 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeh-MINT: Modeling Pocket-Ligand Binding with Hierarchical Molecular Interaction Network
Apr 25, 2026Accurate molecular representations are critical for drug discovery, and a central challenge lies in capturing the chemical environment of molecular fragments, as key interactions, such as H-bond and π stacking, occur only under specific local conditions. Most existing approaches represent molecules as atom-level graphs; however, atom-level representations can hardly express higher-order chemical context (e.g., stereochemistry, lone pairs, conjugation). Fragment-based methods (e.g., principal subgraph, predefined functional groups) fail to preserve essential information such as chirality, aromaticity, and ionic states. This work addresses these limitations from two aspects. (i) OverlapBPE tokenization. We propose a novel data-driven molecule tokenization method. Unlike existing approaches, our method allows overlapping fragments, reflecting the inherently fuzzy boundaries of small-molecule substructures and, together with enriched chemical information at the token level, thereby preserving a more complete chemical context. (ii) h-MINT model. OverlapBPE induces many-to-many atom-fragment mappings, which necessitate a new hierarchical architecture. We therefore develop a hierarchical molecular interaction network capable of jointly modeling interactions at both atom and fragment levels. By supporting fragment overlaps, the model naturally accommodates the many-to-many atom-fragment mappings introduced by the OverlapBPE scheme. Extensive evaluation against state-of-the-art methods shows our method improves binding affinity prediction by 2-4% Pearson/Spearman correlation on PDBBind and LBA, enhances virtual screening by 1-3% in key metrics on DUD-E and LIT-PCBA, and achieves the best overall HTS performance on PubChem assays. Further analysis demonstrates that our method effectively captures interactive information while maintaining good generalization.
Snapshot multi-spectral imaging through defocusing and a Fourier imager network
Jan 24, 2025



Multi-spectral imaging, which simultaneously captures the spatial and spectral information of a scene, is widely used across diverse fields, including remote sensing, biomedical imaging, and agricultural monitoring. Here, we introduce a snapshot multi-spectral imaging approach employing a standard monochrome image sensor with no additional spectral filters or customized components. Our system leverages the inherent chromatic aberration of wavelength-dependent defocusing as a natural source of physical encoding of multi-spectral information; this encoded image information is rapidly decoded via a deep learning-based multi-spectral Fourier Imager Network (mFIN). We experimentally tested our method with six illumination bands and demonstrated an overall accuracy of 92.98% for predicting the illumination channels at the input and achieved a robust multi-spectral image reconstruction on various test objects. This deep learning-powered framework achieves high-quality multi-spectral image reconstruction using snapshot image acquisition with a monochrome image sensor and could be useful for applications in biomedicine, industrial quality control, and agriculture, among others.
Virtual Staining of Label-Free Tissue in Imaging Mass Spectrometry
Nov 20, 2024



Imaging mass spectrometry (IMS) is a powerful tool for untargeted, highly multiplexed molecular mapping of tissue in biomedical research. IMS offers a means of mapping the spatial distributions of molecular species in biological tissue with unparalleled chemical specificity and sensitivity. However, most IMS platforms are not able to achieve microscopy-level spatial resolution and lack cellular morphological contrast, necessitating subsequent histochemical staining, microscopic imaging and advanced image registration steps to enable molecular distributions to be linked to specific tissue features and cell types. Here, we present a virtual histological staining approach that enhances spatial resolution and digitally introduces cellular morphological contrast into mass spectrometry images of label-free human tissue using a diffusion model. Blind testing on human kidney tissue demonstrated that the virtually stained images of label-free samples closely match their histochemically stained counterparts (with Periodic Acid-Schiff staining), showing high concordance in identifying key renal pathology structures despite utilizing IMS data with 10-fold larger pixel size. Additionally, our approach employs an optimized noise sampling technique during the diffusion model's inference process to reduce variance in the generated images, yielding reliable and repeatable virtual staining. We believe this virtual staining method will significantly expand the applicability of IMS in life sciences and open new avenues for mass spectrometry-based biomedical research.
Super-resolved virtual staining of label-free tissue using diffusion models
Oct 26, 2024



Virtual staining of tissue offers a powerful tool for transforming label-free microscopy images of unstained tissue into equivalents of histochemically stained samples. This study presents a diffusion model-based super-resolution virtual staining approach utilizing a Brownian bridge process to enhance both the spatial resolution and fidelity of label-free virtual tissue staining, addressing the limitations of traditional deep learning-based methods. Our approach integrates novel sampling techniques into a diffusion model-based image inference process to significantly reduce the variance in the generated virtually stained images, resulting in more stable and accurate outputs. Blindly applied to lower-resolution auto-fluorescence images of label-free human lung tissue samples, the diffusion-based super-resolution virtual staining model consistently outperformed conventional approaches in resolution, structural similarity and perceptual accuracy, successfully achieving a super-resolution factor of 4-5x, increasing the output space-bandwidth product by 16-25-fold compared to the input label-free microscopy images. Diffusion-based super-resolved virtual tissue staining not only improves resolution and image quality but also enhances the reliability of virtual staining without traditional chemical staining, offering significant potential for clinical diagnostics.
On Cold Posteriors of Probabilistic Neural Networks: Understanding the Cold Posterior Effect and A New Way to Learn Cold Posteriors with Tight Generalization Guarantees
Oct 20, 2024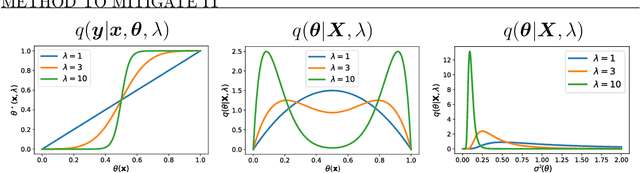


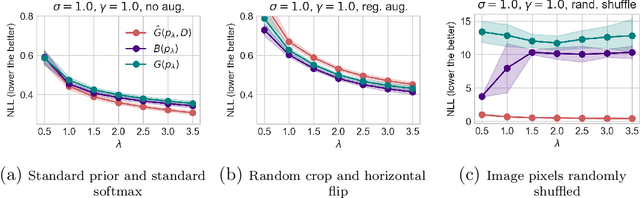
Bayesian inference provides a principled probabilistic framework for quantifying uncertainty by updating beliefs based on prior knowledge and observed data through Bayes' theorem. In Bayesian deep learning, neural network weights are treated as random variables with prior distributions, allowing for a probabilistic interpretation and quantification of predictive uncertainty. However, Bayesian methods lack theoretical generalization guarantees for unseen data. PAC-Bayesian analysis addresses this limitation by offering a frequentist framework to derive generalization bounds for randomized predictors, thereby certifying the reliability of Bayesian methods in machine learning. Temperature $T$, or inverse-temperature $\lambda = \frac{1}{T}$, originally from statistical mechanics in physics, naturally arises in various areas of statistical inference, including Bayesian inference and PAC-Bayesian analysis. In Bayesian inference, when $T < 1$ (``cold'' posteriors), the likelihood is up-weighted, resulting in a sharper posterior distribution. Conversely, when $T > 1$ (``warm'' posteriors), the likelihood is down-weighted, leading to a more diffuse posterior distribution. By balancing the influence of observed data and prior regularization, temperature adjustments can address issues of underfitting or overfitting in Bayesian models, bringing improved predictive performance.
Label-free evaluation of lung and heart transplant biopsies using virtual staining
Sep 09, 2024



Organ transplantation serves as the primary therapeutic strategy for end-stage organ failures. However, allograft rejection is a common complication of organ transplantation. Histological assessment is essential for the timely detection and diagnosis of transplant rejection and remains the gold standard. Nevertheless, the traditional histochemical staining process is time-consuming, costly, and labor-intensive. Here, we present a panel of virtual staining neural networks for lung and heart transplant biopsies, which digitally convert autofluorescence microscopic images of label-free tissue sections into their brightfield histologically stained counterparts, bypassing the traditional histochemical staining process. Specifically, we virtually generated Hematoxylin and Eosin (H&E), Masson's Trichrome (MT), and Elastic Verhoeff-Van Gieson (EVG) stains for label-free transplant lung tissue, along with H&E and MT stains for label-free transplant heart tissue. Subsequent blind evaluations conducted by three board-certified pathologists have confirmed that the virtual staining networks consistently produce high-quality histology images with high color uniformity, closely resembling their well-stained histochemical counterparts across various tissue features. The use of virtually stained images for the evaluation of transplant biopsies achieved comparable diagnostic outcomes to those obtained via traditional histochemical staining, with a concordance rate of 82.4% for lung samples and 91.7% for heart samples. Moreover, virtual staining models create multiple stains from the same autofluorescence input, eliminating structural mismatches observed between adjacent sections stained in the traditional workflow, while also saving tissue, expert time, and staining costs.
Recursive PAC-Bayes: A Frequentist Approach to Sequential Prior Updates with No Information Loss
May 23, 2024


PAC-Bayesian analysis is a frequentist framework for incorporating prior knowledge into learning. It was inspired by Bayesian learning, which allows sequential data processing and naturally turns posteriors from one processing step into priors for the next. However, despite two and a half decades of research, the ability to update priors sequentially without losing confidence information along the way remained elusive for PAC-Bayes. While PAC-Bayes allows construction of data-informed priors, the final confidence intervals depend only on the number of points that were not used for the construction of the prior, whereas confidence information in the prior, which is related to the number of points used to construct the prior, is lost. This limits the possibility and benefit of sequential prior updates, because the final bounds depend only on the size of the final batch. We present a novel and, in retrospect, surprisingly simple and powerful PAC-Bayesian procedure that allows sequential prior updates with no information loss. The procedure is based on a novel decomposition of the expected loss of randomized classifiers. The decomposition rewrites the loss of the posterior as an excess loss relative to a downscaled loss of the prior plus the downscaled loss of the prior, which is bounded recursively. As a side result, we also present a generalization of the split-kl and PAC-Bayes-split-kl inequalities to discrete random variables, which we use for bounding the excess losses, and which can be of independent interest. In empirical evaluation the new procedure significantly outperforms state-of-the-art.
Automated HER2 Scoring in Breast Cancer Images Using Deep Learning and Pyramid Sampling
Apr 01, 2024Human epidermal growth factor receptor 2 (HER2) is a critical protein in cancer cell growth that signifies the aggressiveness of breast cancer (BC) and helps predict its prognosis. Accurate assessment of immunohistochemically (IHC) stained tissue slides for HER2 expression levels is essential for both treatment guidance and understanding of cancer mechanisms. Nevertheless, the traditional workflow of manual examination by board-certified pathologists encounters challenges, including inter- and intra-observer inconsistency and extended turnaround times. Here, we introduce a deep learning-based approach utilizing pyramid sampling for the automated classification of HER2 status in IHC-stained BC tissue images. Our approach analyzes morphological features at various spatial scales, efficiently managing the computational load and facilitating a detailed examination of cellular and larger-scale tissue-level details. This method addresses the tissue heterogeneity of HER2 expression by providing a comprehensive view, leading to a blind testing classification accuracy of 84.70%, on a dataset of 523 core images from tissue microarrays. Our automated system, proving reliable as an adjunct pathology tool, has the potential to enhance diagnostic precision and evaluation speed, and might significantly impact cancer treatment planning.
Virtual birefringence imaging and histological staining of amyloid deposits in label-free tissue using autofluorescence microscopy and deep learning
Mar 14, 2024Systemic amyloidosis is a group of diseases characterized by the deposition of misfolded proteins in various organs and tissues, leading to progressive organ dysfunction and failure. Congo red stain is the gold standard chemical stain for the visualization of amyloid deposits in tissue sections, as it forms complexes with the misfolded proteins and shows a birefringence pattern under polarized light microscopy. However, Congo red staining is tedious and costly to perform, and prone to false diagnoses due to variations in the amount of amyloid, staining quality and expert interpretation through manual examination of tissue under a polarization microscope. Here, we report the first demonstration of virtual birefringence imaging and virtual Congo red staining of label-free human tissue to show that a single trained neural network can rapidly transform autofluorescence images of label-free tissue sections into brightfield and polarized light microscopy equivalent images, matching the histochemically stained versions of the same samples. We demonstrate the efficacy of our method with blind testing and pathologist evaluations on cardiac tissue where the virtually stained images agreed well with the histochemically stained ground truth images. Our virtually stained polarization and brightfield images highlight amyloid birefringence patterns in a consistent, reproducible manner while mitigating diagnostic challenges due to variations in the quality of chemical staining and manual imaging processes as part of the clinical workflow.
Large Language Model Interaction Simulator for Cold-Start Item Recommendation
Feb 14, 2024



Recommending cold items is a long-standing challenge for collaborative filtering models because these cold items lack historical user interactions to model their collaborative features. The gap between the content of cold items and their behavior patterns makes it difficult to generate accurate behavioral embeddings for cold items. Existing cold-start models use mapping functions to generate fake behavioral embeddings based on the content feature of cold items. However, these generated embeddings have significant differences from the real behavioral embeddings, leading to a negative impact on cold recommendation performance. To address this challenge, we propose an LLM Interaction Simulator (LLM-InS) to model users' behavior patterns based on the content aspect. This simulator allows recommender systems to simulate vivid interactions for each cold item and transform them from cold to warm items directly. Specifically, we outline the designing and training process of a tailored LLM-simulator that can simulate the behavioral patterns of users and items. Additionally, we introduce an efficient "filtering-and-refining" approach to take full advantage of the simulation power of the LLMs. Finally, we propose an updating method to update the embeddings of the items. we unified trains for both cold and warm items within a recommender model based on the simulated and real interactions. Extensive experiments using real behavioral embeddings demonstrate that our proposed model, LLM-InS, outperforms nine state-of-the-art cold-start methods and three LLM models in cold-start item recommendations.