 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Proximal Gradient Descent for Compressive Imaging
Jun 01, 2018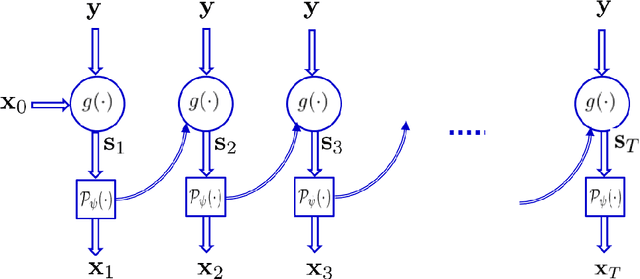
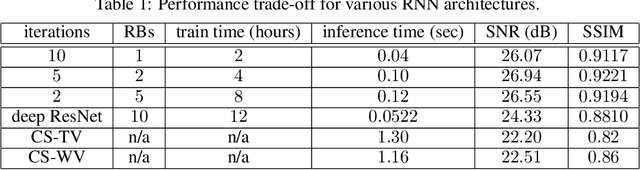
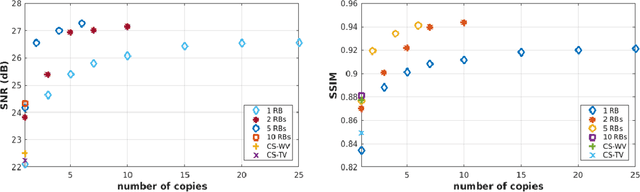
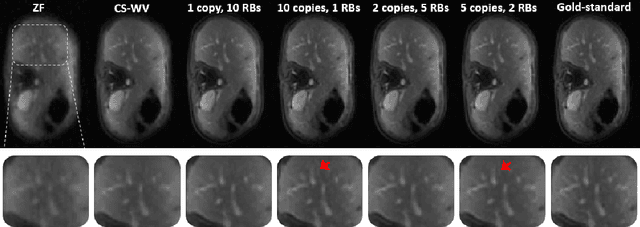
Recovering high-resolution images from limited sensory data typically leads to a serious ill-posed inverse problem, demanding inversion algorithms that effectively capture the prior information. Learning a good inverse mapping from training data faces severe challenges, including: (i) scarcity of training data; (ii) need for plausible reconstructions that are physically feasible; (iii) need for fast reconstruction, especially in real-time applications. We develop a successful system solving all these challenges, using as basic architecture the recurrent application of proximal gradient algorithm. We learn a proximal map that works well with real images based on residual networks. Contraction of the resulting map is analyzed, and incoherence conditions are investigated that drive the convergence of the iterates. Extensive experiments are carried out under different settings: (a) reconstructing abdominal MRI of pediatric patients from highly undersampled Fourier-space data and (b) superresolving natural face images. Our key findings include: 1. a recurrent ResNet with a single residual block unrolled from an iterative algorithm yields an effective proximal which accurately reveals MR image details. 2. Our architecture significantly outperforms conventional non-recurrent deep ResNets by 2dB SNR; it is also trained much more rapidly. 3. It outperforms state-of-the-art compressed-sensing Wavelet-based methods by 4dB SNR, with 100x speedups in reconstruction time.
Recurrent Generative Adversarial Networks for Proximal Learning and Automated Compressive Image Recovery
Nov 27, 2017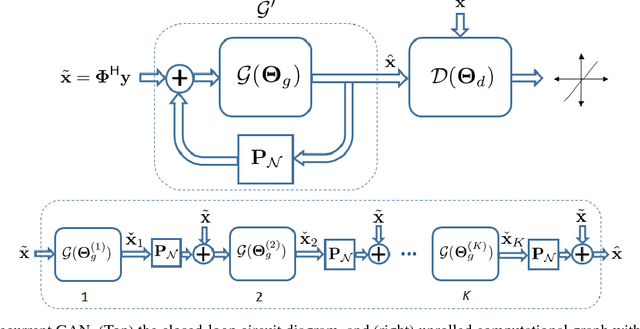

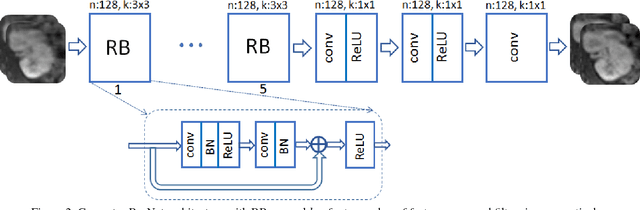
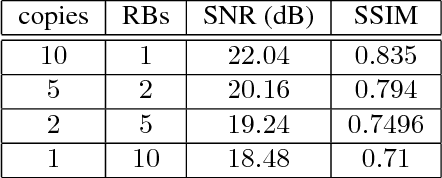
Recovering images from undersampled linear measurements typically leads to an ill-posed linear inverse problem, that asks for proper statistical priors. Building effective priors is however challenged by the low train and test overhead dictated by real-time tasks; and the need for retrieving visually "plausible" and physically "feasible" images with minimal hallucination. To cope with these challenges, we design a cascaded network architecture that unrolls the proximal gradient iterations by permeating benefits from generative residual networks (ResNet) to modeling the proximal operator. A mixture of pixel-wise and perceptual costs is then deployed to train proximals. The overall architecture resembles back-and-forth projection onto the intersection of feasible and plausible images. Extensive computational experiments are examined for a global task of reconstructing MR images of pediatric patients, and a more local task of superresolving CelebA faces, that are insightful to design efficient architectures. Our observations indicate that for MRI reconstruction, a recurrent ResNet with a single residual block effectively learns the proximal. This simple architecture appears to significantly outperform the alternative deep ResNet architecture by 2dB SNR, and the conventional compressed-sensing MRI by 4dB SNR with 100x faster inference. For image superresolution, our preliminary results indicate that modeling the denoising proximal demands deep ResNets.