 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-MTL: Multitask Learning with Shift3D and Random-weighted Loss for Automated Diagnosis and Severity Assessment of COVID-19
Dec 31, 2020
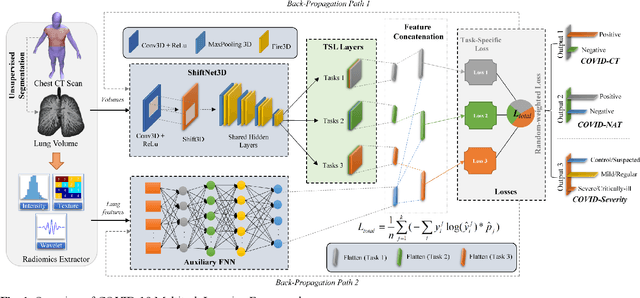
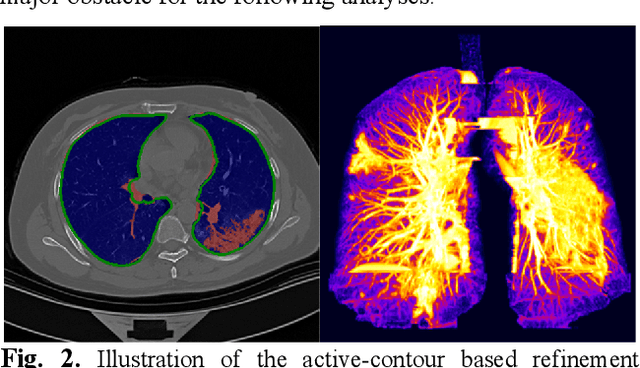
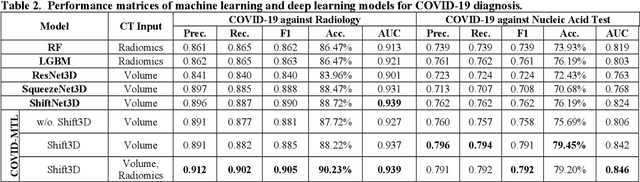
There is an urgent need for automated methods to assist accurate and effective assessment of COVID-19. Radiology and nucleic acid test (NAT) are complementary COVID-19 diagnosis methods. In this paper, we present an end-to-end multitask learning (MTL) framework (COVID-MTL) that is capable of automated and simultaneous detection (against both radiology and NAT) and severity assessment of COVID-19. COVID-MTL learns different COVID-19 tasks in parallel through our novel random-weighted loss function, which assigns learning weights under Dirichlet distribution to prevent task dominance; our new 3D real-time augmentation algorithm (Shift3D) introduces space variances for 3D CNN components by shifting low-level feature representations of volumetric inputs in three dimensions; thereby, the MTL framework is able to accelerate convergence and improve joint learning performance compared to single-task models. By only using chest CT scans, COVID-MTL was trained on 930 CT scans and tested on separate 399 cases. COVID-MTL achieved AUCs of 0.939 and 0.846, and accuracies of 90.23% and 79.20% for detection of COVID-19 against radiology and NAT, respectively, which outperformed the state-of-the-art models. Meanwhile, COVID-MTL yielded AUC of 0.800 $\pm$ 0.020 and 0.813 $\pm$ 0.021 (with transfer learning) for classifying control/suspected, mild/regular, and severe/critically-ill cases. To decipher the recognition mechanism, we also identified high-throughput lung features that were significantly related (P < 0.001) to the positivity and severity of COVID-19.
Depthwise Multiception Convolution for Reducing Network Parameters without Sacrificing Accuracy
Nov 07, 2020



Deep convolutional neural networks have been proven successful in multiple benchmark challenges in recent years. However, the performance improvements are heavily reliant on increasingly complex network architecture and a high number of parameters, which require ever increasing amounts of storage and memory capacity. Depthwise separable convolution (DSConv) can effectively reduce the number of required parameters through decoupling standard convolution into spatial and cross-channel convolution steps. However, the method causes a degradation of accuracy. To address this problem, we present depthwise multiception convolution, termed Multiception, which introduces layer-wise multiscale kernels to learn multiscale representations of all individual input channels simultaneously. We have carried out the experiment on four benchmark datasets, i.e. Cifar-10, Cifar-100, STL-10 and ImageNet32x32, using five popular CNN models, Multiception achieved accuracy promotion in all models and demonstrated higher accuracy performance compared to related works. Meanwhile, Multiception significantly reduces the number of parameters of standard convolution-based models by 32.48% on average while still preserving accuracy.