 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLife, Machine Learning, and the Search for Habitability: Predicting Biosignature Fluxes for the Habitable Worlds Observatory
Jan 18, 2026Future direct-imaging flagship missions, such as NASA's Habitable Worlds Observatory (HWO), face critical decisions in prioritizing observations due to extremely stringent time and resource constraints. In this paper, we introduce two advanced machine-learning architectures tailored for predicting biosignature species fluxes from exoplanetary reflected-light spectra: a Bayesian Convolutional Neural Network (BCNN) and our novel model architecture, the Spectral Query Adaptive Transformer (SQuAT). The BCNN robustly quantifies both epistemic and aleatoric uncertainties, offering reliable predictions under diverse observational conditions, whereas SQuAT employs query-driven attention mechanisms to enhance interpretability by explicitly associating spectral features with specific biosignature species. We demonstrate that both models achieve comparably high predictive accuracy on an augmented dataset spanning a wide range of exoplanetary conditions, while highlighting their distinct advantages in uncertainty quantification and spectral interpretability. These capabilities position our methods as promising tools for accelerating target triage, optimizing observation schedules, and maximizing scientific return for upcoming flagship missions such as HWO.
Integrating Machine Learning for Planetary Science: Perspectives for the Next Decade
Jul 29, 2020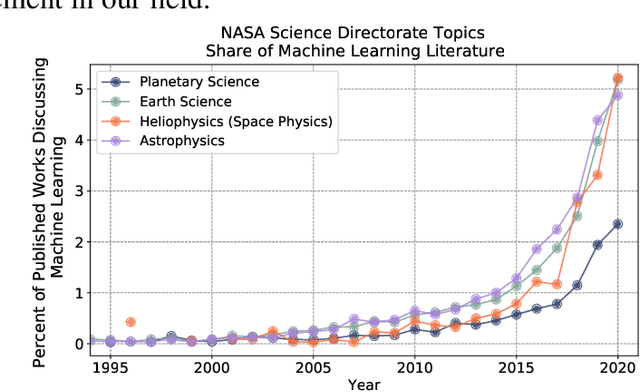
Machine learning (ML) methods can expand our ability to construct, and draw insight from large datasets. Despite the increasing volume of planetary observations, our field has seen few applications of ML in comparison to other sciences. To support these methods, we propose ten recommendations for bolstering a data-rich future in planetary science.
An Ensemble of Bayesian Neural Networks for Exoplanetary Atmospheric Retrieval
May 25, 2019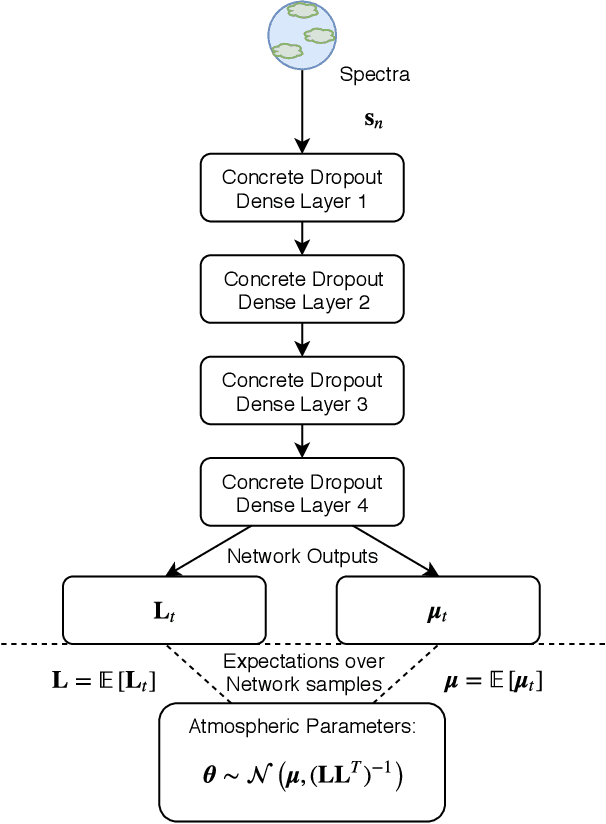
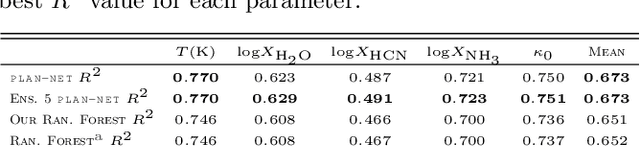
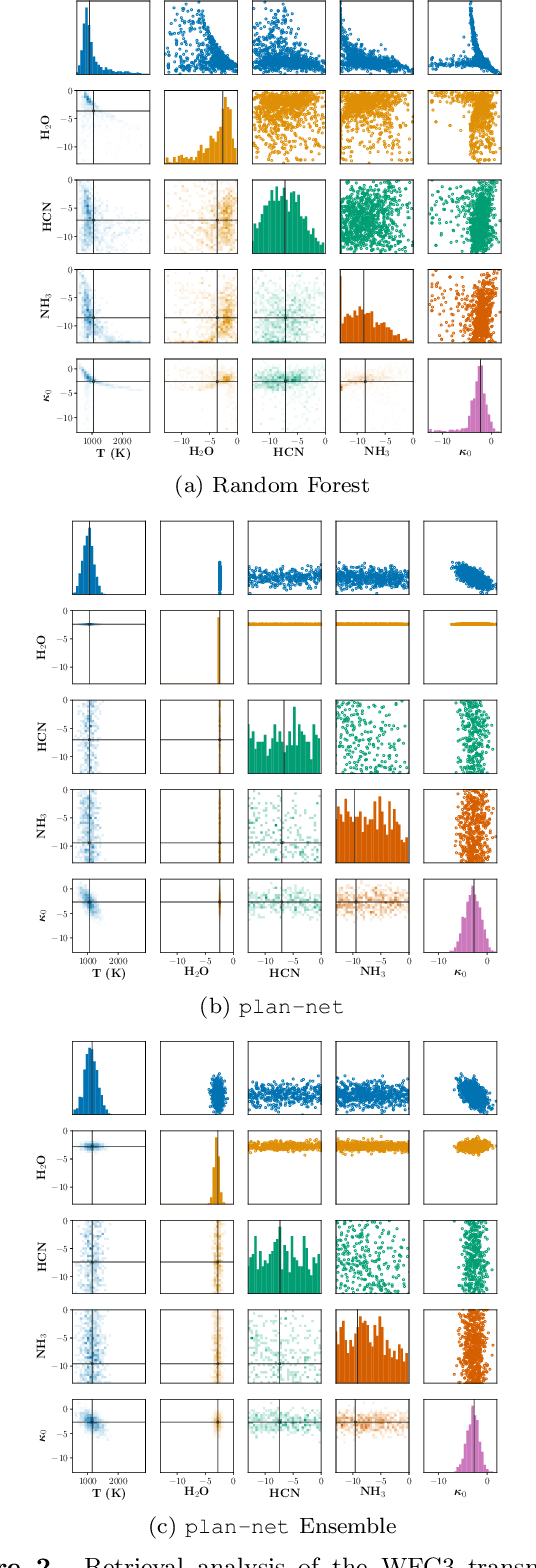

Machine learning is now used in many areas of astrophysics, from detecting exoplanets in Kepler transit signals to removing telescope systematics. Recent work demonstrated the potential of using machine learning algorithms for atmospheric retrieval by implementing a random forest to perform retrievals in seconds that are consistent with the traditional, computationally-expensive nested-sampling retrieval method. We expand upon their approach by presenting a new machine learning model, \texttt{plan-net}, based on an ensemble of Bayesian neural networks that yields more accurate inferences than the random forest for the same data set of synthetic transmission spectra. We demonstrate that an ensemble provides greater accuracy and more robust uncertainties than a single model. In addition to being the first to use Bayesian neural networks for atmospheric retrieval, we also introduce a new loss function for Bayesian neural networks that learns correlations between the model outputs. Importantly, we show that designing machine learning models to explicitly incorporate domain-specific knowledge both improves performance and provides additional insight by inferring the covariance of the retrieved atmospheric parameters. We apply \texttt{plan-net} to the Hubble Space Telescope Wide Field Camera 3 transmission spectrum for WASP-12b and retrieve an isothermal temperature and water abundance consistent with the literature. We highlight that our method is flexible and can be expanded to higher-resolution spectra and a larger number of atmospheric parameters.
Bayesian Deep Learning for Exoplanet Atmospheric Retrieval
Dec 02, 2018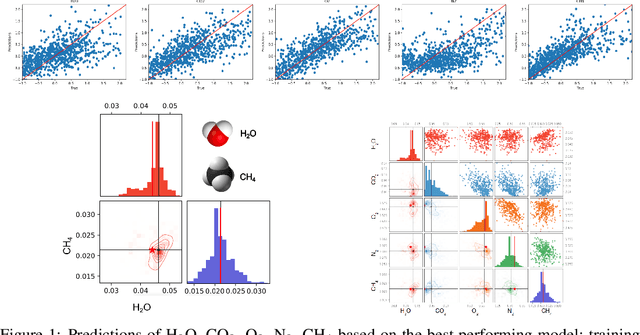

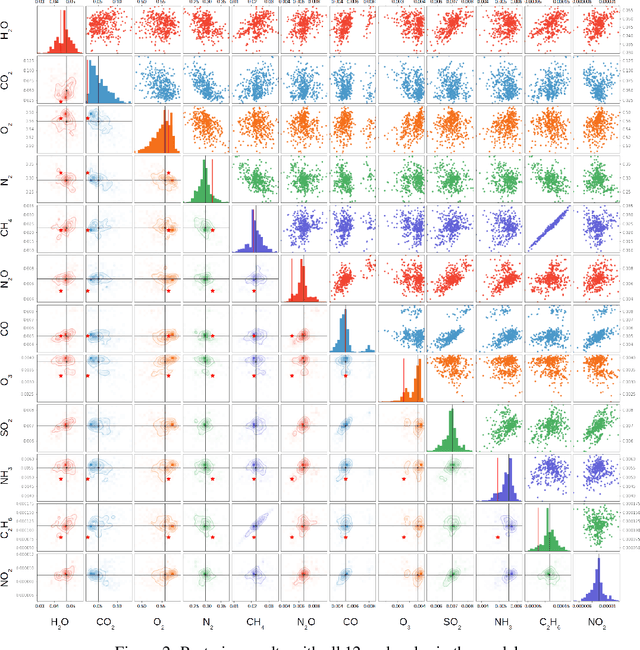
Over the past decade, the study of extrasolar planets has evolved rapidly from plain detection and identification to comprehensive categorization and characterization of exoplanet systems and their atmospheres. Atmospheric retrieval, the inverse modeling technique used to determine an exoplanetary atmosphere's temperature structure and composition from an observed spectrum, is both time-consuming and compute-intensive, requiring complex algorithms that compare thousands to millions of atmospheric models to the observational data to find the most probable values and associated uncertainties for each model parameter. For rocky, terrestrial planets, the retrieved atmospheric composition can give insight into the surface fluxes of gaseous species necessary to maintain the stability of that atmosphere, which may in turn provide insight into the geological and/or biological processes active on the planet. These atmospheres contain many molecules, some of them biosignatures, spectral fingerprints indicative of biological activity, which will become observable with the next generation of telescopes. Runtimes of traditional retrieval models scale with the number of model parameters, so as more molecular species are considered, runtimes can become prohibitively long. Recent advances in machine learning (ML) and computer vision offer new ways to reduce the time to perform a retrieval by orders of magnitude, given a sufficient data set to train with. Here we present an ML-based retrieval framework called Intelligent exoplaNet Atmospheric RetrievAl (INARA) that consists of a Bayesian deep learning model for retrieval and a data set of 3,000,000 synthetic rocky exoplanetary spectra generated using the NASA Planetary Spectrum Generator. Our work represents the first ML retrieval model for rocky, terrestrial exoplanets and the first synthetic data set of terrestrial spectra generated at this scale.