 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemixFusion: Residual-based Mixed Representation for Large-scale Online RGB-D Reconstruction
Jul 23, 2025The introduction of the neural implicit representation has notably propelled the advancement of online dense reconstruction techniques. Compared to traditional explicit representations, such as TSDF, it improves the mapping completeness and memory efficiency. However, the lack of reconstruction details and the time-consuming learning of neural representations hinder the widespread application of neural-based methods to large-scale online reconstruction. We introduce RemixFusion, a novel residual-based mixed representation for scene reconstruction and camera pose estimation dedicated to high-quality and large-scale online RGB-D reconstruction. In particular, we propose a residual-based map representation comprised of an explicit coarse TSDF grid and an implicit neural module that produces residuals representing fine-grained details to be added to the coarse grid. Such mixed representation allows for detail-rich reconstruction with bounded time and memory budget, contrasting with the overly-smoothed results by the purely implicit representations, thus paving the way for high-quality camera tracking. Furthermore, we extend the residual-based representation to handle multi-frame joint pose optimization via bundle adjustment (BA). In contrast to the existing methods, which optimize poses directly, we opt to optimize pose changes. Combined with a novel technique for adaptive gradient amplification, our method attains better optimization convergence and global optimality. Furthermore, we adopt a local moving volume to factorize the mixed scene representation with a divide-and-conquer design to facilitate efficient online learning in our residual-based framework. Extensive experiments demonstrate that our method surpasses all state-of-the-art ones, including those based either on explicit or implicit representations, in terms of the accuracy of both mapping and tracking on large-scale scenes.
BoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.
EMRA-proxy: Enhancing Multi-Class Region Semantic Segmentation in Remote Sensing Images with Attention Proxy
May 23, 2025High-resolution remote sensing (HRRS) image segmentation is challenging due to complex spatial layouts and diverse object appearances. While CNNs excel at capturing local features, they struggle with long-range dependencies, whereas Transformers can model global context but often neglect local details and are computationally expensive.We propose a novel approach, Region-Aware Proxy Network (RAPNet), which consists of two components: Contextual Region Attention (CRA) and Global Class Refinement (GCR). Unlike traditional methods that rely on grid-based layouts, RAPNet operates at the region level for more flexible segmentation. The CRA module uses a Transformer to capture region-level contextual dependencies, generating a Semantic Region Mask (SRM). The GCR module learns a global class attention map to refine multi-class information, combining the SRM and attention map for accurate segmentation.Experiments on three public datasets show that RAPNet outperforms state-of-the-art methods, achieving superior multi-class segmentation accuracy.
OnlineAnySeg: Online Zero-Shot 3D Segmentation by Visual Foundation Model Guided 2D Mask Merging
Mar 03, 2025Online 3D open-vocabulary segmentation of a progressively reconstructed scene is both a critical and challenging task for embodied applications. With the success of visual foundation models (VFMs) in the image domain, leveraging 2D priors to address 3D online segmentation has become a prominent research focus. Since segmentation results provided by 2D priors often require spatial consistency to be lifted into final 3D segmentation, an efficient method for identifying spatial overlap among 2D masks is essential - yet existing methods rarely achieve this in real time, mainly limiting its use to offline approaches. To address this, we propose an efficient method that lifts 2D masks generated by VFMs into a unified 3D instance using a hashing technique. By employing voxel hashing for efficient 3D scene querying, our approach reduces the time complexity of costly spatial overlap queries from $O(n^2)$ to $O(n)$. Accurate spatial associations further enable 3D merging of 2D masks through simple similarity-based filtering in a zero-shot manner, making our approach more robust to incomplete and noisy data. Evaluated on the ScanNet and SceneNN benchmarks, our approach achieves state-of-the-art performance in online, open-vocabulary 3D instance segmentation with leading efficiency.
LLM-enhanced Scene Graph Learning for Household Rearrangement
Aug 22, 2024



The household rearrangement task involves spotting misplaced objects in a scene and accommodate them with proper places. It depends both on common-sense knowledge on the objective side and human user preference on the subjective side. In achieving such task, we propose to mine object functionality with user preference alignment directly from the scene itself, without relying on human intervention. To do so, we work with scene graph representation and propose LLM-enhanced scene graph learning which transforms the input scene graph into an affordance-enhanced graph (AEG) with information-enhanced nodes and newly discovered edges (relations). In AEG, the nodes corresponding to the receptacle objects are augmented with context-induced affordance which encodes what kind of carriable objects can be placed on it. New edges are discovered with newly discovered non-local relations. With AEG, we perform task planning for scene rearrangement by detecting misplaced carriables and determining a proper placement for each of them. We test our method by implementing a tiding robot in simulator and perform evaluation on a new benchmark we build. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on misplacement detection and the following rearrangement planning.
Multi-Evidence based Fact Verification via A Confidential Graph Neural Network
May 17, 2024



Fact verification tasks aim to identify the integrity of textual contents according to the truthful corpus. Existing fact verification models usually build a fully connected reasoning graph, which regards claim-evidence pairs as nodes and connects them with edges. They employ the graph to propagate the semantics of the nodes. Nevertheless, the noisy nodes usually propagate their semantics via the edges of the reasoning graph, which misleads the semantic representations of other nodes and amplifies the noise signals. To mitigate the propagation of noisy semantic information, we introduce a Confidential Graph Attention Network (CO-GAT), which proposes a node masking mechanism for modeling the nodes. Specifically, CO-GAT calculates the node confidence score by estimating the relevance between the claim and evidence pieces. Then, the node masking mechanism uses the node confidence scores to control the noise information flow from the vanilla node to the other graph nodes. CO-GAT achieves a 73.59% FEVER score on the FEVER dataset and shows the generalization ability by broadening the effectiveness to the science-specific domain.
DisARM: Displacement Aware Relation Module for 3D Detection
Mar 02, 2022
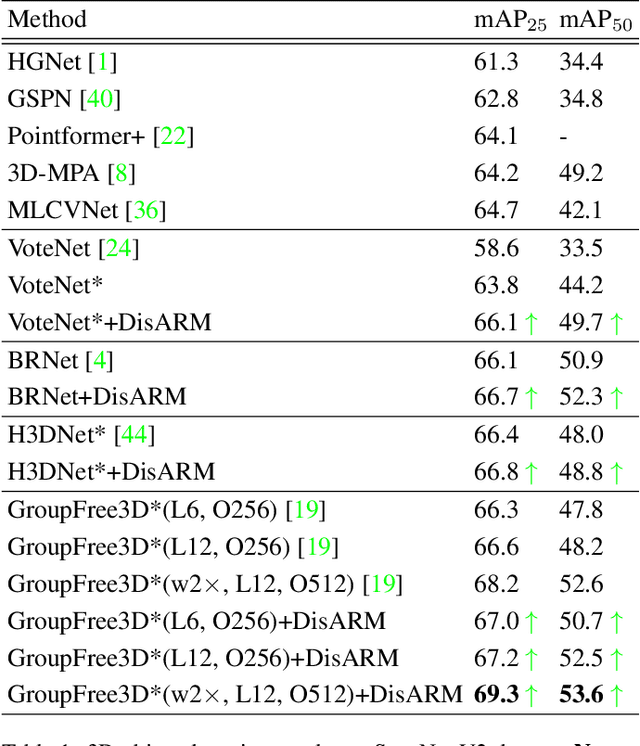
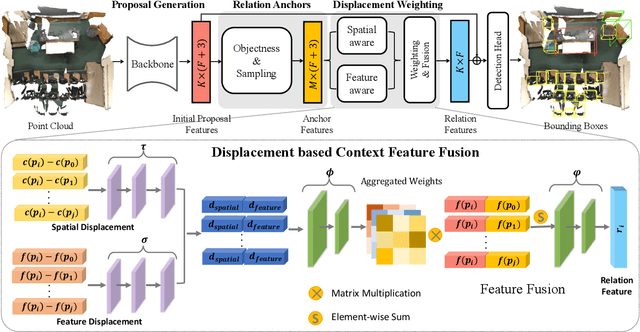
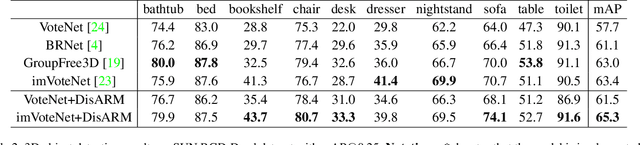
We introduce Displacement Aware Relation Module (DisARM), a novel neural network module for enhancing the performance of 3D object detection in point cloud scenes. The core idea of our method is that contextual information is critical to tell the difference when the instance geometry is incomplete or featureless. We find that relations between proposals provide a good representation to describe the context. However, adopting relations between all the object or patch proposals for detection is inefficient, and an imbalanced combination of local and global relations brings extra noise that could mislead the training. Rather than working with all relations, we found that training with relations only between the most representative ones, or anchors, can significantly boost the detection performance. A good anchor should be semantic-aware with no ambiguity and independent with other anchors as well. To find the anchors, we first perform a preliminary relation anchor module with an objectness-aware sampling approach and then devise a displacement-based module for weighing the relation importance for better utilization of contextual information. This lightweight relation module leads to significantly higher accuracy of object instance detection when being plugged into the state-of-the-art detectors. Evaluations on the public benchmarks of real-world scenes show that our method achieves state-of-the-art performance on both SUN RGB-D and ScanNet V2.
3DRM:Pair-wise relation module for 3D object detection
Feb 20, 2022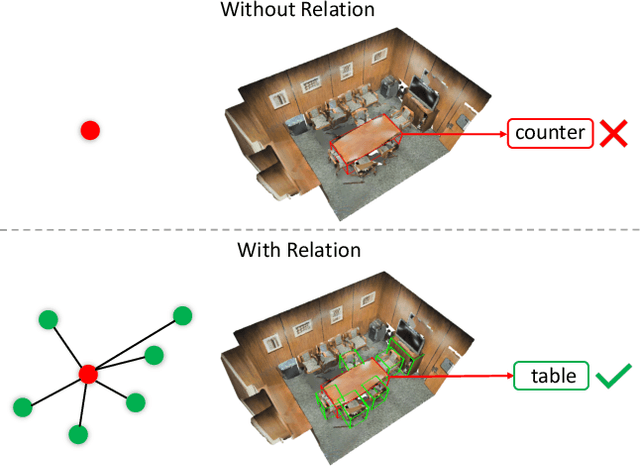
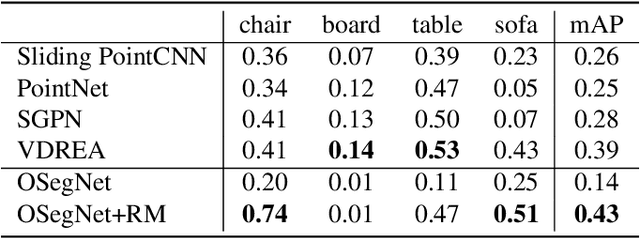
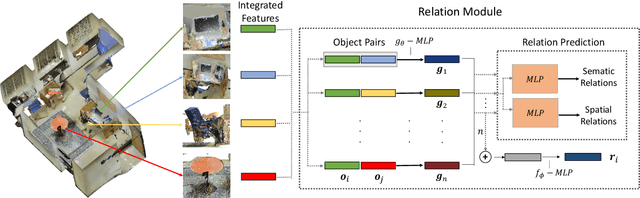
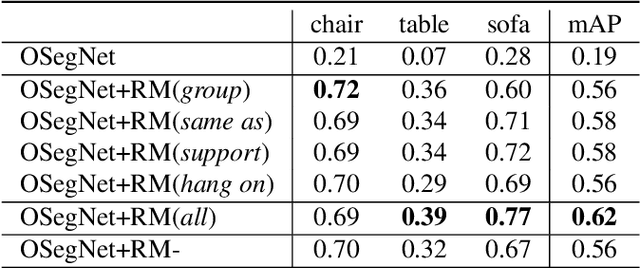
Context has proven to be one of the most important factors in object layout reasoning for 3D scene understanding. Existing deep contextual models either learn holistic features for context encoding or rely on pre-defined scene templates for context modeling. We argue that scene understanding benefits from object relation reasoning, which is capable of mitigating the ambiguity of 3D object detections and thus helps locate and classify the 3D objects more accurately and robustly. To achieve this, we propose a novel 3D relation module (3DRM) which reasons about object relations at pair-wise levels. The 3DRM predicts the semantic and spatial relationships between objects and extracts the object-wise relation features. We demonstrate the effects of 3DRM by plugging it into proposal-based and voting-based 3D object detection pipelines, respectively. Extensive evaluations show the effectiveness and generalization of 3DRM on 3D object detection. Our source code is available at https://github.com/lanlan96/3DRM.
* 13 pages, 8 figures
ARM3D: Attention-based relation module for indoor 3D object detection
Feb 20, 2022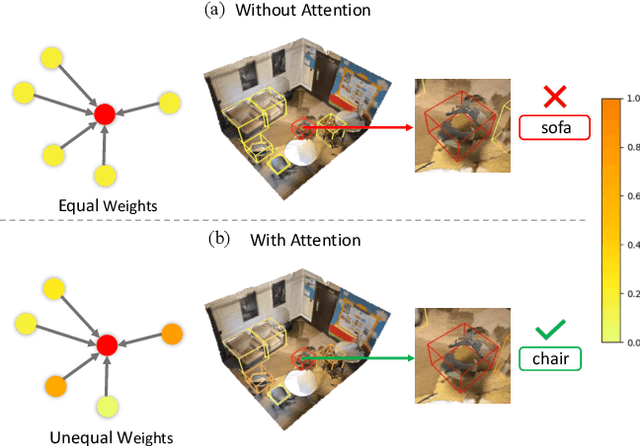

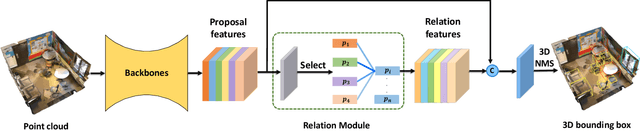
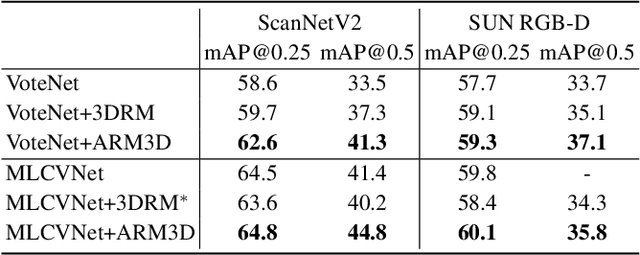
Relation context has been proved to be useful for many challenging vision tasks. In the field of 3D object detection, previous methods have been taking the advantage of context encoding, graph embedding, or explicit relation reasoning to extract relation context. However, there exists inevitably redundant relation context due to noisy or low-quality proposals. In fact, invalid relation context usually indicates underlying scene misunderstanding and ambiguity, which may, on the contrary, reduce the performance in complex scenes. Inspired by recent attention mechanism like Transformer, we propose a novel 3D attention-based relation module (ARM3D). It encompasses object-aware relation reasoning to extract pair-wise relation contexts among qualified proposals and an attention module to distribute attention weights towards different relation contexts. In this way, ARM3D can take full advantage of the useful relation context and filter those less relevant or even confusing contexts, which mitigates the ambiguity in detection. We have evaluated the effectiveness of ARM3D by plugging it into several state-of-the-art 3D object detectors and showing more accurate and robust detection results. Extensive experiments show the capability and generalization of ARM3D on 3D object detection. Our source code is available at https://github.com/lanlan96/ARM3D.