 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCDNet: Frequency-Guided Complementary Dependency Modeling for Multivariate Time-Series Forecasting
Dec 27, 2023



Multivariate time-series (MTS) forecasting is a challenging task in many real-world non-stationary dynamic scenarios. In addition to intra-series temporal signals, the inter-series dependency also plays a crucial role in shaping future trends. How to enable the model's awareness of dependency information has raised substantial research attention. Previous approaches have either presupposed dependency constraints based on domain knowledge or imposed them using real-time feature similarity. However, MTS data often exhibit both enduring long-term static relationships and transient short-term interactions, which mutually influence their evolving states. It is necessary to recognize and incorporate the complementary dependencies for more accurate MTS prediction. The frequency information in time series reflects the evolutionary rules behind complex temporal dynamics, and different frequency components can be used to well construct long-term and short-term interactive dependency structures between variables. To this end, we propose FCDNet, a concise yet effective framework for multivariate time-series forecasting. Specifically, FCDNet overcomes the above limitations by applying two light-weight dependency constructors to help extract long- and short-term dependency information adaptively from multi-level frequency patterns. With the growth of input variables, the number of trainable parameters in FCDNet only increases linearly, which is conducive to the model's scalability and avoids over-fitting. Additionally, adopting a frequency-based perspective can effectively mitigate the influence of noise within MTS data, which helps capture more genuine dependencies. The experimental results on six real-world datasets from multiple fields show that FCDNet significantly exceeds strong baselines, with an average improvement of 6.82% on MAE, 4.98% on RMSE, and 4.91% on MAPE.
Individual and Structural Graph Information Bottlenecks for Out-of-Distribution Generalization
Jun 28, 2023



Out-of-distribution (OOD) graph generalization are critical for many real-world applications. Existing methods neglect to discard spurious or noisy features of inputs, which are irrelevant to the label. Besides, they mainly conduct instance-level class-invariant graph learning and fail to utilize the structural class relationships between graph instances. In this work, we endeavor to address these issues in a unified framework, dubbed Individual and Structural Graph Information Bottlenecks (IS-GIB). To remove class spurious feature caused by distribution shifts, we propose Individual Graph Information Bottleneck (I-GIB) which discards irrelevant information by minimizing the mutual information between the input graph and its embeddings. To leverage the structural intra- and inter-domain correlations, we propose Structural Graph Information Bottleneck (S-GIB). Specifically for a batch of graphs with multiple domains, S-GIB first computes the pair-wise input-input, embedding-embedding, and label-label correlations. Then it minimizes the mutual information between input graph and embedding pairs while maximizing the mutual information between embedding and label pairs. The critical insight of S-GIB is to simultaneously discard spurious features and learn invariant features from a high-order perspective by maintaining class relationships under multiple distributional shifts. Notably, we unify the proposed I-GIB and S-GIB to form our complementary framework IS-GIB. Extensive experiments conducted on both node- and graph-level tasks consistently demonstrate the superior generalization ability of IS-GIB. The code is available at https://github.com/YangLing0818/GraphOOD.
Spatial Autoregressive Coding for Graph Neural Recommendation
May 19, 2022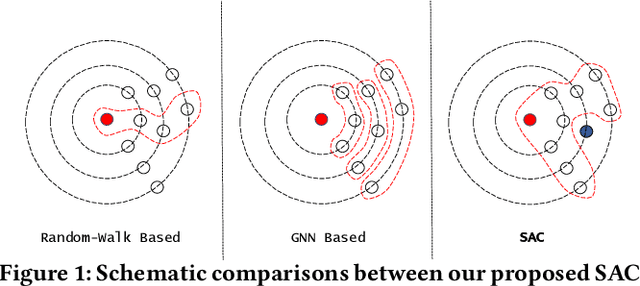
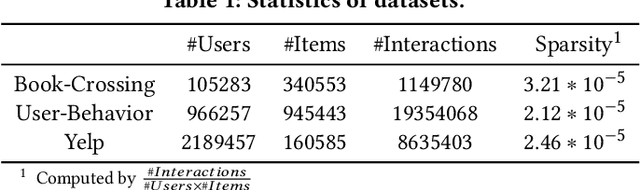
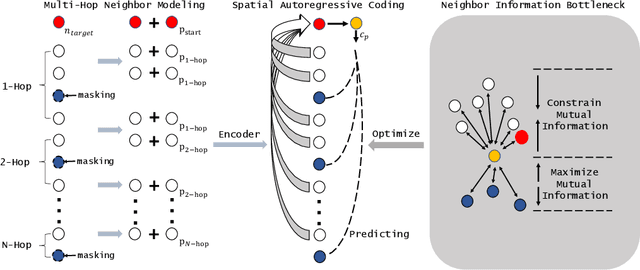
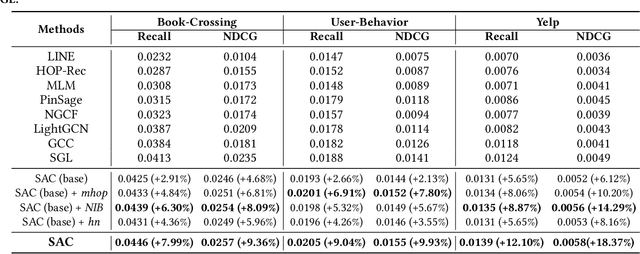
Graph embedding methods including traditional shallow models and deep Graph Neural Networks (GNNs) have led to promising applications in recommendation. Nevertheless, shallow models especially random-walk-based algorithms fail to adequately exploit neighbor proximity in sampled subgraphs or sequences due to their optimization paradigm. GNN-based algorithms suffer from the insufficient utilization of high-order information and easily cause over-smoothing problems when stacking too much layers, which may deteriorate the recommendations of low-degree (long-tail) items, limiting the expressiveness and scalability. In this paper, we propose a novel framework SAC, namely Spatial Autoregressive Coding, to solve the above problems in a unified way. To adequately leverage neighbor proximity and high-order information, we design a novel spatial autoregressive paradigm. Specifically, we first randomly mask multi-hop neighbors and embed the target node by integrating all other surrounding neighbors with an explicit multi-hop attention. Then we reinforce the model to learn a neighbor-predictive coding for the target node by contrasting the coding and the masked neighbors' embedding, equipped with a new hard negative sampling strategy. To learn the minimal sufficient representation for the target-to-neighbor prediction task and remove the redundancy of neighbors, we devise Neighbor Information Bottleneck by maximizing the mutual information between target predictive coding and the masked neighbors' embedding, and simultaneously constraining those between the coding and surrounding neighbors' embedding. Experimental results on both public recommendation datasets and a real scenario web-scale dataset Douyin-Friend-Recommendation demonstrate the superiority of SAC compared with state-of-the-art methods.