 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAN: Dual-View Representation Learning for Adapting Stance Classifiers to New Domains
Mar 13, 2020
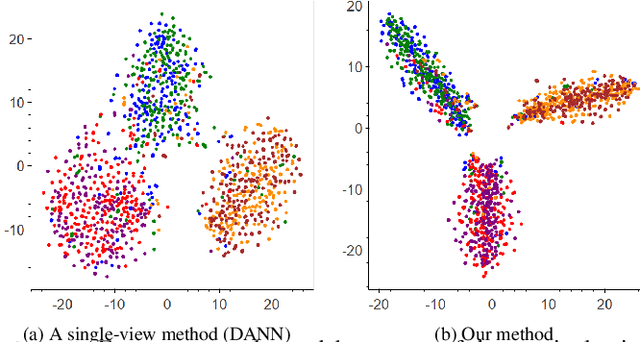
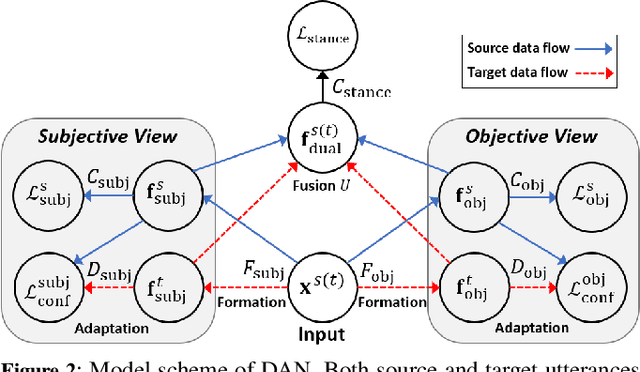
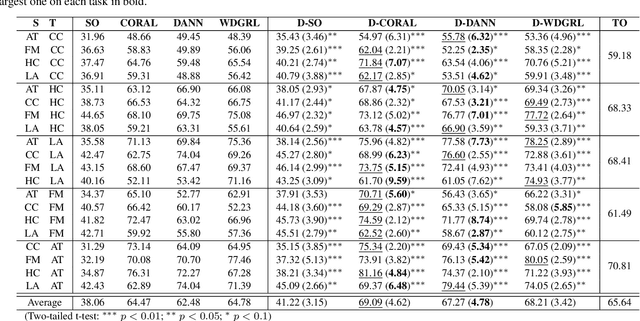
We address the issue of having a limited number of annotations for stance classification in a new domain, by adapting out-of-domain classifiers with domain adaptation. Existing approaches often align different domains in a single, global feature space (or view), which may fail to fully capture the richness of the languages used for expressing stances, leading to reduced adaptability on stance data. In this paper, we identify two major types of stance expressions that are linguistically distinct, and we propose a tailored dual-view adaptation network (DAN) to adapt these expressions across domains. The proposed model first learns a separate view for domain transfer in each expression channel and then selects the best adapted parts of both views for optimal transfer. We find that the learned view features can be more easily aligned and more stance-discriminative in either or both views, leading to more transferable overall features after combining the views. Results from extensive experiments show that our method can enhance the state-of-the-art single-view methods in matching stance data across different domains, and that it consistently improves those methods on various adaptation tasks.
Figurative Usage Detection of Symptom Words to Improve Personal Health Mention Detection
Jul 04, 2019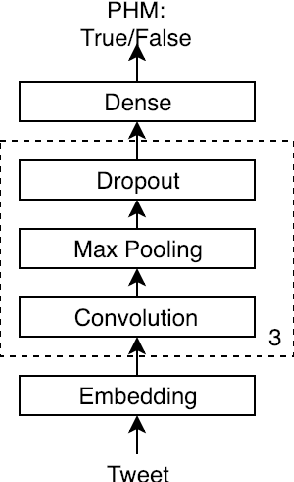

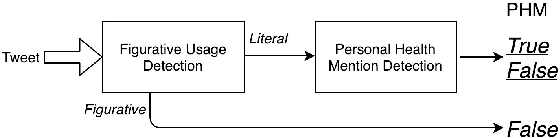
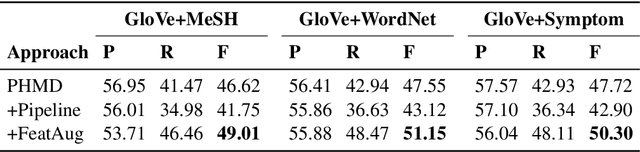
Personal health mention detection deals with predicting whether or not a given sentence is a report of a health condition. Past work mentions errors in this prediction when symptom words, i.e. names of symptoms of interest, are used in a figurative sense. Therefore, we combine a state-of-the-art figurative usage detection with CNN-based personal health mention detection. To do so, we present two methods: a pipeline-based approach and a feature augmentation-based approach. The introduction of figurative usage detection results in an average improvement of 2.21% F-score of personal health mention detection, in the case of the feature augmentation-based approach. This paper demonstrates the promise of using figurative usage detection to improve personal health mention detection.
A Comparison of Word-based and Context-based Representations for Classification Problems in Health Informatics
Jun 13, 2019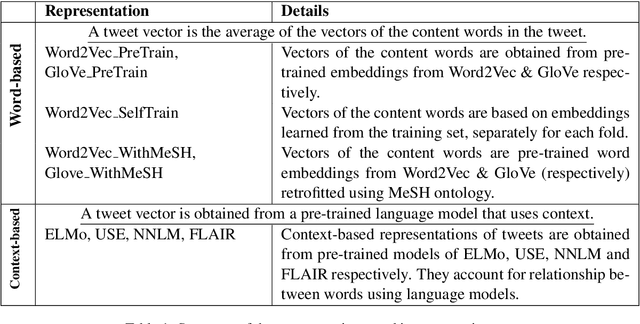
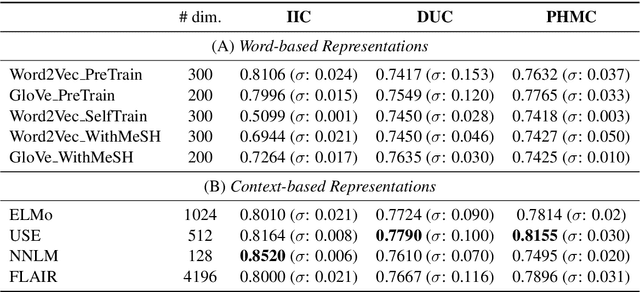

Distributed representations of text can be used as features when training a statistical classifier. These representations may be created as a composition of word vectors or as context-based sentence vectors. We compare the two kinds of representations (word versus context) for three classification problems: influenza infection classification, drug usage classification and personal health mention classification. For statistical classifiers trained for each of these problems, context-based representations based on ELMo, Universal Sentence Encoder, Neural-Net Language Model and FLAIR are better than Word2Vec, GloVe and the two adapted using the MESH ontology. There is an improvement of 2-4% in the accuracy when these context-based representations are used instead of word-based representations.
Recognising Agreement and Disagreement between Stances with Reason Comparing Networks
Jun 04, 2019
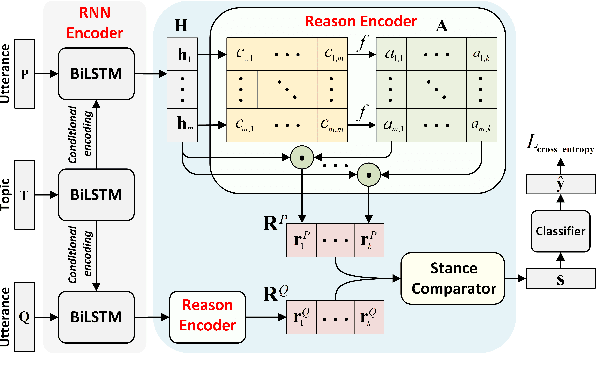


We identify agreement and disagreement between utterances that express stances towards a topic of discussion. Existing methods focus mainly on conversational settings, where dialogic features are used for (dis)agreement inference. We extend this scope and seek to detect stance (dis)agreement in a broader setting, where independent stance-bearing utterances, which prevail in many stance corpora and real-world scenarios, are compared. To cope with such non-dialogic utterances, we find that the reasons uttered to back up a specific stance can help predict stance (dis)agreements. We propose a reason comparing network (RCN) to leverage reason information for stance comparison. Empirical results on a well-known stance corpus show that our method can discover useful reason information, enabling it to outperform several baselines in stance (dis)agreement detection.
Survey of Text-based Epidemic Intelligence: A Computational Linguistic Perspective
Mar 14, 2019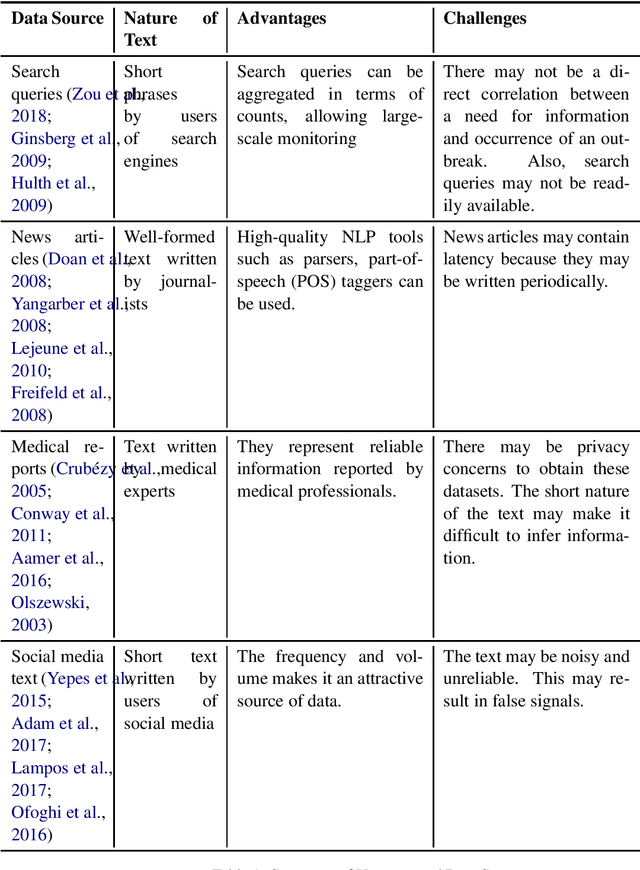
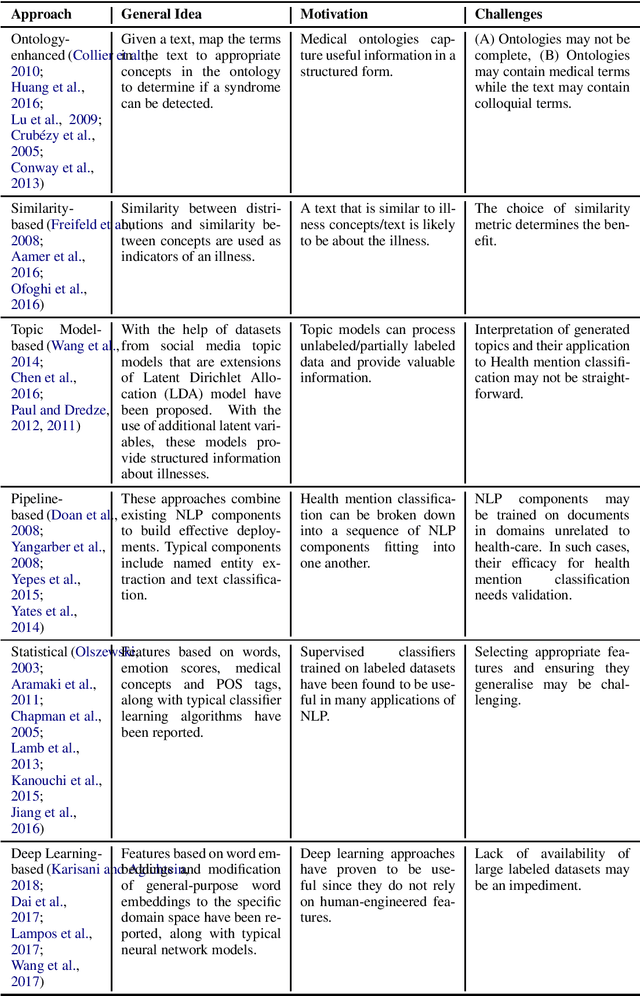

Epidemic intelligence deals with the detection of disease outbreaks using formal (such as hospital records) and informal sources (such as user-generated text on the web) of information. In this survey, we discuss approaches for epidemic intelligence that use textual datasets, referring to it as `text-based epidemic intelligence'. We view past work in terms of two broad categories: health mention classification (selecting relevant text from a large volume) and health event detection (predicting epidemic events from a collection of relevant text). The focus of our discussion is the underlying computational linguistic techniques in the two categories. The survey also provides details of the state-of-the-art in annotation techniques, resources and evaluation strategies for epidemic intelligence.
Cross-Target Stance Classification with Self-Attention Networks
Jul 11, 2018



In stance classification, the target on which the stance is made defines the boundary of the task, and a classifier is usually trained for prediction on the same target. In this work, we explore the potential for generalizing classifiers between different targets, and propose a neural model that can apply what has been learned from a source target to a destination target. We show that our model can find useful information shared between relevant targets which improves generalization in certain scenarios.