 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Correcting Label Noise for Robust GNNs via Influence Contradiction
Jan 24, 2026Graph Neural Networks (GNNs) have shown remarkable capabilities in learning from graph-structured data with various applications such as social analysis and bioinformatics. However, the presence of label noise in real scenarios poses a significant challenge in learning robust GNNs, and their effectiveness can be severely impacted when dealing with noisy labels on graphs, often stemming from annotation errors or inconsistencies. To address this, in this paper we propose a novel approach called ICGNN that harnesses the structure information of the graph to effectively alleviate the challenges posed by noisy labels. Specifically, we first design a novel noise indicator that measures the influence contradiction score (ICS) based on the graph diffusion matrix to quantify the credibility of nodes with clean labels, such that nodes with higher ICS values are more likely to be detected as having noisy labels. Then we leverage the Gaussian mixture model to precisely detect whether the label of a node is noisy or not. Additionally, we develop a soft strategy to combine the predictions from neighboring nodes on the graph to correct the detected noisy labels. At last, pseudo-labeling for abundant unlabeled nodes is incorporated to provide auxiliary supervision signals and guide the model optimization. Experiments on benchmark datasets show the superiority of our proposed approach.
Cluster-guided Contrastive Class-imbalanced Graph Classification
Dec 17, 2024



This paper studies the problem of class-imbalanced graph classification, which aims at effectively classifying the categories of graphs in scenarios with imbalanced class distribution. Despite the tremendous success of graph neural networks (GNNs), their modeling ability for imbalanced graph-structured data is inadequate, which typically leads to predictions biased towards the majority classes. Besides, existing class-imbalanced learning methods in visions may overlook the rich graph semantic substructures of the majority classes and excessively emphasize learning from the minority classes. To tackle this issue, this paper proposes a simple yet powerful approach called C$^3$GNN that incorporates the idea of clustering into contrastive learning to enhance class-imbalanced graph classification. Technically, C$^3$GNN clusters graphs from each majority class into multiple subclasses, ensuring they have similar sizes to the minority class, thus alleviating class imbalance. Additionally, it utilizes the Mixup technique to synthesize new samples and enrich the semantic information of each subclass, and leverages supervised contrastive learning to hierarchically learn effective graph representations. In this way, we can not only sufficiently explore the semantic substructures within the majority class but also effectively alleviate excessive focus on the minority class. Extensive experiments on real-world graph benchmark datasets verify the superior performance of our proposed method.
Towards Graph Contrastive Learning: A Survey and Beyond
May 20, 2024



In recent years, deep learning on graphs has achieved remarkable success in various domains. However, the reliance on annotated graph data remains a significant bottleneck due to its prohibitive cost and time-intensive nature. To address this challenge, self-supervised learning (SSL) on graphs has gained increasing attention and has made significant progress. SSL enables machine learning models to produce informative representations from unlabeled graph data, reducing the reliance on expensive labeled data. While SSL on graphs has witnessed widespread adoption, one critical component, Graph Contrastive Learning (GCL), has not been thoroughly investigated in the existing literature. Thus, this survey aims to fill this gap by offering a dedicated survey on GCL. We provide a comprehensive overview of the fundamental principles of GCL, including data augmentation strategies, contrastive modes, and contrastive optimization objectives. Furthermore, we explore the extensions of GCL to other aspects of data-efficient graph learning, such as weakly supervised learning, transfer learning, and related scenarios. We also discuss practical applications spanning domains such as drug discovery, genomics analysis, recommender systems, and finally outline the challenges and potential future directions in this field.
Hypergraph-enhanced Dual Semi-supervised Graph Classification
May 08, 2024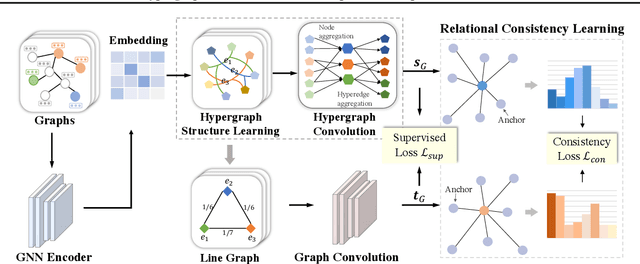
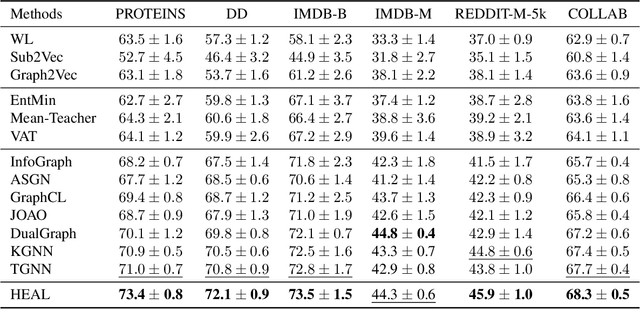
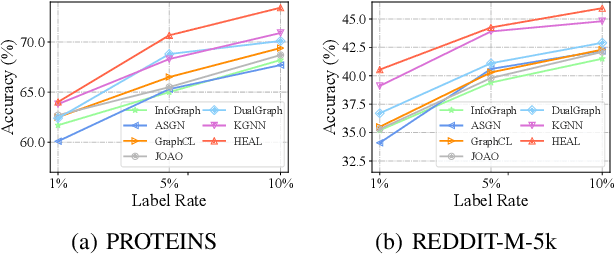
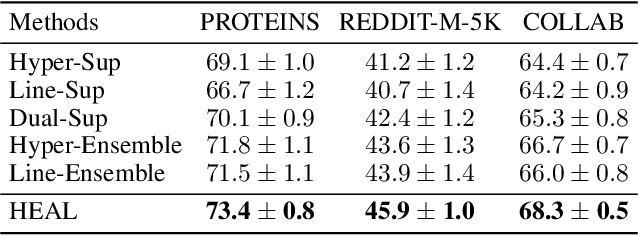
In this paper, we study semi-supervised graph classification, which aims at accurately predicting the categories of graphs in scenarios with limited labeled graphs and abundant unlabeled graphs. Despite the promising capability of graph neural networks (GNNs), they typically require a large number of costly labeled graphs, while a wealth of unlabeled graphs fail to be effectively utilized. Moreover, GNNs are inherently limited to encoding local neighborhood information using message-passing mechanisms, thus lacking the ability to model higher-order dependencies among nodes. To tackle these challenges, we propose a Hypergraph-Enhanced DuAL framework named HEAL for semi-supervised graph classification, which captures graph semantics from the perspective of the hypergraph and the line graph, respectively. Specifically, to better explore the higher-order relationships among nodes, we design a hypergraph structure learning to adaptively learn complex node dependencies beyond pairwise relations. Meanwhile, based on the learned hypergraph, we introduce a line graph to capture the interaction between hyperedges, thereby better mining the underlying semantic structures. Finally, we develop a relational consistency learning to facilitate knowledge transfer between the two branches and provide better mutual guidance. Extensive experiments on real-world graph datasets verify the effectiveness of the proposed method against existing state-of-the-art methods.
A Survey of Graph Neural Networks in Real world: Imbalance, Noise, Privacy and OOD Challenges
Mar 07, 2024Graph-structured data exhibits universality and widespread applicability across diverse domains, such as social network analysis, biochemistry, financial fraud detection, and network security. Significant strides have been made in leveraging Graph Neural Networks (GNNs) to achieve remarkable success in these areas. However, in real-world scenarios, the training environment for models is often far from ideal, leading to substantial performance degradation of GNN models due to various unfavorable factors, including imbalance in data distribution, the presence of noise in erroneous data, privacy protection of sensitive information, and generalization capability for out-of-distribution (OOD) scenarios. To tackle these issues, substantial efforts have been devoted to improving the performance of GNN models in practical real-world scenarios, as well as enhancing their reliability and robustness. In this paper, we present a comprehensive survey that systematically reviews existing GNN models, focusing on solutions to the four mentioned real-world challenges including imbalance, noise, privacy, and OOD in practical scenarios that many existing reviews have not considered. Specifically, we first highlight the four key challenges faced by existing GNNs, paving the way for our exploration of real-world GNN models. Subsequently, we provide detailed discussions on these four aspects, dissecting how these solutions contribute to enhancing the reliability and robustness of GNN models. Last but not least, we outline promising directions and offer future perspectives in the field.
COOL: A Conjoint Perspective on Spatio-Temporal Graph Neural Network for Traffic Forecasting
Mar 02, 2024This paper investigates traffic forecasting, which attempts to forecast the future state of traffic based on historical situations. This problem has received ever-increasing attention in various scenarios and facilitated the development of numerous downstream applications such as urban planning and transportation management. However, the efficacy of existing methods remains sub-optimal due to their tendency to model temporal and spatial relationships independently, thereby inadequately accounting for complex high-order interactions of both worlds. Moreover, the diversity of transitional patterns in traffic forecasting makes them challenging to capture for existing approaches, warranting a deeper exploration of their diversity. Toward this end, this paper proposes Conjoint Spatio-Temporal graph neural network (abbreviated as COOL), which models heterogeneous graphs from prior and posterior information to conjointly capture high-order spatio-temporal relationships. On the one hand, heterogeneous graphs connecting sequential observation are constructed to extract composite spatio-temporal relationships via prior message passing. On the other hand, we model dynamic relationships using constructed affinity and penalty graphs, which guide posterior message passing to incorporate complementary semantic information into node representations. Moreover, to capture diverse transitional properties to enhance traffic forecasting, we propose a conjoint self-attention decoder that models diverse temporal patterns from both multi-rank and multi-scale views. Experimental results on four popular benchmark datasets demonstrate that our proposed COOL provides state-of-the-art performance compared with the competitive baselines.
A Survey of Data-Efficient Graph Learning
Feb 01, 2024Graph-structured data, prevalent in domains ranging from social networks to biochemical analysis, serve as the foundation for diverse real-world systems. While graph neural networks demonstrate proficiency in modeling this type of data, their success is often reliant on significant amounts of labeled data, posing a challenge in practical scenarios with limited annotation resources. To tackle this problem, tremendous efforts have been devoted to enhancing graph machine learning performance under low-resource settings by exploring various approaches to minimal supervision. In this paper, we introduce a novel concept of Data-Efficient Graph Learning (DEGL) as a research frontier, and present the first survey that summarizes the current progress of DEGL. We initiate by highlighting the challenges inherent in training models with large labeled data, paving the way for our exploration into DEGL. Next, we systematically review recent advances on this topic from several key aspects, including self-supervised graph learning, semi-supervised graph learning, and few-shot graph learning. Also, we state promising directions for future research, contributing to the evolution of graph machine learning.
Towards Long-Tailed Recognition for Graph Classification via Collaborative Experts
Sep 05, 2023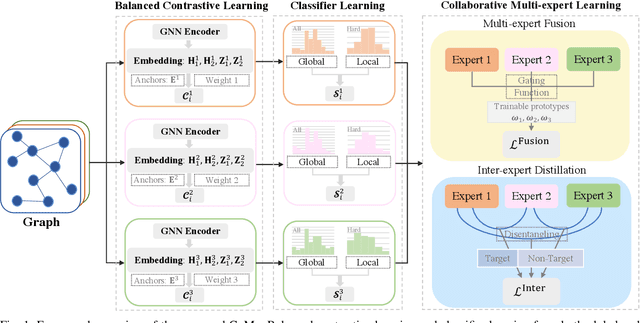
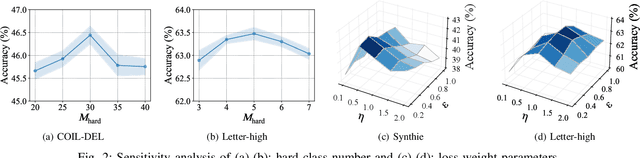
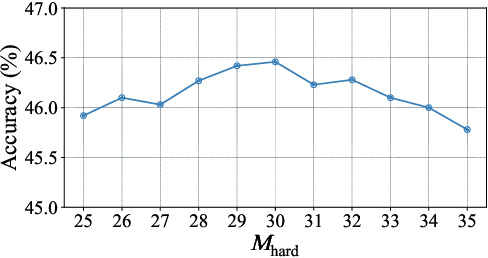
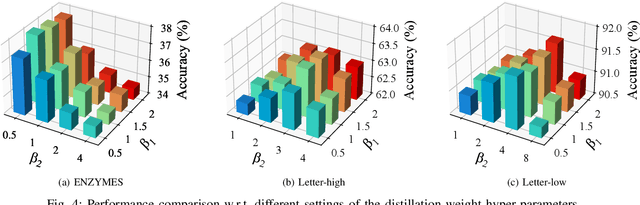
Graph classification, aiming at learning the graph-level representations for effective class assignments, has received outstanding achievements, which heavily relies on high-quality datasets that have balanced class distribution. In fact, most real-world graph data naturally presents a long-tailed form, where the head classes occupy much more samples than the tail classes, it thus is essential to study the graph-level classification over long-tailed data while still remaining largely unexplored. However, most existing long-tailed learning methods in visions fail to jointly optimize the representation learning and classifier training, as well as neglect the mining of the hard-to-classify classes. Directly applying existing methods to graphs may lead to sub-optimal performance, since the model trained on graphs would be more sensitive to the long-tailed distribution due to the complex topological characteristics. Hence, in this paper, we propose a novel long-tailed graph-level classification framework via Collaborative Multi-expert Learning (CoMe) to tackle the problem. To equilibrate the contributions of head and tail classes, we first develop balanced contrastive learning from the view of representation learning, and then design an individual-expert classifier training based on hard class mining. In addition, we execute gated fusion and disentangled knowledge distillation among the multiple experts to promote the collaboration in a multi-expert framework. Comprehensive experiments are performed on seven widely-used benchmark datasets to demonstrate the superiority of our method CoMe over state-of-the-art baselines.