 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Is Not Just Ethical: Performance Trade-Off via Data Correlation Tuning to Mitigate Bias in ML Software
Dec 19, 2025Traditional software fairness research typically emphasizes ethical and social imperatives, neglecting that fairness fundamentally represents a core software quality issue arising directly from performance disparities across sensitive user groups. Recognizing fairness explicitly as a software quality dimension yields practical benefits beyond ethical considerations, notably improved predictive performance for unprivileged groups, enhanced out-of-distribution generalization, and increased geographic transferability in real-world deployments. Nevertheless, existing bias mitigation methods face a critical dilemma: while pre-processing methods offer broad applicability across model types, they generally fall short in effectiveness compared to post-processing techniques. To overcome this challenge, we propose Correlation Tuning (CoT), a novel pre-processing approach designed to mitigate bias by adjusting data correlations. Specifically, CoT introduces the Phi-coefficient, an intuitive correlation measure, to systematically quantify correlation between sensitive attributes and labels, and employs multi-objective optimization to address the proxy biases. Extensive evaluations demonstrate that CoT increases the true positive rate of unprivileged groups by an average of 17.5% and reduces three key bias metrics, including statistical parity difference (SPD), average odds difference (AOD), and equal opportunity difference (EOD), by more than 50% on average. CoT outperforms state-of-the-art methods by three and ten percentage points in single attribute and multiple attributes scenarios, respectively. We will publicly release our experimental results and source code to facilitate future research.
Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
Oct 06, 2025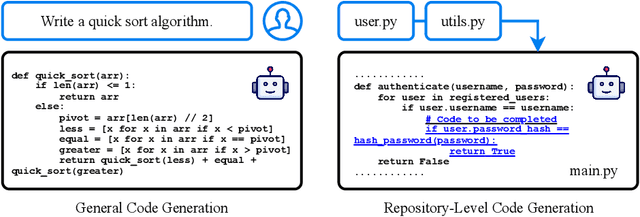

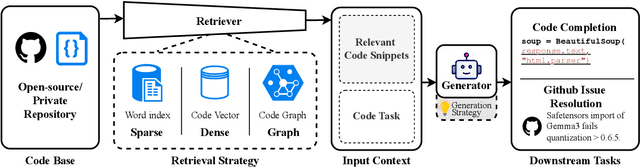
Recent advancements in large language models (LLMs) have substantially improved automated code generation. While function-level and file-level generation have achieved promising results, real-world software development typically requires reasoning across entire repositories. This gives rise to the challenging task of Repository-Level Code Generation (RLCG), where models must capture long-range dependencies, ensure global semantic consistency, and generate coherent code spanning multiple files or modules. To address these challenges, Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm that integrates external retrieval mechanisms with LLMs, enhancing context-awareness and scalability. In this survey, we provide a comprehensive review of research on Retrieval-Augmented Code Generation (RACG), with an emphasis on repository-level approaches. We categorize existing work along several dimensions, including generation strategies, retrieval modalities, model architectures, training paradigms, and evaluation protocols. Furthermore, we summarize widely used datasets and benchmarks, analyze current limitations, and outline key challenges and opportunities for future research. Our goal is to establish a unified analytical framework for understanding this rapidly evolving field and to inspire continued progress in AI-powered software engineering.
Backdoor Attack on Vision Language Models with Stealthy Semantic Manipulation
Jun 08, 2025Vision Language Models (VLMs) have shown remarkable performance, but are also vulnerable to backdoor attacks whereby the adversary can manipulate the model's outputs through hidden triggers. Prior attacks primarily rely on single-modality triggers, leaving the crucial cross-modal fusion nature of VLMs largely unexplored. Unlike prior work, we identify a novel attack surface that leverages cross-modal semantic mismatches as implicit triggers. Based on this insight, we propose BadSem (Backdoor Attack with Semantic Manipulation), a data poisoning attack that injects stealthy backdoors by deliberately misaligning image-text pairs during training. To perform the attack, we construct SIMBad, a dataset tailored for semantic manipulation involving color and object attributes. Extensive experiments across four widely used VLMs show that BadSem achieves over 98% average ASR, generalizes well to out-of-distribution datasets, and can transfer across poisoning modalities. Our detailed analysis using attention visualization shows that backdoored models focus on semantically sensitive regions under mismatched conditions while maintaining normal behavior on clean inputs. To mitigate the attack, we try two defense strategies based on system prompt and supervised fine-tuning but find that both of them fail to mitigate the semantic backdoor. Our findings highlight the urgent need to address semantic vulnerabilities in VLMs for their safer deployment.
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Prompt Injection attack against LLM-integrated Applications
Jun 08, 2023Large Language Models (LLMs), renowned for their superior proficiency in language comprehension and generation, stimulate a vibrant ecosystem of applications around them. However, their extensive assimilation into various services introduces significant security risks. This study deconstructs the complexities and implications of prompt injection attacks on actual LLM-integrated applications. Initially, we conduct an exploratory analysis on ten commercial applications, highlighting the constraints of current attack strategies in practice. Prompted by these limitations, we subsequently formulate HouYi, a novel black-box prompt injection attack technique, which draws inspiration from traditional web injection attacks. HouYi is compartmentalized into three crucial elements: a seamlessly-incorporated pre-constructed prompt, an injection prompt inducing context partition, and a malicious payload designed to fulfill the attack objectives. Leveraging HouYi, we unveil previously unknown and severe attack outcomes, such as unrestricted arbitrary LLM usage and uncomplicated application prompt theft. We deploy HouYi on 36 actual LLM-integrated applications and discern 31 applications susceptible to prompt injection. 10 vendors have validated our discoveries, including Notion, which has the potential to impact millions of users. Our investigation illuminates both the possible risks of prompt injection attacks and the possible tactics for mitigation.
FITNESS: A Causal De-correlation Approach for Mitigating Bias in Machine Learning Software
May 23, 2023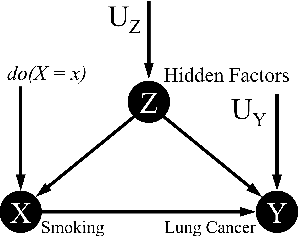

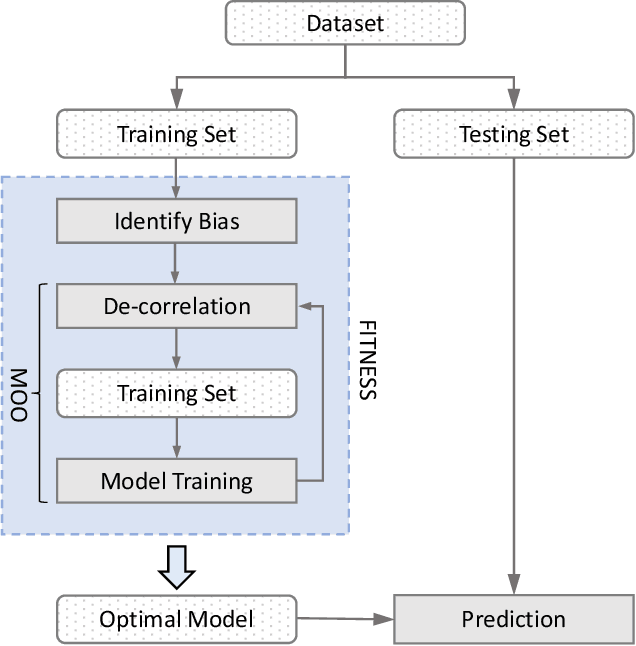
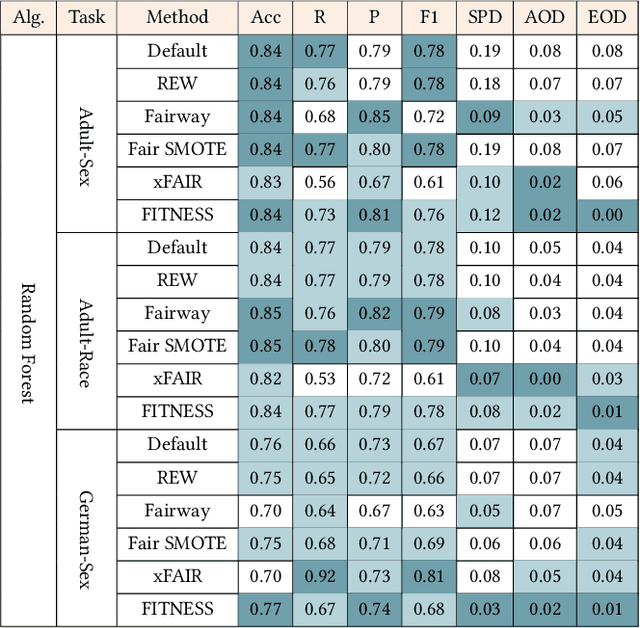
Software built on top of machine learning algorithms is becoming increasingly prevalent in a variety of fields, including college admissions, healthcare, insurance, and justice. The effectiveness and efficiency of these systems heavily depend on the quality of the training datasets. Biased datasets can lead to unfair and potentially harmful outcomes, particularly in such critical decision-making systems where the allocation of resources may be affected. This can exacerbate discrimination against certain groups and cause significant social disruption. To mitigate such unfairness, a series of bias-mitigating methods are proposed. Generally, these studies improve the fairness of the trained models to a certain degree but with the expense of sacrificing the model performance. In this paper, we propose FITNESS, a bias mitigation approach via de-correlating the causal effects between sensitive features (e.g., the sex) and the label. Our key idea is that by de-correlating such effects from a causality perspective, the model would avoid making predictions based on sensitive features and thus fairness could be improved. Furthermore, FITNESS leverages multi-objective optimization to achieve a better performance-fairness trade-off. To evaluate the effectiveness, we compare FITNESS with 7 state-of-the-art methods in 8 benchmark tasks by multiple metrics. Results show that FITNESS can outperform the state-of-the-art methods on bias mitigation while preserve the model's performance: it improved the model's fairness under all the scenarios while decreased the model's performance under only 26.67% of the scenarios. Additionally, FITNESS surpasses the Fairea Baseline in 96.72% cases, outperforming all methods we compared.
Deep Learning for Android Malware Defenses: a Systematic Literature Review
Mar 09, 2021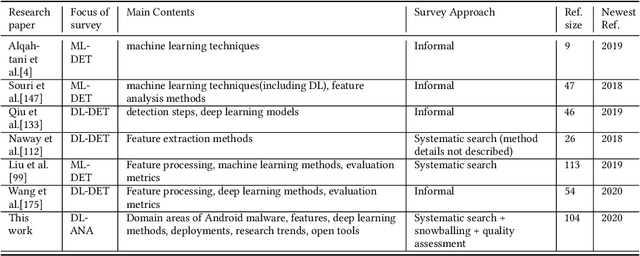
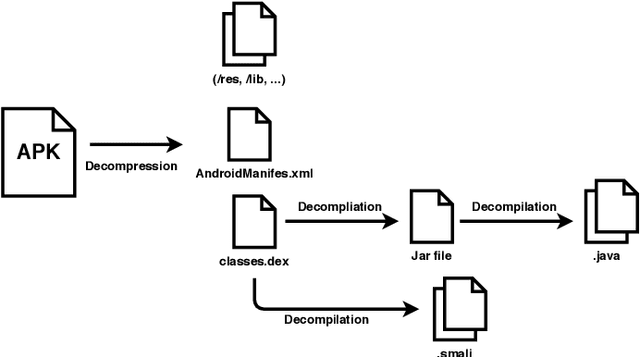

Malicious applications (especially in the Android platform) are a serious threat to developers and end-users. Many research efforts have hence been devoted to developing effective approaches to defend Android malware. However, with the explosive growth of Android malware and the continuous advancement of malicious evasion technologies like obfuscation and reflection, android malware defenses based on manual rules or traditional machine learning may not be effective due to limited apriori knowledge. In recent years, a dominant research field of deep learning (DL) with the powerful feature abstraction ability has demonstrated a compelling and promising performance in various fields, like Nature Language processing and image processing. To this end, employing deep learning techniques to thwart the attack of Android malware has recently gained considerable research attention. Yet, there exists no systematic literature review that focuses on deep learning approaches for Android Malware defenses. In this paper, we conducted a systematic literature review to search and analyze how deep learning approaches have been applied in the context of malware defenses in the Android environment. As a result, a total of 104 studies were identified over the period 2014-2020. The results of our investigation show that even though most of these studies still mainly consider DL-based on Android malware detection, 35 primary studies (33.7\%) design the defenses approaches based on other scenarios. This review also describes research trends, research focuses, challenges, and future research directions in DL-based Android malware defenses.
Testing Deep Learning Models for Image Analysis Using Object-Relevant Metamorphic Relations
Sep 06, 2019
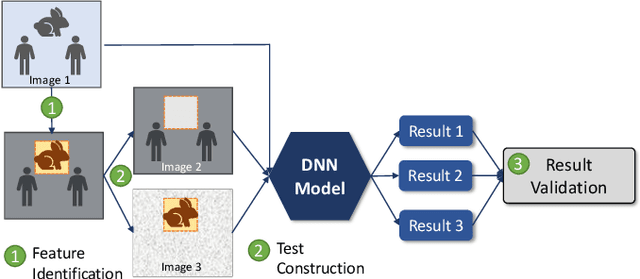
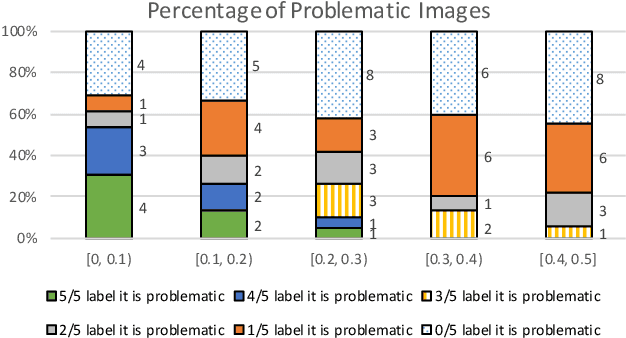
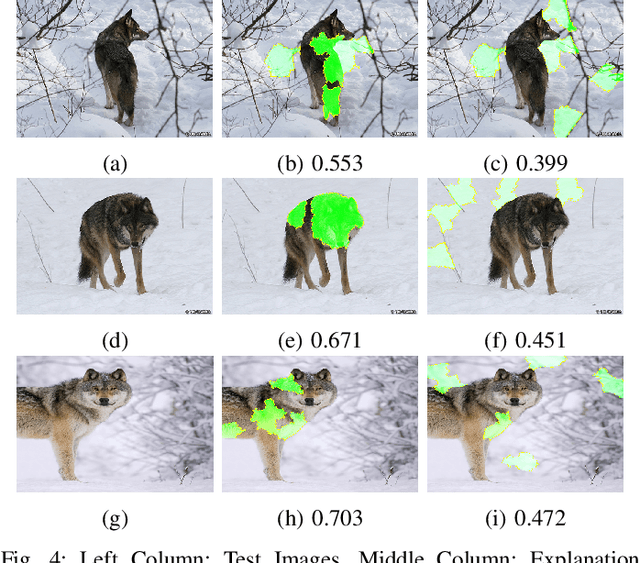
Deep learning models are widely used for image analysis. While they offer high performance in terms of accuracy, people are concerned about if these models inappropriately make inferences using irrelevant features that are not encoded from the target object in a given image. To address the concern, we propose a metamorphic testing approach that assesses if a given inference is made based on irrelevant features. Specifically, we propose two novel metamorphic relations to detect such inappropriate inferences. We applied our approach to 10 image classification models and 10 object detection models, with three large datasets, i.e., ImageNet, COCO, and Pascal VOC. Over 5.3% of the top-5 correct predictions made by the image classification models are subject to inappropriate inferences using irrelevant features. The corresponding rate for the object detection models is over 8.5%. Based on the findings, we further designed a new image generation strategy that can effectively attack existing models. Comparing with a baseline approach, our strategy can double the success rate of attacks.