 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Few-Shot NLP
Paper and Code

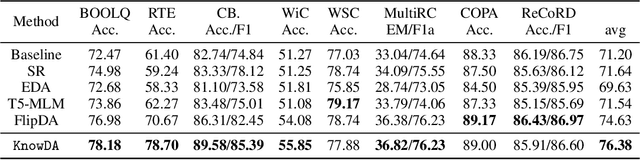
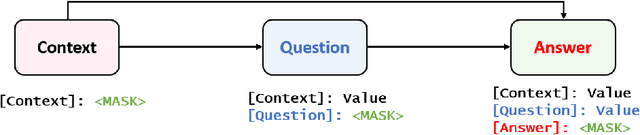

This paper focuses on text data augmentation for few-shot NLP tasks. The existing data augmentation algorithms either leverage task-independent heuristic rules (e.g., Synonym Replacement) or fine-tune general-purpose pre-trained language models (e.g., GPT2) using a small training set to produce new synthetic data. Consequently, these methods have trivial task-specific knowledge and are limited to yielding low-quality synthetic data for weak baselines in simple tasks. To combat this issue, we propose the Knowledge Mixture Data Augmentation Model (KnowDA): an encoder-decoder LM pretrained on a mixture of diverse NLP tasks using Knowledge Mixture Training (KoMT). KoMT is a training procedure that reformulates input examples from various heterogeneous NLP tasks into a unified text-to-text format and employs denoising objectives in different granularity to learn to generate partial or complete samples. With the aid of KoMT, KnowDA could combine required task-specific knowledge implicitly from the learned mixture of tasks and quickly grasp the inherent synthesis law of the target task through a few given instances. To the best of our knowledge, we are the first attempt to scale the number of tasks to 100+ in multi-task co-training for data augmentation. Extensive experiments show that i) KnowDA successfully improves the performance of Albert and Deberta by a large margin on the FewGLUE benchmark, outperforming previous state-of-the-art data augmentation baselines; ii) KnowDA could also improve the model performance on the few-shot NER tasks, a held-out task type not included in KoMT.