 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Development and Testing of a Vine Robot for Urban Search and Rescue in Confined Rubble Environments
Sep 16, 2024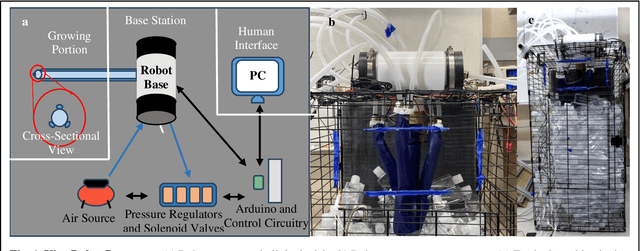
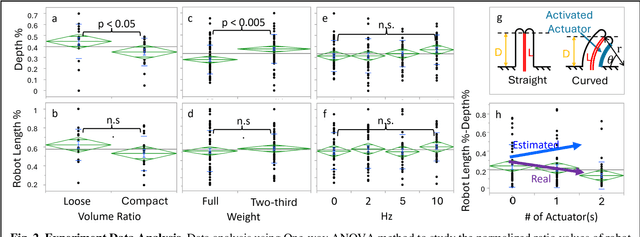
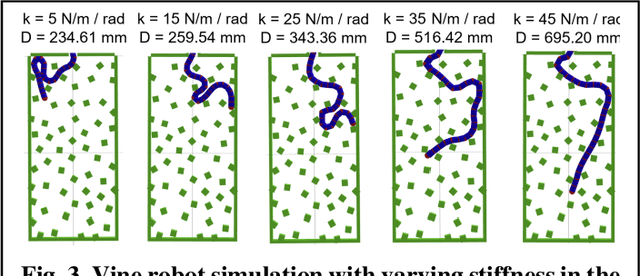

The request for fast response and safe operation after natural and man-made disasters in urban environments has spurred the development of robotic systems designed to assist in search and rescue operations within complex rubble sites. Traditional Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) face significant limitations in such confined and obstructed environments. This paper introduces a novel vine robot designed to navigate dense rubble, drawing inspiration from natural growth mechanisms found in plants. Unlike conventional robots, vine robots are soft robots that can grow by everting their material, allowing them to navigate through narrow spaces and obstacles. The prototype presented in this study incorporates pneumatic muscles for steering and oscillation, an equation-based robot length control plus feedback pressure regulating system for extending and retracting the robot body. We conducted a series of controlled experiments in an artificial rubble testbed to assess the robot performance under varying environmental conditions and robot parameters, including volume ratio, environmental weight, oscillation, and steering. The results show that the vine robot can achieve significant penetration depths in cluttered environments with mixed obstacle sizes and weights, and can maintain repeated trajectories, demonstrating potential for mapping and navigating complex underground paths. Our findings highlight the suitability of the vine robot for urban search and rescue missions, with further research planned to enhance its robustness and deployability in real-world scenarios.
A Self-Supervised Miniature One-Shot Texture Segmentation Model for Real-Time Robot Navigation and Embedded Applications
Jun 15, 2023Determining the drivable area, or free space segmentation, is critical for mobile robots to navigate indoor environments safely. However, the lack of coherent markings and structures (e.g., lanes, curbs, etc.) in indoor spaces places the burden of traversability estimation heavily on the mobile robot. This paper explores the use of a self-supervised one-shot texture segmentation framework and an RGB-D camera to achieve robust drivable area segmentation. With a fast inference speed and compact size, the developed model, MOSTS is ideal for real-time robot navigation and various embedded applications. A benchmark study was conducted to compare MOSTS's performance with existing one-shot texture segmentation models to evaluate its performance. Additionally, a validation dataset was built to assess MOSTS's ability to perform texture segmentation in the wild, where it effectively identified small low-lying objects that were previously undetectable by depth measurements. Further, the study also compared MOSTS's performance with two State-Of-The-Art (SOTA) indoor semantic segmentation models, both quantitatively and qualitatively. The results showed that MOSTS offers comparable accuracy with up to eight times faster inference speed in indoor drivable area segmentation.