 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Alleviating Behavior Data Imbalance for Multi-Behavior Graph Collaborative Filtering
Nov 12, 2023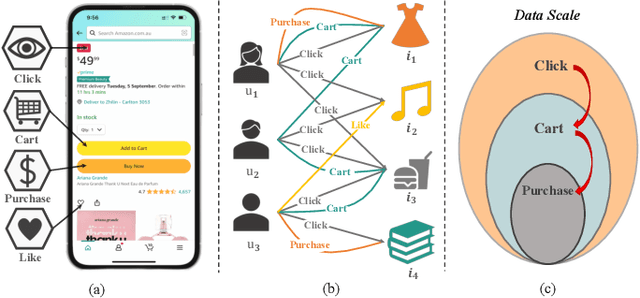
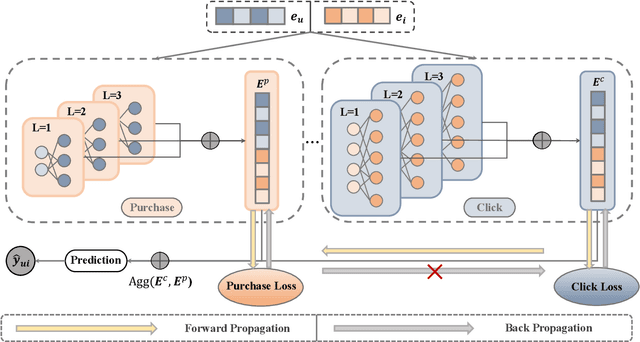


Graph collaborative filtering, which learns user and item representations through message propagation over the user-item interaction graph, has been shown to effectively enhance recommendation performance. However, most current graph collaborative filtering models mainly construct the interaction graph on a single behavior domain (e.g. click), even though users exhibit various types of behaviors on real-world platforms, including actions like click, cart, and purchase. Furthermore, due to variations in user engagement, there exists an imbalance in the scale of different types of behaviors. For instance, users may click and view multiple items but only make selective purchases from a small subset of them. How to alleviate the behavior imbalance problem and utilize information from the multiple behavior graphs concurrently to improve the target behavior conversion (e.g. purchase) remains underexplored. To this end, we propose IMGCF, a simple but effective model to alleviate behavior data imbalance for multi-behavior graph collaborative filtering. Specifically, IMGCF utilizes a multi-task learning framework for collaborative filtering on multi-behavior graphs. Then, to mitigate the data imbalance issue, IMGCF improves representation learning on the sparse behavior by leveraging representations learned from the behavior domain with abundant data volumes. Experiments on two widely-used multi-behavior datasets demonstrate the effectiveness of IMGCF.