 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the generalization of learning-based 3D reconstruction
Paper and Code
Jun 27, 2020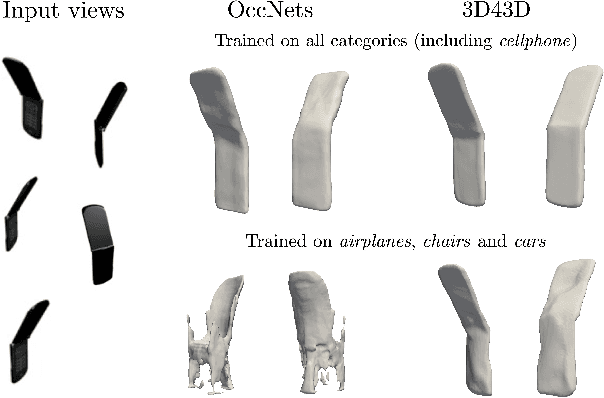


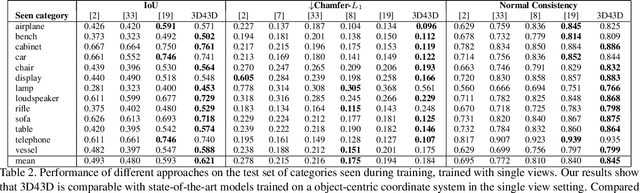
State-of-the-art learning-based monocular 3D reconstruction methods learn priors over object categories on the training set, and as a result struggle to achieve reasonable generalization to object categories unseen during training. In this paper we study the inductive biases encoded in the model architecture that impact the generalization of learning-based 3D reconstruction methods. We find that 3 inductive biases impact performance: the spatial extent of the encoder, the use of the underlying geometry of the scene to describe point features, and the mechanism to aggregate information from multiple views. Additionally, we propose mechanisms to enforce those inductive biases: a point representation that is aware of camera position, and a variance cost to aggregate information across views. Our model achieves state-of-the-art results on the standard ShapeNet 3D reconstruction benchmark in various settings.