 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAEC: Position-Aware Entropy Calibration for LLM Reasoning in RLVR
Jun 07, 2026Reinforcement learning with verifiable rewards (RLVR) improves large language model reasoning but often suffers from rapid policy-entropy collapse, where the policy prematurely concentrates on narrow high-probability reasoning paths. While global entropy regularization can encourage exploration, uniformly increasing entropy across all token positions is inefficient for long reasoning trajectories, where many tokens are not decision-relevant. We propose Position-Aware Entropy Calibration (PAEC), a token-level entropy-management framework that constructs a soft mask from local top-p entropy and top-two candidate competition, and applies an anchor-based lower-bound penalty to prevent selected-position entropy collapse. Experiments on five mathematical reasoning benchmarks show that PAEC improves macro-average majority-vote performance over strong RLVR baselines, with clear gains on AIME-style tasks. Our results suggest that entropy management in reasoning RL should be formulated as selective exploration allocation over decision-sensitive positions rather than uniform randomness injection.
Individual and Structural Graph Information Bottlenecks for Out-of-Distribution Generalization
Jun 28, 2023



Out-of-distribution (OOD) graph generalization are critical for many real-world applications. Existing methods neglect to discard spurious or noisy features of inputs, which are irrelevant to the label. Besides, they mainly conduct instance-level class-invariant graph learning and fail to utilize the structural class relationships between graph instances. In this work, we endeavor to address these issues in a unified framework, dubbed Individual and Structural Graph Information Bottlenecks (IS-GIB). To remove class spurious feature caused by distribution shifts, we propose Individual Graph Information Bottleneck (I-GIB) which discards irrelevant information by minimizing the mutual information between the input graph and its embeddings. To leverage the structural intra- and inter-domain correlations, we propose Structural Graph Information Bottleneck (S-GIB). Specifically for a batch of graphs with multiple domains, S-GIB first computes the pair-wise input-input, embedding-embedding, and label-label correlations. Then it minimizes the mutual information between input graph and embedding pairs while maximizing the mutual information between embedding and label pairs. The critical insight of S-GIB is to simultaneously discard spurious features and learn invariant features from a high-order perspective by maintaining class relationships under multiple distributional shifts. Notably, we unify the proposed I-GIB and S-GIB to form our complementary framework IS-GIB. Extensive experiments conducted on both node- and graph-level tasks consistently demonstrate the superior generalization ability of IS-GIB. The code is available at https://github.com/YangLing0818/GraphOOD.
KnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Few-Shot NLP
Jun 21, 2022
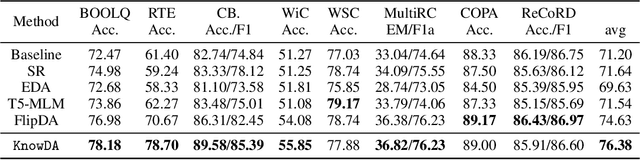

This paper focuses on text data augmentation for few-shot NLP tasks. The existing data augmentation algorithms either leverage task-independent heuristic rules (e.g., Synonym Replacement) or fine-tune general-purpose pre-trained language models (e.g., GPT2) using a small training set to produce new synthetic data. Consequently, these methods have trivial task-specific knowledge and are limited to yielding low-quality synthetic data for weak baselines in simple tasks. To combat this issue, we propose the Knowledge Mixture Data Augmentation Model (KnowDA): an encoder-decoder LM pretrained on a mixture of diverse NLP tasks using Knowledge Mixture Training (KoMT). KoMT is a training procedure that reformulates input examples from various heterogeneous NLP tasks into a unified text-to-text format and employs denoising objectives in different granularity to learn to generate partial or complete samples. With the aid of KoMT, KnowDA could combine required task-specific knowledge implicitly from the learned mixture of tasks and quickly grasp the inherent synthesis law of the target task through a few given instances. To the best of our knowledge, we are the first attempt to scale the number of tasks to 100+ in multi-task co-training for data augmentation. Extensive experiments show that i) KnowDA successfully improves the performance of Albert and Deberta by a large margin on the FewGLUE benchmark, outperforming previous state-of-the-art data augmentation baselines; ii) KnowDA could also improve the model performance on the few-shot NER tasks, a held-out task type not included in KoMT.
Spatial Autoregressive Coding for Graph Neural Recommendation
May 19, 2022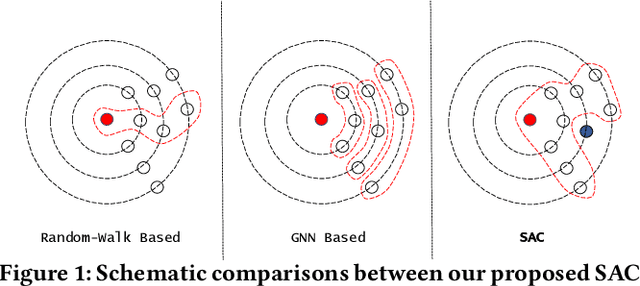
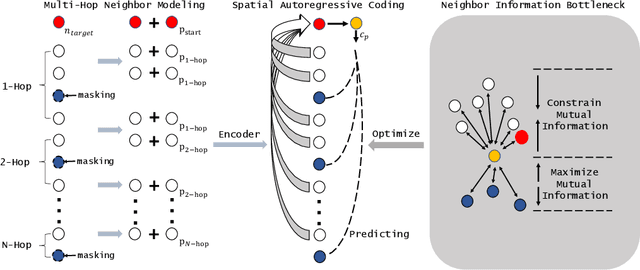
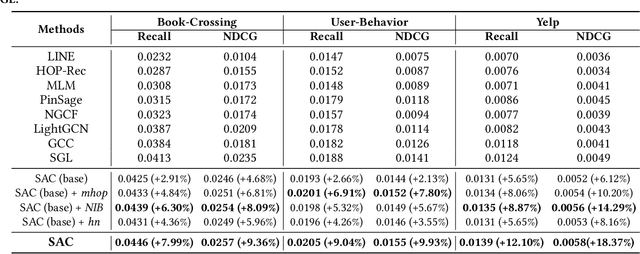
Graph embedding methods including traditional shallow models and deep Graph Neural Networks (GNNs) have led to promising applications in recommendation. Nevertheless, shallow models especially random-walk-based algorithms fail to adequately exploit neighbor proximity in sampled subgraphs or sequences due to their optimization paradigm. GNN-based algorithms suffer from the insufficient utilization of high-order information and easily cause over-smoothing problems when stacking too much layers, which may deteriorate the recommendations of low-degree (long-tail) items, limiting the expressiveness and scalability. In this paper, we propose a novel framework SAC, namely Spatial Autoregressive Coding, to solve the above problems in a unified way. To adequately leverage neighbor proximity and high-order information, we design a novel spatial autoregressive paradigm. Specifically, we first randomly mask multi-hop neighbors and embed the target node by integrating all other surrounding neighbors with an explicit multi-hop attention. Then we reinforce the model to learn a neighbor-predictive coding for the target node by contrasting the coding and the masked neighbors' embedding, equipped with a new hard negative sampling strategy. To learn the minimal sufficient representation for the target-to-neighbor prediction task and remove the redundancy of neighbors, we devise Neighbor Information Bottleneck by maximizing the mutual information between target predictive coding and the masked neighbors' embedding, and simultaneously constraining those between the coding and surrounding neighbors' embedding. Experimental results on both public recommendation datasets and a real scenario web-scale dataset Douyin-Friend-Recommendation demonstrate the superiority of SAC compared with state-of-the-art methods.
Handling Noisy Labels via One-Step Abductive Multi-Target Learning
Nov 25, 2020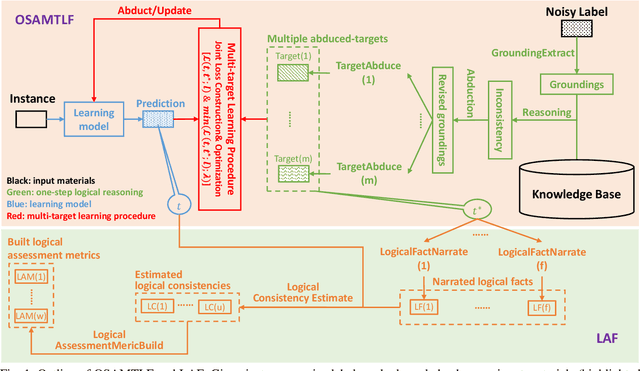
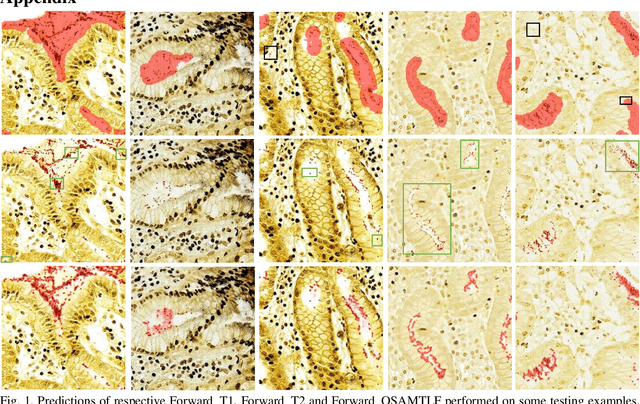
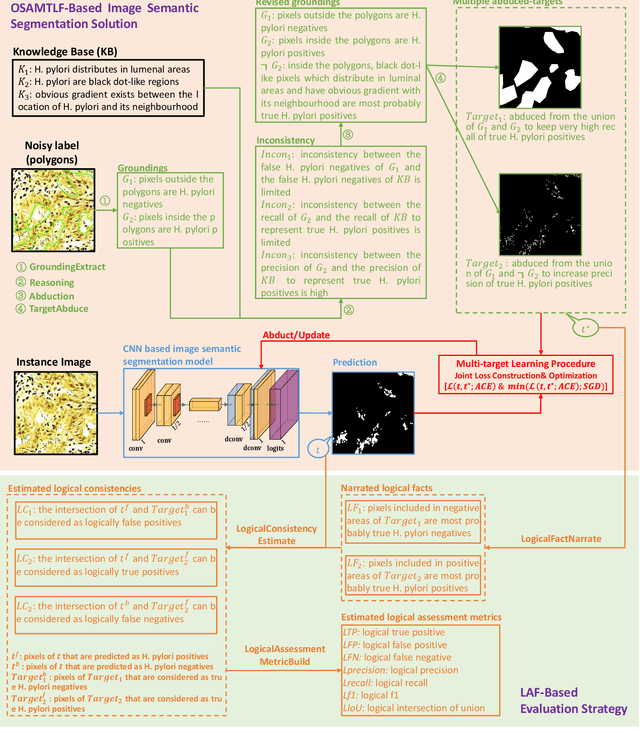

Learning from noisy labels is an important concern because of the lack of accurate ground-truth labels in plenty of real-world scenarios. In practice, various approaches for this concern first make corrections corresponding to potentially noisy-labeled instances, and then update predictive model with information of the made corrections. However, in specific areas, such as medical histopathology whole slide image analysis (MHWSIA), it is often difficult or even impossible for experts to manually achieve the noisy-free ground-truth labels which leads to labels with heavy noise. This situation raises two more difficult problems: 1) the methodology of approaches making corrections corresponding to potentially noisy-labeled instances has limitations due to the heavy noise existing in labels; and 2) the appropriate evaluation strategy for validation/testing is unclear because of the great difficulty in collecting the noisy-free ground-truth labels. In this paper, we focus on alleviating these two problems. For the problem 1), we present a one-step abductive multi-target learning framework (OSAMTLF) that imposes a one-step logical reasoning upon machine learning via a multi-target learning procedure to abduct the predictions of the learning model to be subject to our prior knowledge. For the problem 2), we propose a logical assessment formula (LAF) that evaluates the logical rationality of the outputs of an approach by estimating the consistencies between the predictions of the learning model and the logical facts narrated from the results of the one-step logical reasoning of OSAMTLF. Applying OSAMTLF and LAF to the Helicobacter pylori (H. pylori) segmentation task in MHWSIA, we show that OSAMTLF is able to abduct the machine learning model achieving logically more rational predictions, which is beyond the capability of various state-of-the-art approaches for learning from noisy labels.