 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction from News Articles : A Tool for Epidemic Surveillance
Oct 31, 2023Relation Extraction from News Articles (RENA) is a browser-based tool designed to extract key entities and their semantic relationships in English language news articles related to infectious diseases. Constructed using the React framework, this system presents users with an elegant and user-friendly interface. It enables users to input a news article and select from a choice of two models to generate a comprehensive list of relations within the provided text. As a result, RENA allows real-time parsing of news articles to extract key information for epidemic surveillance, contributing to EPIWATCH, an open-source intelligence-based epidemic warning system.
A Comparison of Word-based and Context-based Representations for Classification Problems in Health Informatics
Jun 13, 2019
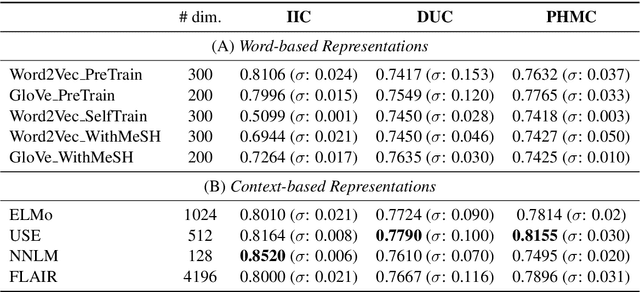

Distributed representations of text can be used as features when training a statistical classifier. These representations may be created as a composition of word vectors or as context-based sentence vectors. We compare the two kinds of representations (word versus context) for three classification problems: influenza infection classification, drug usage classification and personal health mention classification. For statistical classifiers trained for each of these problems, context-based representations based on ELMo, Universal Sentence Encoder, Neural-Net Language Model and FLAIR are better than Word2Vec, GloVe and the two adapted using the MESH ontology. There is an improvement of 2-4% in the accuracy when these context-based representations are used instead of word-based representations.
Survey of Text-based Epidemic Intelligence: A Computational Linguistic Perspective
Mar 14, 2019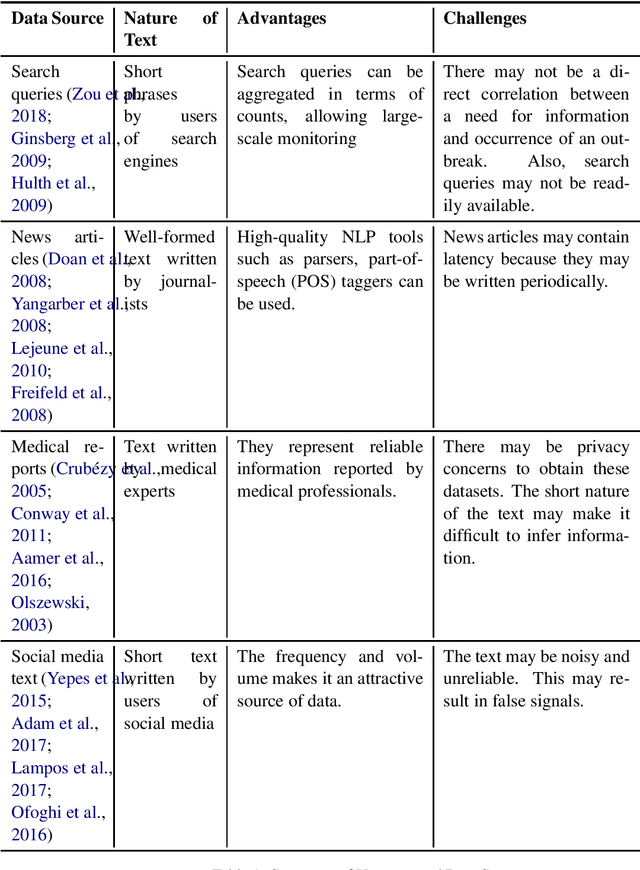
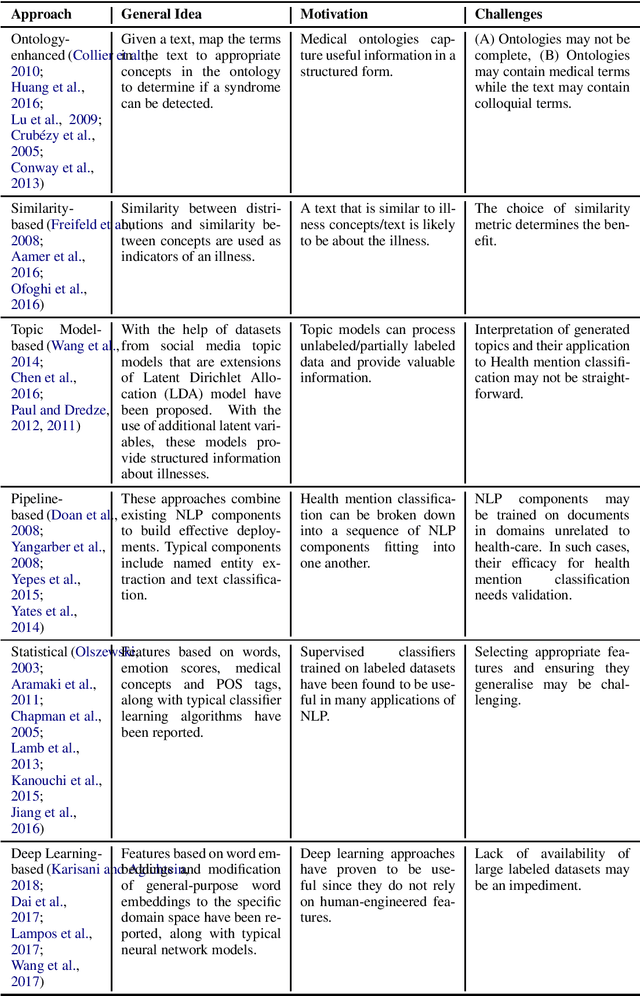

Epidemic intelligence deals with the detection of disease outbreaks using formal (such as hospital records) and informal sources (such as user-generated text on the web) of information. In this survey, we discuss approaches for epidemic intelligence that use textual datasets, referring to it as `text-based epidemic intelligence'. We view past work in terms of two broad categories: health mention classification (selecting relevant text from a large volume) and health event detection (predicting epidemic events from a collection of relevant text). The focus of our discussion is the underlying computational linguistic techniques in the two categories. The survey also provides details of the state-of-the-art in annotation techniques, resources and evaluation strategies for epidemic intelligence.