 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSAS-BENCH: Real-Time Evaluation of Visual Streaming Assistant Models
Apr 08, 2026Streaming vision-language models (VLMs) continuously generate responses given an instruction prompt and an online stream of input frames. This is a core mechanism for real-time visual assistants. Existing VLM frameworks predominantly assess models in offline settings. In contrast, the performance of a streaming VLM depends on additional metrics beyond pure video understanding, including proactiveness, which reflects the timeliness of the model's responses, and consistency, which captures the robustness of its responses over time. To address this limitation, we propose VSAS-Bench, a new framework and benchmark for Visual Streaming Assistants. In contrast to prior benchmarks that primarily employ single-turn question answering on video inputs, VSAS-Bench features temporally dense annotations with over 18,000 annotations across diverse input domains and task types. We introduce standardized synchronous and asynchronous evaluation protocols, along with metrics that isolate and measure distinct capabilities of streaming VLMs. Using this framework, we conduct large-scale evaluations of recent video and streaming VLMs, analyzing the accuracy-latency trade-off under key design factors such as memory buffer length, memory access policy, and input resolution, yielding several practical insights. Finally, we show empirically that conventional VLMs can be adapted to streaming settings without additional training, and demonstrate that these adapted models outperform recent streaming VLMs. For example, Qwen3-VL-4B surpasses Dispider, the best streaming VLM on our benchmark, by 3% under the asynchronous protocol. The benchmark and code will be available at https://github.com/apple/ml-vsas-bench.
Learning to Reason for Hallucination Span Detection
Oct 02, 2025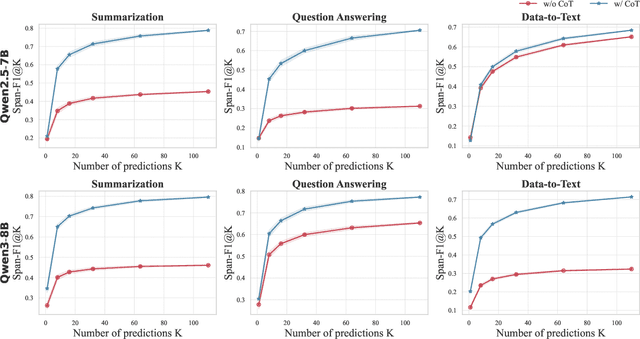
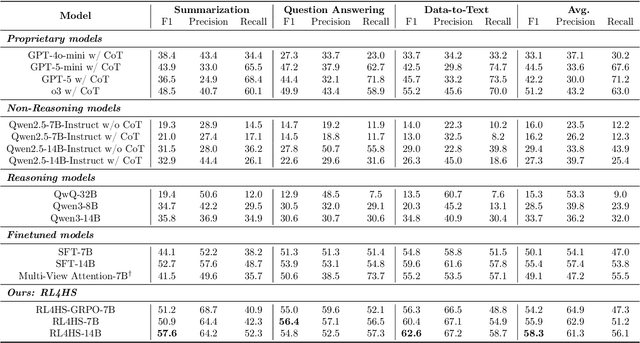
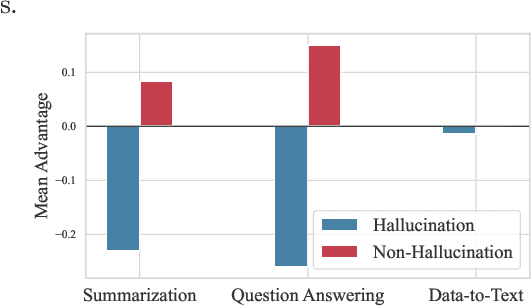
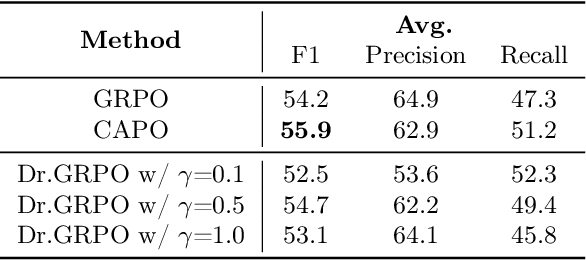
Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
MobileCLIP2: Improving Multi-Modal Reinforced Training
Aug 28, 2025Foundation image-text models such as CLIP with zero-shot capabilities enable a wide array of applications. MobileCLIP is a recent family of image-text models at 3-15ms latency and 50-150M parameters with state-of-the-art zero-shot accuracy. The main ingredients in MobileCLIP were its low-latency and light architectures and a novel multi-modal reinforced training that made knowledge distillation from multiple caption-generators and CLIP teachers efficient, scalable, and reproducible. In this paper, we improve the multi-modal reinforced training of MobileCLIP through: 1) better CLIP teacher ensembles trained on the DFN dataset, 2) improved captioner teachers trained on the DFN dataset and fine-tuned on a diverse selection of high-quality image-caption datasets. We discover new insights through ablations such as the importance of temperature tuning in contrastive knowledge distillation, the effectiveness of caption-generator fine-tuning for caption diversity, and the additive improvement from combining synthetic captions generated by multiple models. We train a new family of models called MobileCLIP2 and achieve state-of-the-art ImageNet-1k zero-shot accuracies at low latencies. In particular, we observe 2.2% improvement in ImageNet-1k accuracy for MobileCLIP2-B compared with MobileCLIP-B architecture. Notably, MobileCLIP2-S4 matches the zero-shot accuracy of SigLIP-SO400M/14 on ImageNet-1k while being 2$\times$ smaller and improves on DFN ViT-L/14 at 2.5$\times$ lower latency. We release our pretrained models (https://github.com/apple/ml-mobileclip) and the data generation code (https://github.com/apple/ml-mobileclip-dr). The data generation code makes it easy to create new reinforced datasets with arbitrary teachers using distributed scalable processing.
FastVLM: Efficient Vision Encoding for Vision Language Models
Dec 17, 2024



Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency caused by stacked self-attention layers. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing the number of visual tokens passed to the LLM, thereby lowering overall latency. Based on a comprehensive efficiency analysis of the interplay between image resolution, vision latency, token count, and LLM size, we introduce FastVLM, a model that achieves an optimized trade-off between latency, model size and accuracy. FastVLM incorporates FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images. Unlike previous methods, FastVLM achieves the optimal balance between visual token count and image resolution solely by scaling the input image, eliminating the need for additional token pruning and simplifying the model design. In the LLaVA-1.5 setup, FastVLM achieves 3.2$\times$ improvement in time-to-first-token (TTFT) while maintaining similar performance on VLM benchmarks compared to prior works. Compared to LLaVa-OneVision at the highest resolution (1152$\times$1152), FastVLM achieves comparable performance on key benchmarks like SeedBench and MMMU, using the same 0.5B LLM, but with 85$\times$ faster TTFT and a vision encoder that is 3.4$\times$ smaller.
Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum
May 21, 2024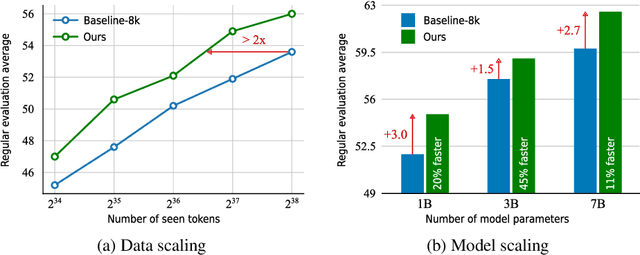
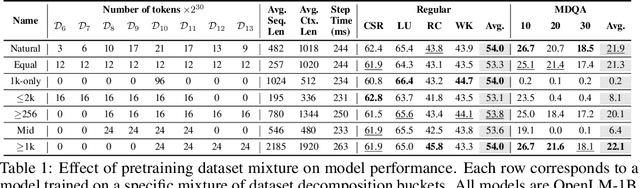
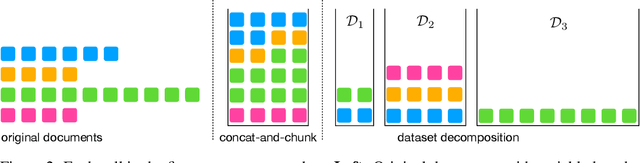
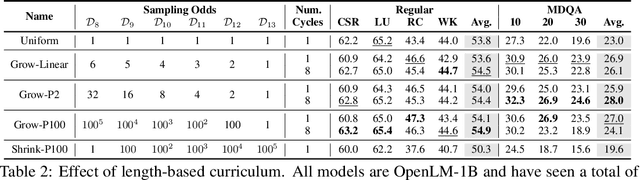
Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length. However, this method of concatenation can lead to cross-document attention within a sequence, which is neither a desirable learning signal nor computationally efficient. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a penalty proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy 3x faster compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.
Body Lift and Drag for a Legged Millirobot in Compliant Beam Environment
Apr 19, 2019
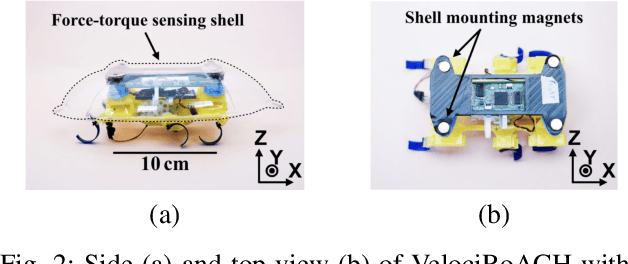
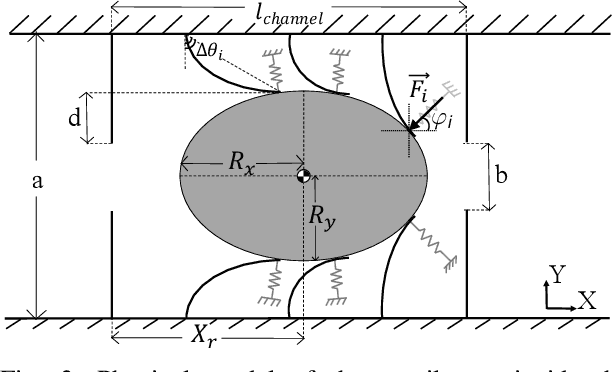
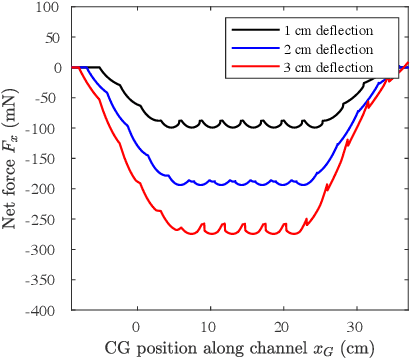
Much current study of legged locomotion has rightly focused on foot traction forces, including on granular media. Future legged millirobots will need to go through terrain, such as brush or other vegetation, where the body contact forces significantly affect locomotion. In this work, a (previously developed) low-cost 6-axis force/torque sensing shell is used to measure the interaction forces between a hexapedal millirobot and a set of compliant beams, which act as a surrogate for a densely cluttered environment. Experiments with a VelociRoACH robotic platform are used to measure lift and drag forces on the tactile shell, where negative lift forces can increase traction, even while drag forces increase. The drag energy and specific resistance required to pass through dense terrains can be measured. Furthermore, some contact between the robot and the compliant beams can lower specific resistance of locomotion. For small, light-weight legged robots in the beam environment, the body motion depends on both leg-ground and body-beam forces. A shell-shape which reduces drag but increases negative lift, such as the half-ellipsoid used, is suggested to be advantageous for robot locomotion in this type of environment.