 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Data Compression: Challenges and Opportunities for the Future
Dec 14, 2024



Compressing integer keys is a fundamental operation among multiple communities, such as database management (DB), information retrieval (IR), and high-performance computing (HPC). Recent advances in \emph{learned indexes} have inspired the development of \emph{learned compressors}, which leverage simple yet compact machine learning (ML) models to compress large-scale sorted keys. The core idea behind learned compressors is to \emph{losslessly} encode sorted keys by approximating them with \emph{error-bounded} ML models (e.g., piecewise linear functions) and using a \emph{residual array} to guarantee accurate key reconstruction. While the concept of learned compressors remains in its early stages of exploration, our benchmark results demonstrate that an SIMD-optimized learned compressor can significantly outperform state-of-the-art CPU-based compressors. Drawing on our preliminary experiments, this vision paper explores the potential of learned data compression to enhance critical areas in DBMS and related domains. Furthermore, we outline the key technical challenges that existing systems must address when integrating this emerging methodology.
Predicting Liquidity Coverage Ratio with Gated Recurrent Units: A Deep Learning Model for Risk Management
Oct 24, 2024

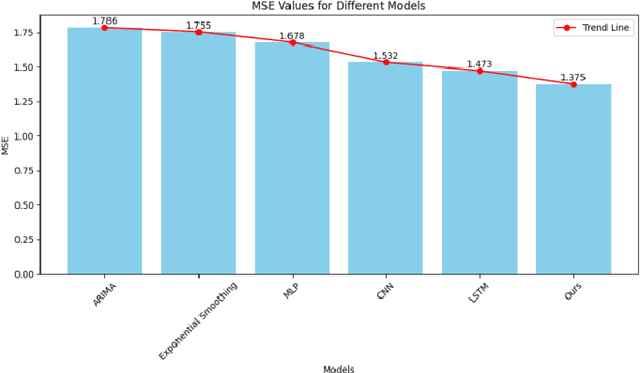

With the global economic integration and the high interconnection of financial markets, financial institutions are facing unprecedented challenges, especially liquidity risk. This paper proposes a liquidity coverage ratio (LCR) prediction model based on the gated recurrent unit (GRU) network to help financial institutions manage their liquidity risk more effectively. By utilizing the GRU network in deep learning technology, the model can automatically learn complex patterns from historical data and accurately predict LCR for a period of time in the future. The experimental results show that compared with traditional methods, the GRU model proposed in this study shows significant advantages in mean absolute error (MAE), proving its higher accuracy and robustness. This not only provides financial institutions with a more reliable liquidity risk management tool but also provides support for regulators to formulate more scientific and reasonable policies, which helps to improve the stability of the entire financial system.
Wasserstein Distance-Weighted Adversarial Network for Cross-Domain Credit Risk Assessment
Sep 27, 2024


This paper delves into the application of adversarial domain adaptation (ADA) for enhancing credit risk assessment in financial institutions. It addresses two critical challenges: the cold start problem, where historical lending data is scarce, and the data imbalance issue, where high-risk transactions are underrepresented. The paper introduces an improved ADA framework, the Wasserstein Distance Weighted Adversarial Domain Adaptation Network (WD-WADA), which leverages the Wasserstein distance to align source and target domains effectively. The proposed method includes an innovative weighted strategy to tackle data imbalance, adjusting for both the class distribution and the difficulty level of predictions. The paper demonstrates that WD-WADA not only mitigates the cold start problem but also provides a more accurate measure of domain differences, leading to improved cross-domain credit risk assessment. Extensive experiments on real-world credit datasets validate the model's effectiveness, showcasing superior performance in cross-domain learning, classification accuracy, and model stability compared to traditional methods.