 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient for Robust Markov Decision Processes
Oct 29, 2024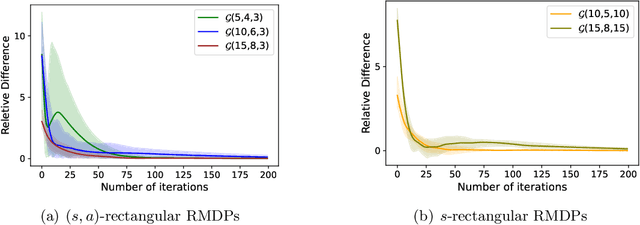
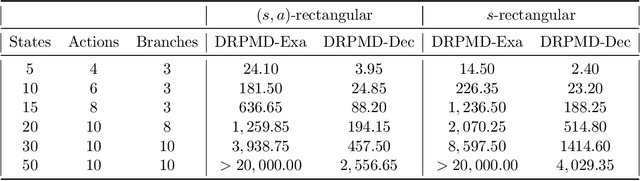
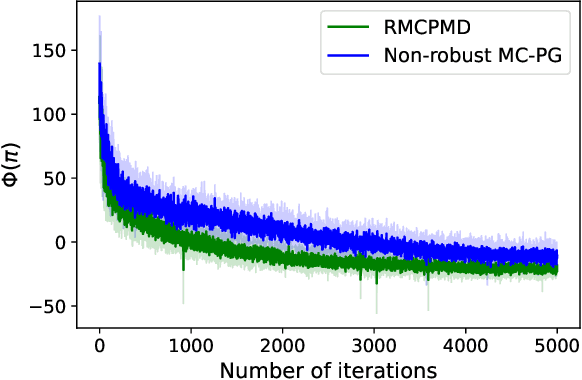
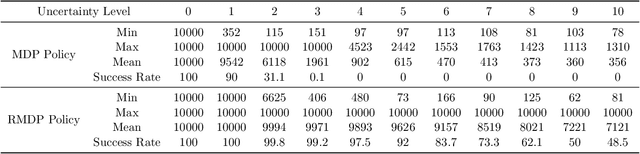
We develop a generic policy gradient method with the global optimality guarantee for robust Markov Decision Processes (MDPs). While policy gradient methods are widely used for solving dynamic decision problems due to their scalable and efficient nature, adapting these methods to account for model ambiguity has been challenging, often making it impractical to learn robust policies. This paper introduces a novel policy gradient method, Double-Loop Robust Policy Mirror Descent (DRPMD), for solving robust MDPs. DRPMD employs a general mirror descent update rule for the policy optimization with adaptive tolerance per iteration, guaranteeing convergence to a globally optimal policy. We provide a comprehensive analysis of DRPMD, including new convergence results under both direct and softmax parameterizations, and provide novel insights into the inner problem solution through Transition Mirror Ascent (TMA). Additionally, we propose innovative parametric transition kernels for both discrete and continuous state-action spaces, broadening the applicability of our approach. Empirical results validate the robustness and global convergence of DRPMD across various challenging robust MDP settings.