 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Reliability of Causal Probing Methods: Tradeoffs, Limitations, and the Plight of Nullifying Interventions
Aug 28, 2024



Causal probing is an approach to interpreting foundation models, such as large language models, by training probes to recognize latent properties of interest from embeddings, intervening on probes to modify this representation, and analyzing the resulting changes in the model's behavior. While some recent works have cast doubt on the theoretical basis of several leading causal probing intervention methods, it has been unclear how to systematically and empirically evaluate their effectiveness in practice. To address this problem, we propose a general empirical analysis framework to evaluate the reliability of causal probing interventions, formally defining and quantifying two key causal probing desiderata: completeness (fully transforming the representation of the target property) and selectivity (minimally impacting other properties). Our formalism allows us to make the first direct comparisons between different families of causal probing methods (e.g., linear vs. nonlinear or counterfactual vs. nullifying interventions). We conduct extensive experiments across several leading methods, finding that (1) there is an inherent tradeoff between these criteria, and no method is able to consistently satisfy both at once; and (2) across the board, nullifying interventions are always far less complete than counterfactual interventions, indicating that nullifying methods may not be an effective approach to causal probing.
A Self-Supervised Miniature One-Shot Texture Segmentation Model for Real-Time Robot Navigation and Embedded Applications
Jun 15, 2023



Determining the drivable area, or free space segmentation, is critical for mobile robots to navigate indoor environments safely. However, the lack of coherent markings and structures (e.g., lanes, curbs, etc.) in indoor spaces places the burden of traversability estimation heavily on the mobile robot. This paper explores the use of a self-supervised one-shot texture segmentation framework and an RGB-D camera to achieve robust drivable area segmentation. With a fast inference speed and compact size, the developed model, MOSTS is ideal for real-time robot navigation and various embedded applications. A benchmark study was conducted to compare MOSTS's performance with existing one-shot texture segmentation models to evaluate its performance. Additionally, a validation dataset was built to assess MOSTS's ability to perform texture segmentation in the wild, where it effectively identified small low-lying objects that were previously undetectable by depth measurements. Further, the study also compared MOSTS's performance with two State-Of-The-Art (SOTA) indoor semantic segmentation models, both quantitatively and qualitatively. The results showed that MOSTS offers comparable accuracy with up to eight times faster inference speed in indoor drivable area segmentation.
Comparison of Dynamic and Kinematic Model Driven Extended Kalman Filters (EKF) for the Localization of Autonomous Underwater Vehicles
May 26, 2021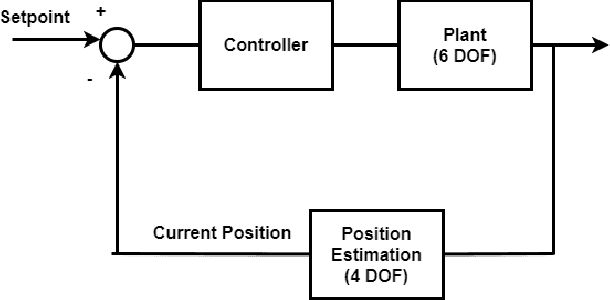
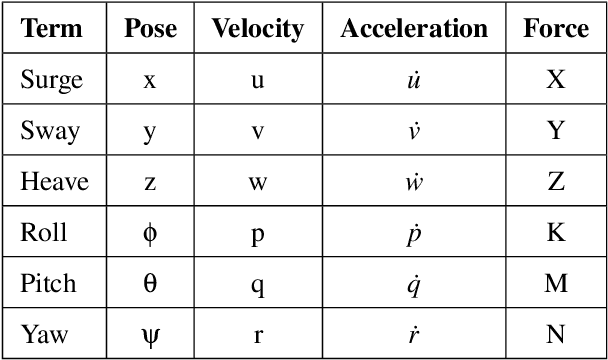
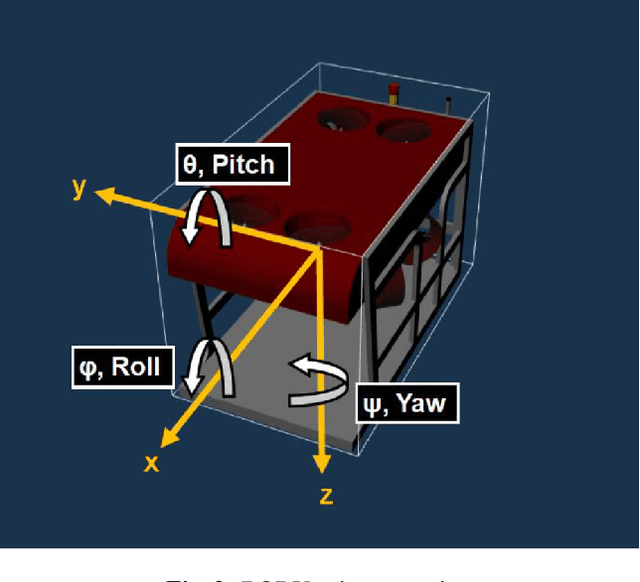
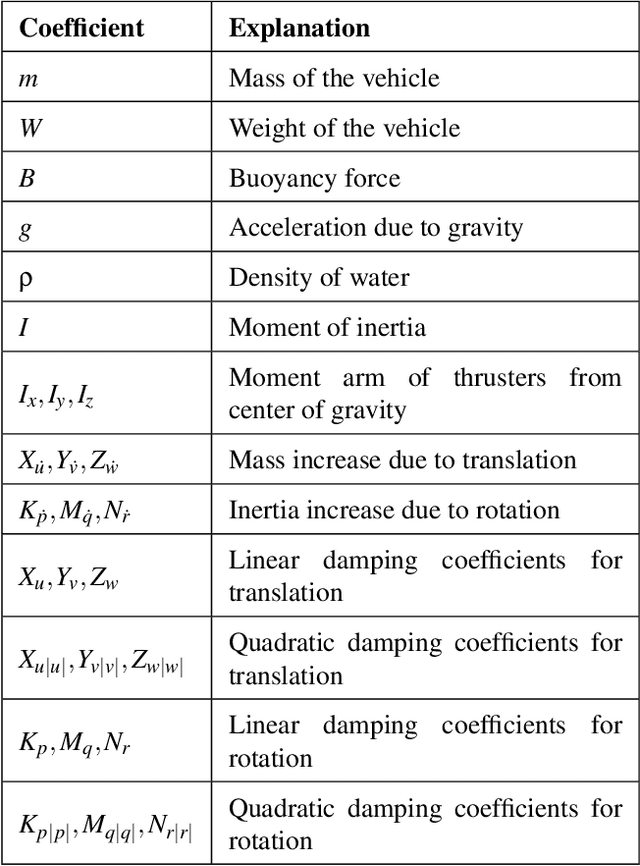
Autonomous Underwater Vehicles (AUVs) and Remotely Operated Vehicles (ROVs) are used for a wide variety of missions related to exploration and scientific research. Successful navigation by these systems requires a good localization system. Kalman filter based localization techniques have been prevalent since the early 1960s and extensive research has been carried out using them, both in development and in design. It has been found that the use of a dynamic model (instead of a kinematic model) in the Kalman filter can lead to more accurate predictions, as the dynamic model takes the forces acting on the AUV into account. Presented in this paper is a motion-predictive extended Kalman filter (EKF) for AUVs using a simplified dynamic model. The dynamic model is derived first and then it was simplified for a RexROV, a type of submarine vehicle used in simple underwater exploration, inspection of subsea structures, pipelines and shipwrecks. The filter was implemented with a simulated vehicle in an open-source marine vehicle simulator called UUV Simulator and the results were compared with the ground truth. The results show good prediction accuracy for the dynamic filter, though improvements are needed before the EKF can be used on real-time. Some perspective and discussion on practical implementation is presented to show the next steps needed for this concept.