 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterminants of Training Corpus Size for Clinical Text Classification
Jan 22, 2026Introduction: Clinical text classification using natural language processing (NLP) models requires adequate training data to achieve optimal performance. For that, 200-500 documents are typically annotated. The number is constrained by time and costs and lacks justification of the sample size requirements and their relationship to text vocabulary properties. Methods: Using the publicly available MIMIC-III dataset containing hospital discharge notes with ICD-9 diagnoses as labels, we employed pre-trained BERT embeddings followed by Random Forest classifiers to identify 10 randomly selected diagnoses, varying training corpus sizes from 100 to 10,000 documents, and analyzed vocabulary properties by identifying strong and noisy predictive words through Lasso logistic regression on bag-of-words embeddings. Results: Learning curves varied significantly across the 10 classification tasks despite identical preprocessing and algorithms, with 600 documents sufficient to achieve 95% of the performance attainable with 10,000 documents for all tasks. Vocabulary analysis revealed that more strong predictors and fewer noisy predictors were associated with steeper learning curves, where every 100 additional noisy words decreased accuracy by approximately 0.02 while 100 additional strong predictors increased maximum accuracy by approximately 0.04.
RealMedQA: A pilot biomedical question answering dataset containing realistic clinical questions
Aug 16, 2024Clinical question answering systems have the potential to provide clinicians with relevant and timely answers to their questions. Nonetheless, despite the advances that have been made, adoption of these systems in clinical settings has been slow. One issue is a lack of question-answering datasets which reflect the real-world needs of health professionals. In this work, we present RealMedQA, a dataset of realistic clinical questions generated by humans and an LLM. We describe the process for generating and verifying the QA pairs and assess several QA models on BioASQ and RealMedQA to assess the relative difficulty of matching answers to questions. We show that the LLM is more cost-efficient for generating "ideal" QA pairs. Additionally, we achieve a lower lexical similarity between questions and answers than BioASQ which provides an additional challenge to the top two QA models, as per the results. We release our code and our dataset publicly to encourage further research.
Question answering systems for health professionals at the point of care -- a systematic review
Jan 24, 2024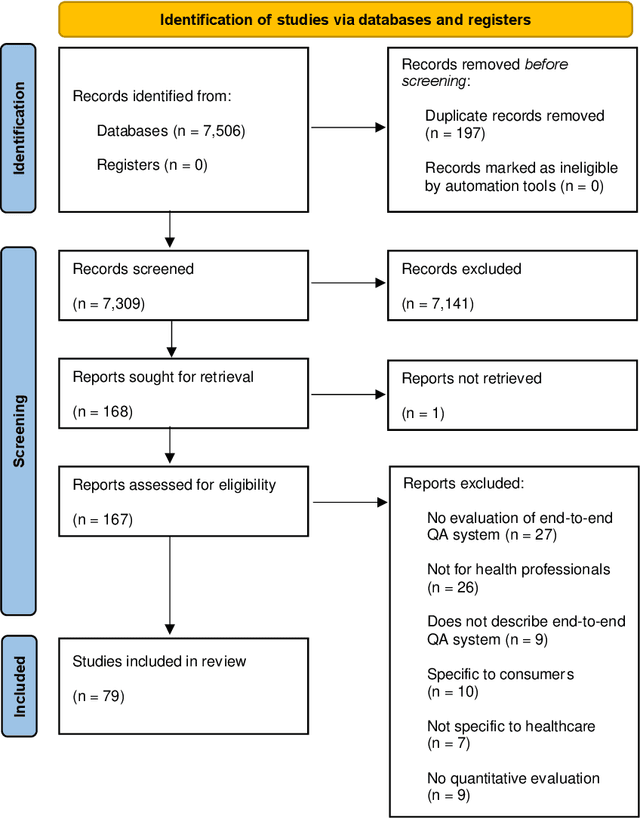
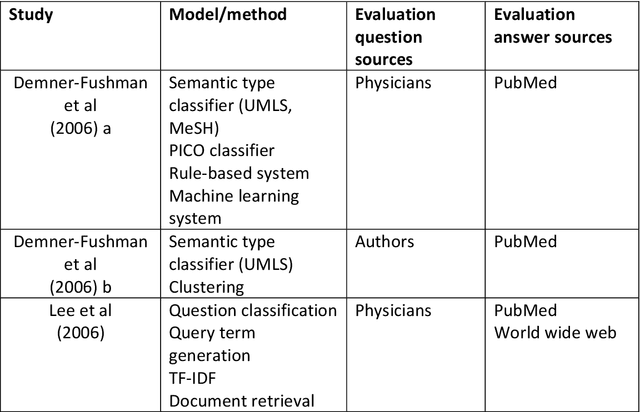
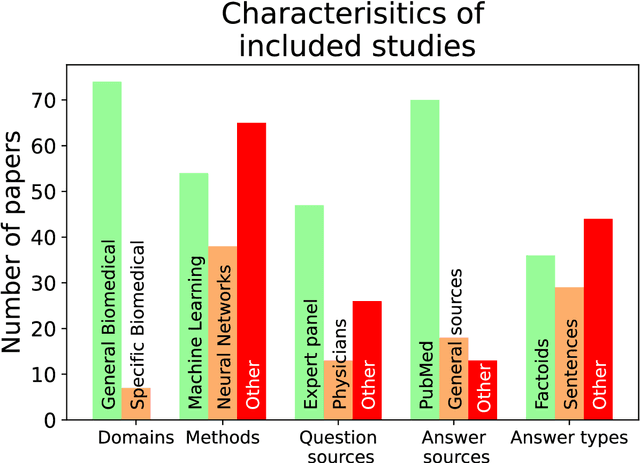

Objective: Question answering (QA) systems have the potential to improve the quality of clinical care by providing health professionals with the latest and most relevant evidence. However, QA systems have not been widely adopted. This systematic review aims to characterize current medical QA systems, assess their suitability for healthcare, and identify areas of improvement. Materials and methods: We searched PubMed, IEEE Xplore, ACM Digital Library, ACL Anthology and forward and backward citations on 7th February 2023. We included peer-reviewed journal and conference papers describing the design and evaluation of biomedical QA systems. Two reviewers screened titles, abstracts, and full-text articles. We conducted a narrative synthesis and risk of bias assessment for each study. We assessed the utility of biomedical QA systems. Results: We included 79 studies and identified themes, including question realism, answer reliability, answer utility, clinical specialism, systems, usability, and evaluation methods. Clinicians' questions used to train and evaluate QA systems were restricted to certain sources, types and complexity levels. No system communicated confidence levels in the answers or sources. Many studies suffered from high risks of bias and applicability concerns. Only 8 studies completely satisfied any criterion for clinical utility, and only 7 reported user evaluations. Most systems were built with limited input from clinicians. Discussion: While machine learning methods have led to increased accuracy, most studies imperfectly reflected real-world healthcare information needs. Key research priorities include developing more realistic healthcare QA datasets and considering the reliability of answer sources, rather than merely focusing on accuracy.
Sample Size in Natural Language Processing within Healthcare Research
Sep 05, 2023



Sample size calculation is an essential step in most data-based disciplines. Large enough samples ensure representativeness of the population and determine the precision of estimates. This is true for most quantitative studies, including those that employ machine learning methods, such as natural language processing, where free-text is used to generate predictions and classify instances of text. Within the healthcare domain, the lack of sufficient corpora of previously collected data can be a limiting factor when determining sample sizes for new studies. This paper tries to address the issue by making recommendations on sample sizes for text classification tasks in the healthcare domain. Models trained on the MIMIC-III database of critical care records from Beth Israel Deaconess Medical Center were used to classify documents as having or not having Unspecified Essential Hypertension, the most common diagnosis code in the database. Simulations were performed using various classifiers on different sample sizes and class proportions. This was repeated for a comparatively less common diagnosis code within the database of diabetes mellitus without mention of complication. Smaller sample sizes resulted in better results when using a K-nearest neighbours classifier, whereas larger sample sizes provided better results with support vector machines and BERT models. Overall, a sample size larger than 1000 was sufficient to provide decent performance metrics. The simulations conducted within this study provide guidelines that can be used as recommendations for selecting appropriate sample sizes and class proportions, and for predicting expected performance, when building classifiers for textual healthcare data. The methodology used here can be modified for sample size estimates calculations with other datasets.
Development of a Knowledge Graph Embeddings Model for Pain
Aug 17, 2023



Pain is a complex concept that can interconnect with other concepts such as a disorder that might cause pain, a medication that might relieve pain, and so on. To fully understand the context of pain experienced by either an individual or across a population, we may need to examine all concepts related to pain and the relationships between them. This is especially useful when modeling pain that has been recorded in electronic health records. Knowledge graphs represent concepts and their relations by an interlinked network, enabling semantic and context-based reasoning in a computationally tractable form. These graphs can, however, be too large for efficient computation. Knowledge graph embeddings help to resolve this by representing the graphs in a low-dimensional vector space. These embeddings can then be used in various downstream tasks such as classification and link prediction. The various relations associated with pain which are required to construct such a knowledge graph can be obtained from external medical knowledge bases such as SNOMED CT, a hierarchical systematic nomenclature of medical terms. A knowledge graph built in this way could be further enriched with real-world examples of pain and its relations extracted from electronic health records. This paper describes the construction of such knowledge graph embedding models of pain concepts, extracted from the unstructured text of mental health electronic health records, combined with external knowledge created from relations described in SNOMED CT, and their evaluation on a subject-object link prediction task. The performance of the models was compared with other baseline models.
Identifying Mentions of Pain in Mental Health Records Text: A Natural Language Processing Approach
Apr 05, 2023

Pain is a common reason for accessing healthcare resources and is a growing area of research, especially in its overlap with mental health. Mental health electronic health records are a good data source to study this overlap. However, much information on pain is held in the free text of these records, where mentions of pain present a unique natural language processing problem due to its ambiguous nature. This project uses data from an anonymised mental health electronic health records database. The data are used to train a machine learning based classification algorithm to classify sentences as discussing patient pain or not. This will facilitate the extraction of relevant pain information from large databases, and the use of such outputs for further studies on pain and mental health. 1,985 documents were manually triple-annotated for creation of gold standard training data, which was used to train three commonly used classification algorithms. The best performing model achieved an F1-score of 0.98 (95% CI 0.98-0.99).
Multi-domain Clinical Natural Language Processing with MedCAT: the Medical Concept Annotation Toolkit
Oct 02, 2020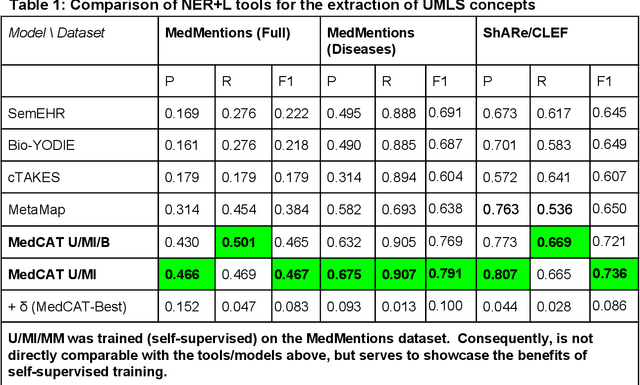
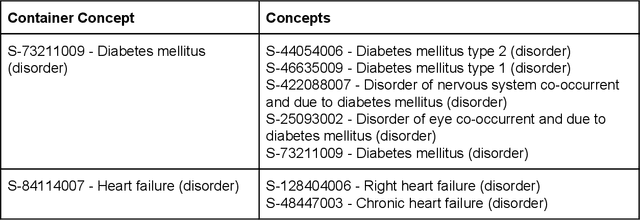
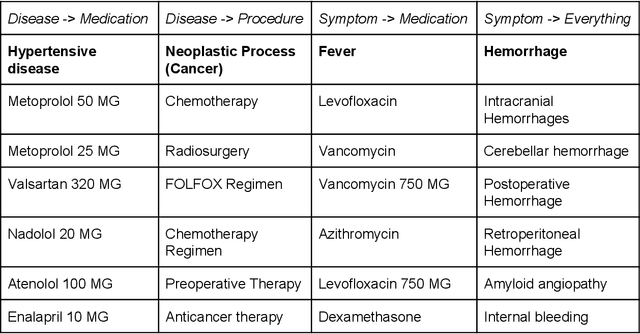
Electronic health records (EHR) contain large volumes of unstructured text, requiring the application of Information Extraction (IE) technologies to enable clinical analysis. We present the open source Medical Concept Annotation Toolkit (MedCAT) that provides: a) a novel self-supervised machine learning algorithm for extracting concepts using any concept vocabulary including UMLS/SNOMED-CT; b) a feature-rich annotation interface for customizing and training IE models; and c) integrations to the broader CogStack ecosystem for vendor-agnostic health system deployment. We show improved performance in extracting UMLS concepts from open datasets ( F1 0.467-0.791 vs 0.384-0.691). Further real-world validation demonstrates SNOMED-CT extraction at 3 large London hospitals with self-supervised training over ~8.8B words from ~17M clinical records and further fine-tuning with ~6K clinician annotated examples. We show strong transferability ( F1 >0.94) between hospitals, datasets and concept types indicating cross-domain EHR-agnostic utility for accelerated clinical and research use cases.
Comparative Analysis of Text Classification Approaches in Electronic Health Records
May 08, 2020
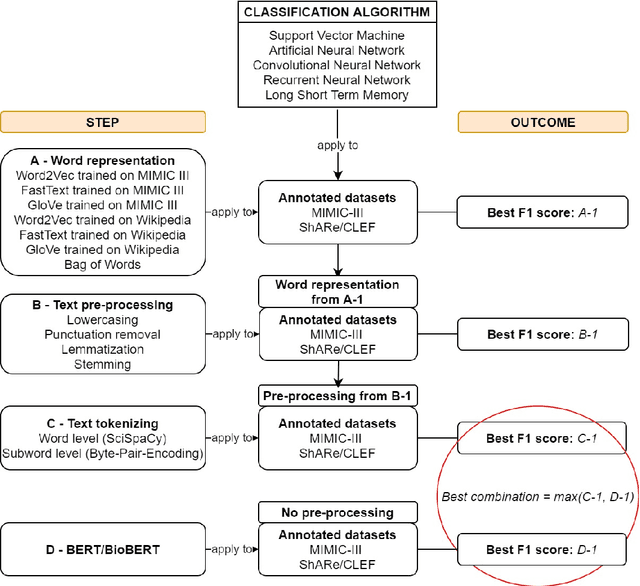

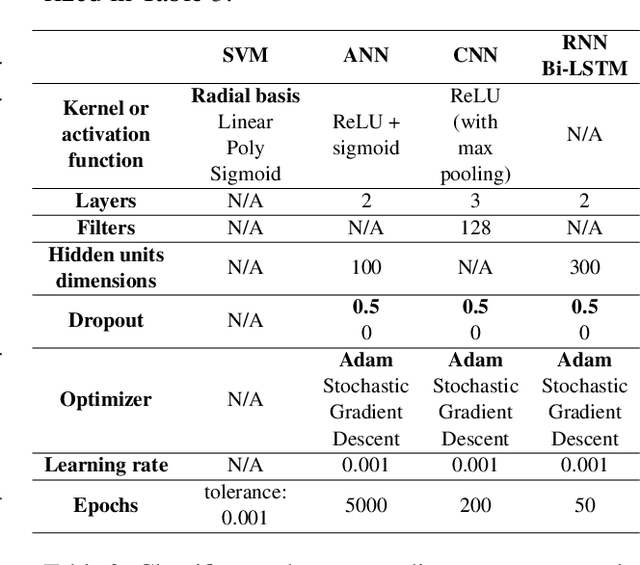
Text classification tasks which aim at harvesting and/or organizing information from electronic health records are pivotal to support clinical and translational research. However these present specific challenges compared to other classification tasks, notably due to the particular nature of the medical lexicon and language used in clinical records. Recent advances in embedding methods have shown promising results for several clinical tasks, yet there is no exhaustive comparison of such approaches with other commonly used word representations and classification models. In this work, we analyse the impact of various word representations, text pre-processing and classification algorithms on the performance of four different text classification tasks. The results show that traditional approaches, when tailored to the specific language and structure of the text inherent to the classification task, can achieve or exceed the performance of more recent ones based on contextual embeddings such as BERT.
Identifying physical health comorbidities in a cohort of individuals with severe mental illness: An application of SemEHR
Feb 07, 2020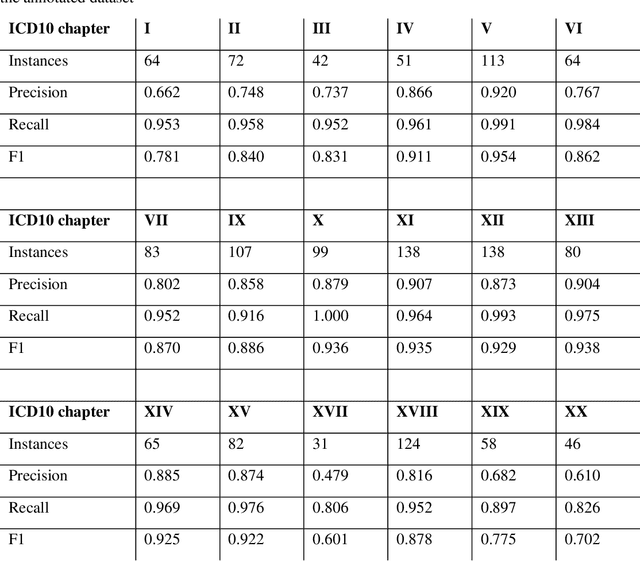
Multimorbidity research in mental health services requires data from physical health conditions which is traditionally limited in mental health care electronic health records. In this study, we aimed to extract data from physical health conditions from clinical notes using SemEHR. Data was extracted from Clinical Record Interactive Search (CRIS) system at South London and Maudsley Biomedical Research Centre (SLaM BRC) and the cohort consisted of all individuals who had received a primary or secondary diagnosis of severe mental illness between 2007 and 2018. Three pairs of annotators annotated 2403 documents with an average Cohen's Kappa of 0.757. Results show that the NLP performance varies across different diseases areas (F1 0.601 - 0.954) suggesting that the language patterns or terminologies of different condition groups entail different technical challenges to the same NLP task.
MedCAT -- Medical Concept Annotation Tool
Dec 18, 2019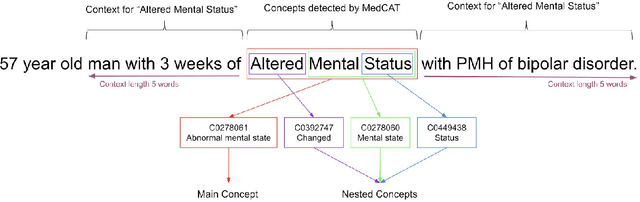
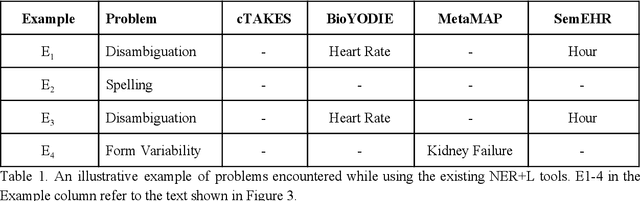
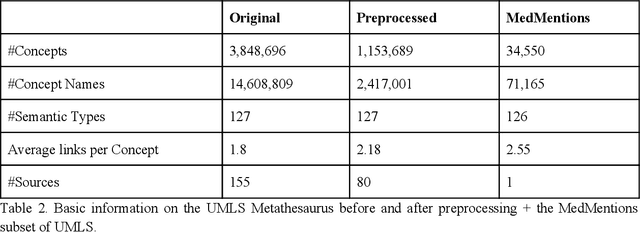
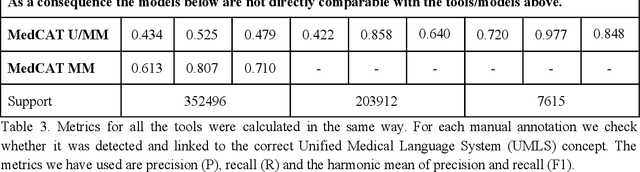
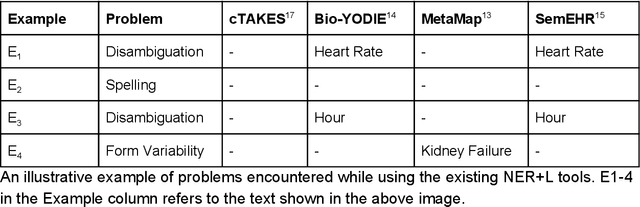
Biomedical documents such as Electronic Health Records (EHRs) contain a large amount of information in an unstructured format. The data in EHRs is a hugely valuable resource documenting clinical narratives and decisions, but whilst the text can be easily understood by human doctors it is challenging to use in research and clinical applications. To uncover the potential of biomedical documents we need to extract and structure the information they contain. The task at hand is Named Entity Recognition and Linking (NER+L). The number of entities, ambiguity of words, overlapping and nesting make the biomedical area significantly more difficult than many others. To overcome these difficulties, we have developed the Medical Concept Annotation Tool (MedCAT), an open-source unsupervised approach to NER+L. MedCAT uses unsupervised machine learning to disambiguate entities. It was validated on MIMIC-III (a freely accessible critical care database) and MedMentions (Biomedical papers annotated with mentions from the Unified Medical Language System). In case of NER+L, the comparison with existing tools shows that MedCAT improves the previous best with only unsupervised learning (F1=0.848 vs 0.691 for disease detection; F1=0.710 vs. 0.222 for general concept detection). A qualitative analysis of the vector embeddings learnt by MedCAT shows that it captures latent medical knowledge available in EHRs (MIMIC-III). Unsupervised learning can improve the performance of large scale entity extraction, but it has some limitations when working with only a couple of entities and a small dataset. In that case options are supervised learning or active learning, both of which are supported in MedCAT via the MedCATtrainer extension. Our approach can detect and link millions of different biomedical concepts with state-of-the-art performance, whilst being lightweight, fast and easy to use.