 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutocorrelated Optimize-via-Estimate: Predict-then-Optimize versus Finite-sample Optimal
Feb 02, 2026Models that directly optimize for out-of-sample performance in the finite-sample regime have emerged as a promising alternative to traditional estimate-then-optimize approaches in data-driven optimization. In this work, we compare their performance in the context of autocorrelated uncertainties, specifically, under a Vector Autoregressive Moving Average VARMA(p,q) process. We propose an autocorrelated Optimize-via-Estimate (A-OVE) model that obtains an out-of-sample optimal solution as a function of sufficient statistics, and propose a recursive form for computing its sufficient statistics. We evaluate these models on a portfolio optimization problem with trading costs. A-OVE achieves low regret relative to a perfect information oracle, outperforming predict-then-optimize machine learning benchmarks. Notably, machine learning models with higher accuracy can have poorer decision quality, echoing the growing literature in data-driven optimization. Performance is retained under small mis-specification.
Optimize-via-Predict: Realizing out-of-sample optimality in data-driven optimization
Sep 20, 2023


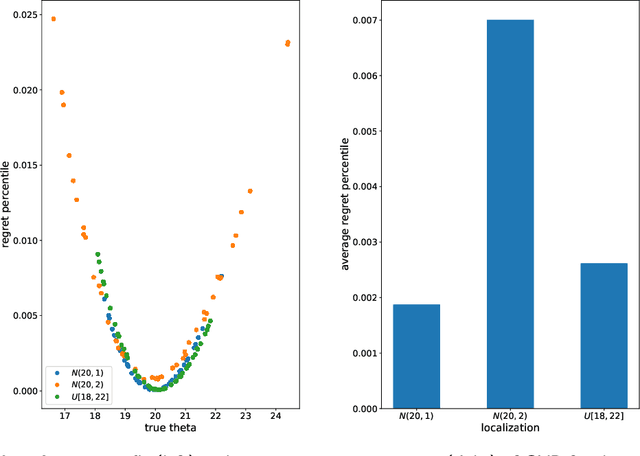
We examine a stochastic formulation for data-driven optimization wherein the decision-maker is not privy to the true distribution, but has knowledge that it lies in some hypothesis set and possesses a historical data set, from which information about it can be gleaned. We define a prescriptive solution as a decision rule mapping such a data set to decisions. As there does not exist prescriptive solutions that are generalizable over the entire hypothesis set, we define out-of-sample optimality as a local average over a neighbourhood of hypotheses, and averaged over the sampling distribution. We prove sufficient conditions for local out-of-sample optimality, which reduces to functions of the sufficient statistic of the hypothesis family. We present an optimization problem that would solve for such an out-of-sample optimal solution, and does so efficiently by a combination of sampling and bisection search algorithms. Finally, we illustrate our model on the newsvendor model, and find strong performance when compared against alternatives in the literature. There are potential implications of our research on end-to-end learning and Bayesian optimization.