 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Underdiagnosed Medical Conditions with Deep Learning-Based Opportunistic CT Imaging
Sep 18, 2024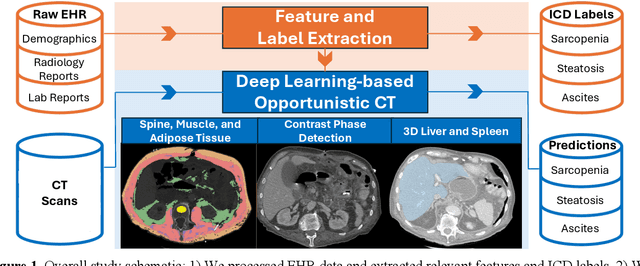
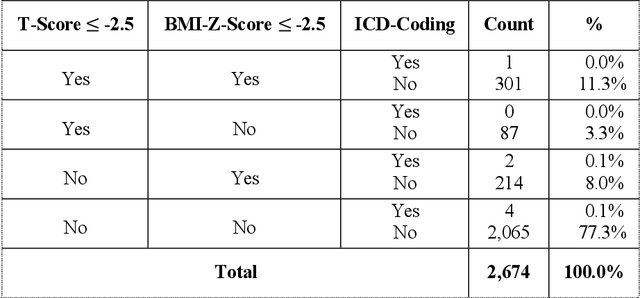
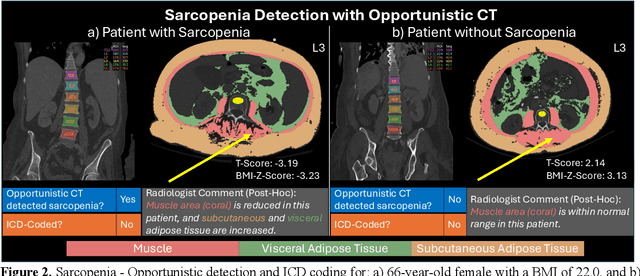
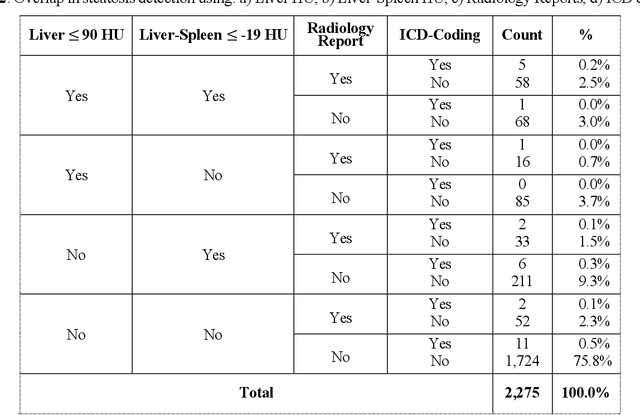
Abdominal computed tomography (CT) scans are frequently performed in clinical settings. Opportunistic CT involves repurposing routine CT images to extract diagnostic information and is an emerging tool for detecting underdiagnosed conditions such as sarcopenia, hepatic steatosis, and ascites. This study utilizes deep learning methods to promote accurate diagnosis and clinical documentation. We analyze 2,674 inpatient CT scans to identify discrepancies between imaging phenotypes (characteristics derived from opportunistic CT scans) and their corresponding documentation in radiology reports and ICD coding. Through our analysis, we find that only 0.5%, 3.2%, and 30.7% of scans diagnosed with sarcopenia, hepatic steatosis, and ascites (respectively) through either opportunistic imaging or radiology reports were ICD-coded. Our findings demonstrate opportunistic CT's potential to enhance diagnostic precision and accuracy of risk adjustment models, offering advancements in precision medicine.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
Comp2Comp: Open-Source Body Composition Assessment on Computed Tomography
Feb 13, 2023Computed tomography (CT) is routinely used in clinical practice to evaluate a wide variety of medical conditions. While CT scans provide diagnoses, they also offer the ability to extract quantitative body composition metrics to analyze tissue volume and quality. Extracting quantitative body composition measures manually from CT scans is a cumbersome and time-consuming task. Proprietary software has been developed recently to automate this process, but the closed-source nature impedes widespread use. There is a growing need for fully automated body composition software that is more accessible and easier to use, especially for clinicians and researchers who are not experts in medical image processing. To this end, we have built Comp2Comp, an open-source Python package for rapid and automated body composition analysis of CT scans. This package offers models, post-processing heuristics, body composition metrics, automated batching, and polychromatic visualizations. Comp2Comp currently computes body composition measures for bone, skeletal muscle, visceral adipose tissue, and subcutaneous adipose tissue on CT scans of the abdomen. We have created two pipelines for this purpose. The first pipeline computes vertebral measures, as well as muscle and adipose tissue measures, at the T12 - L5 vertebral levels from abdominal CT scans. The second pipeline computes muscle and adipose tissue measures on user-specified 2D axial slices. In this guide, we discuss the architecture of the Comp2Comp pipelines, provide usage instructions, and report internal and external validation results to measure the quality of segmentations and body composition measures. Comp2Comp can be found at https://github.com/StanfordMIMI/Comp2Comp.
Scale-Agnostic Super-Resolution in MRI using Feature-Based Coordinate Networks
Oct 18, 2022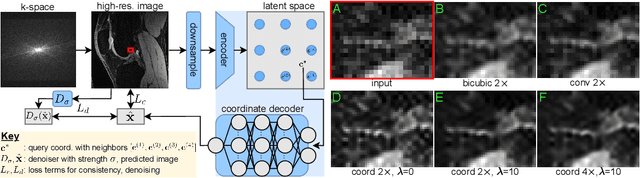
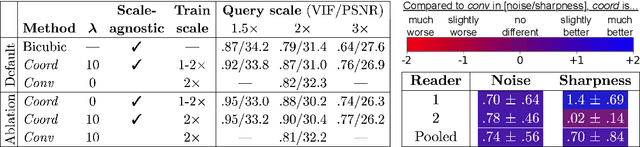
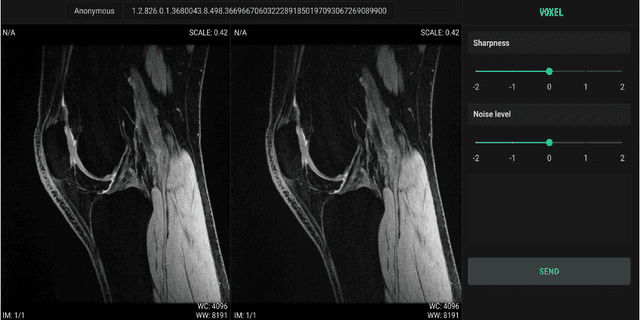
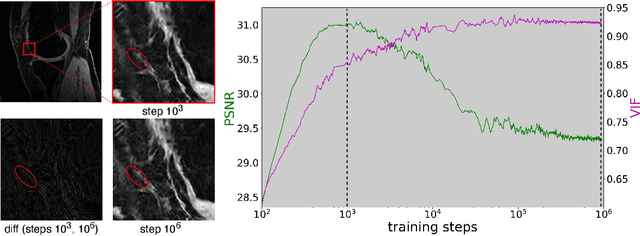
We propose using a coordinate network decoder for the task of super-resolution in MRI. The continuous signal representation of coordinate networks enables this approach to be scale-agnostic, i.e. one can train over a continuous range of scales and subsequently query at arbitrary resolutions. Due to the difficulty of performing super-resolution on inherently noisy data, we analyze network behavior under multiple denoising strategies. Lastly we compare this method to a standard convolutional decoder using both quantitative metrics and a radiologist study implemented in Voxel, our newly developed tool for web-based evaluation of medical images.