 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauS-SLAM: Dense RGB-D SLAM with Gaussian Surfels
May 03, 2025



We propose GauS-SLAM, a dense RGB-D SLAM system that leverages 2D Gaussian surfels to achieve robust tracking and high-fidelity mapping. Our investigations reveal that Gaussian-based scene representations exhibit geometry distortion under novel viewpoints, which significantly degrades the accuracy of Gaussian-based tracking methods. These geometry inconsistencies arise primarily from the depth modeling of Gaussian primitives and the mutual interference between surfaces during the depth blending. To address these, we propose a 2D Gaussian-based incremental reconstruction strategy coupled with a Surface-aware Depth Rendering mechanism, which significantly enhances geometry accuracy and multi-view consistency. Additionally, the proposed local map design dynamically isolates visible surfaces during tracking, mitigating misalignment caused by occluded regions in global maps while maintaining computational efficiency with increasing Gaussian density. Extensive experiments across multiple datasets demonstrate that GauS-SLAM outperforms comparable methods, delivering superior tracking precision and rendering fidelity. The project page will be made available at https://gaus-slam.github.io.
MVGSR: Multi-View Consistency Gaussian Splatting for Robust Surface Reconstruction
Mar 11, 2025



3D Gaussian Splatting (3DGS) has gained significant attention for its high-quality rendering capabilities, ultra-fast training, and inference speeds. However, when we apply 3DGS to surface reconstruction tasks, especially in environments with dynamic objects and distractors, the method suffers from floating artifacts and color errors due to inconsistency from different viewpoints. To address this challenge, we propose Multi-View Consistency Gaussian Splatting for the domain of Robust Surface Reconstruction (\textbf{MVGSR}), which takes advantage of lightweight Gaussian models and a {heuristics-guided distractor masking} strategy for robust surface reconstruction in non-static environments. Compared to existing methods that rely on MLPs for distractor segmentation strategies, our approach separates distractors from static scene elements by comparing multi-view feature consistency, allowing us to obtain precise distractor masks early in training. Furthermore, we introduce a pruning measure based on multi-view contributions to reset transmittance, effectively reducing floating artifacts. Finally, a multi-view consistency loss is applied to achieve high-quality performance in surface reconstruction tasks. Experimental results demonstrate that MVGSR achieves competitive geometric accuracy and rendering fidelity compared to the state-of-the-art surface reconstruction algorithms. More information is available on our project page (\href{https://mvgsr.github.io}{this url})
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022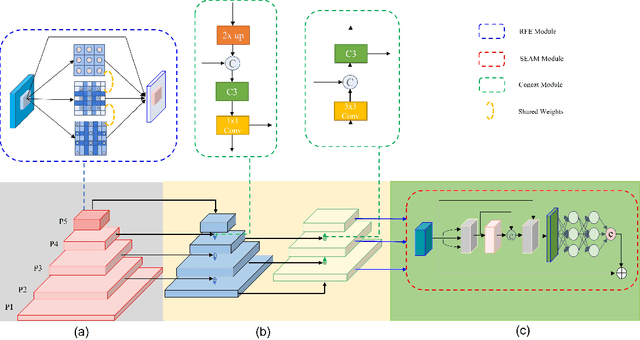
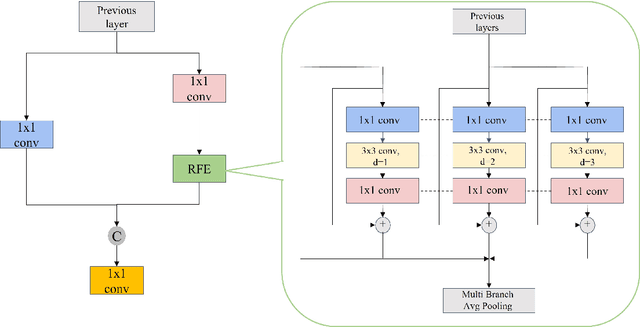
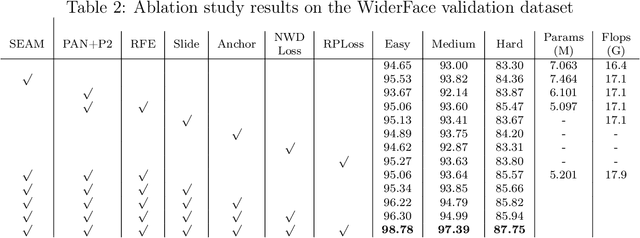
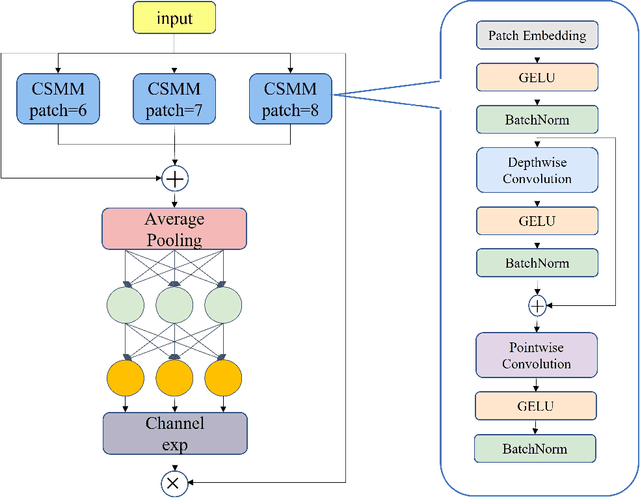
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2