 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Capsule Autoencoders for 3D Point Clouds
Paper and Code
Dec 06, 2019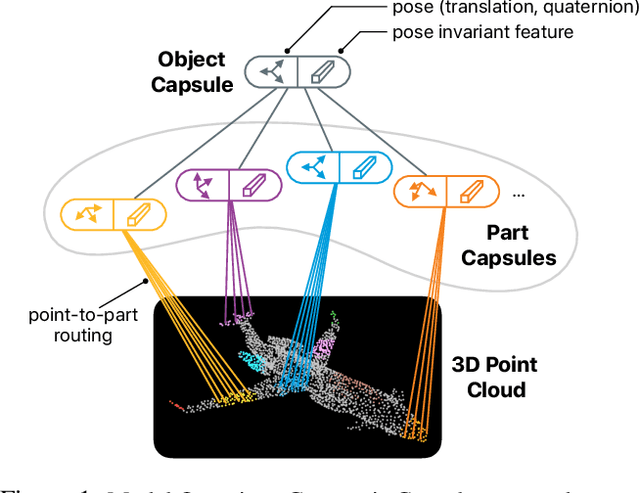


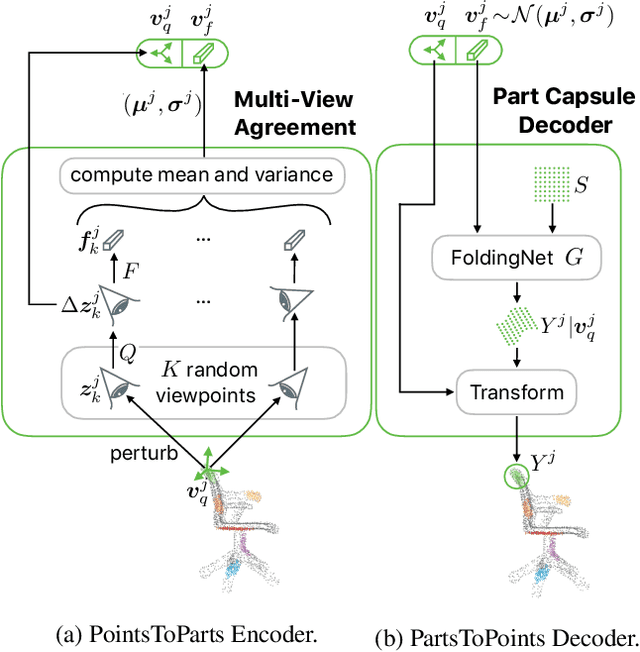
We propose a method to learn object representations from 3D point clouds using bundles of geometrically interpretable hidden units, which we call geometric capsules. Each geometric capsule represents a visual entity, such as an object or a part, and consists of two components: a pose and a feature. The pose encodes where the entity is, while the feature encodes what it is. We use these capsules to construct a Geometric Capsule Autoencoder that learns to group 3D points into parts (small local surfaces), and these parts into the whole object, in an unsupervised manner. Our novel Multi-View Agreement voting mechanism is used to discover an object's canonical pose and its pose-invariant feature vector. Using the ShapeNet and ModelNet40 datasets, we analyze the properties of the learned representations and show the benefits of having multiple votes agree. We perform alignment and retrieval of arbitrarily rotated objects -- tasks that evaluate our model's object identification and canonical pose recovery capabilities -- and obtained insightful results.