 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegrees of Freedom Analysis of Unrolled Neural Networks
Paper and Code
Jun 10, 2019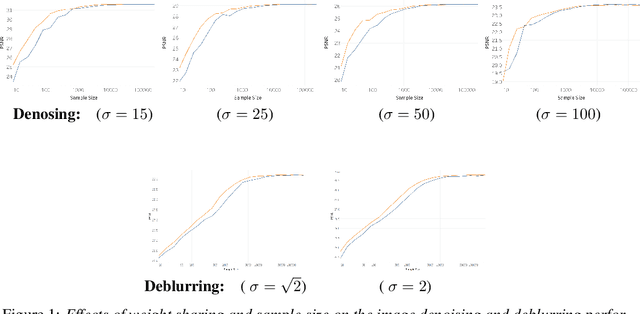
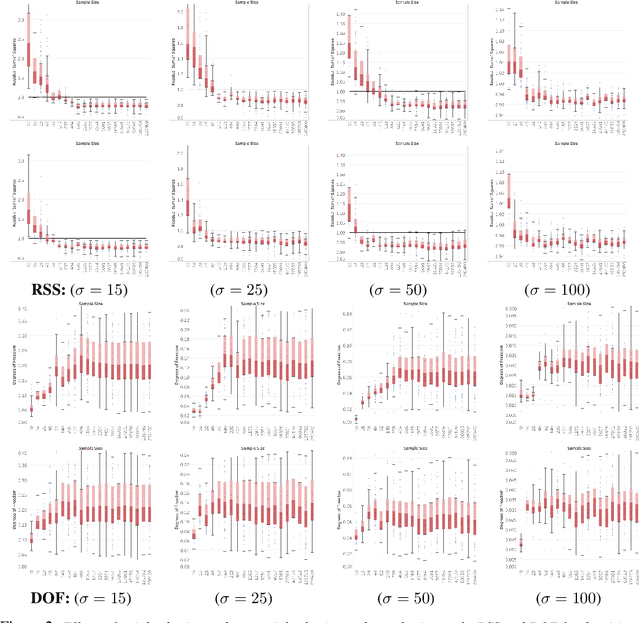
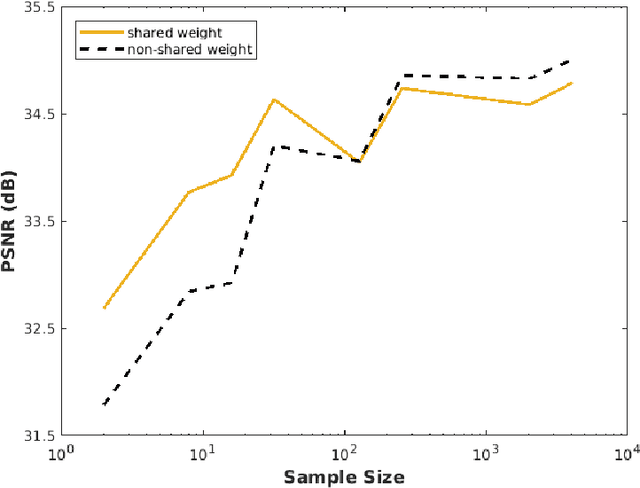
Unrolled neural networks emerged recently as an effective model for learning inverse maps appearing in image restoration tasks. However, their generalization risk (i.e., test mean-squared-error) and its link to network design and train sample size remains mysterious. Leveraging the Stein's Unbiased Risk Estimator (SURE), this paper analyzes the generalization risk with its bias and variance components for recurrent unrolled networks. We particularly investigate the degrees-of-freedom (DOF) component of SURE, trace of the end-to-end network Jacobian, to quantify the prediction variance. We prove that DOF is well-approximated by the weighted \textit{path sparsity} of the network under incoherence conditions on the trained weights. Empirically, we examine the SURE components as a function of train sample size for both recurrent and non-recurrent (with many more parameters) unrolled networks. Our key observations indicate that: 1) DOF increases with train sample size and converges to the generalization risk for both recurrent and non-recurrent schemes; 2) recurrent network converges significantly faster (with less train samples) compared with non-recurrent scheme, hence recurrence serves as a regularization for low sample size regimes.