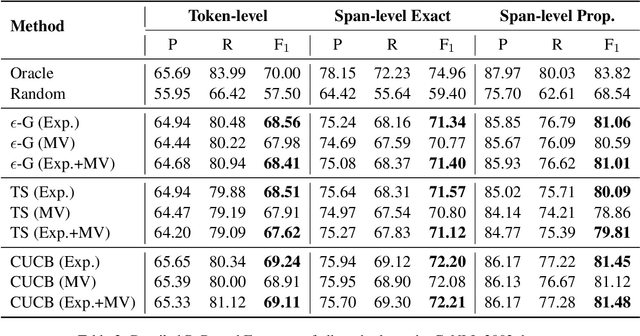
This paper introduces a novel worker selection algorithm, enhancing annotation quality and reducing costs in challenging span-based sequence labeling tasks in Natural Language Processing (NLP). Unlike previous studies targeting simpler tasks, this study contends with the complexities of label interdependencies in sequence labeling tasks. The proposed algorithm utilizes a Combinatorial Multi-Armed Bandit (CMAB) approach for worker selection. The challenge of dealing with imbalanced and small-scale datasets, which hinders offline simulation of worker selection, is tackled using an innovative data augmentation method termed shifting, expanding, and shrinking (SES). The SES method is designed specifically for sequence labeling tasks. Rigorous testing on CoNLL 2003 NER and Chinese OEI datasets showcased the algorithm's efficiency, with an increase in F1 score up to 100.04% of the expert-only baseline, alongside cost savings up to 65.97%. The paper also encompasses a dataset-independent test emulating annotation evaluation through a Bernoulli distribution, which still led to an impressive 97.56% F1 score of the expert baseline and 59.88% cost savings. This research addresses and overcomes numerous obstacles in worker selection for complex NLP tasks.