 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Risk Minimisation for Cross-Organism Inference: Substituting Mouse Data for Human Data in Human Risk Factor Discovery
Paper and Code
Nov 14, 2021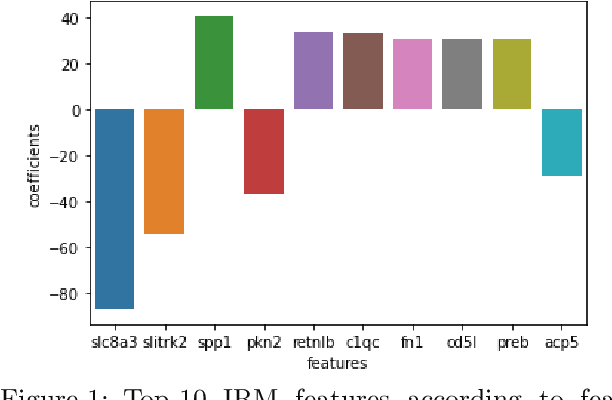
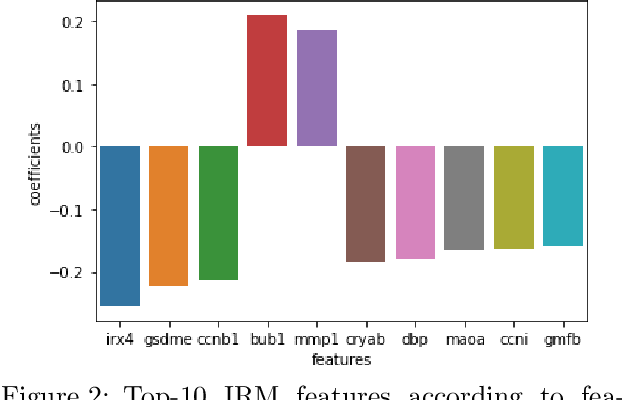
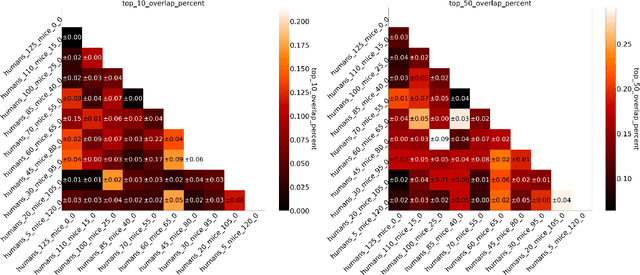
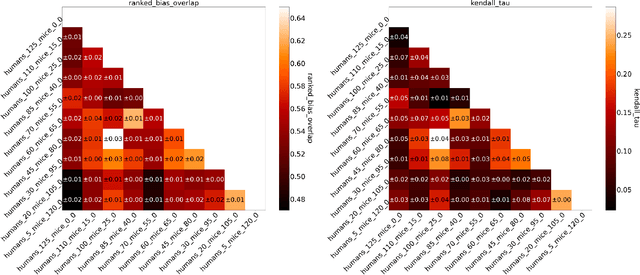
Human medical data can be challenging to obtain due to data privacy concerns, difficulties conducting certain types of experiments, or prohibitive associated costs. In many settings, data from animal models or in-vitro cell lines are available to help augment our understanding of human data. However, this data is known for having low etiological validity in comparison to human data. In this work, we augment small human medical datasets with in-vitro data and animal models. We use Invariant Risk Minimisation (IRM) to elucidate invariant features by considering cross-organism data as belonging to different data-generating environments. Our models identify genes of relevance to human cancer development. We observe a degree of consistency between varying the amounts of human and mouse data used, however, further work is required to obtain conclusive insights. As a secondary contribution, we enhance existing open source datasets and provide two uniformly processed, cross-organism, homologue gene-matched datasets to the community.