 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterminants of Training Corpus Size for Clinical Text Classification
Jan 22, 2026Introduction: Clinical text classification using natural language processing (NLP) models requires adequate training data to achieve optimal performance. For that, 200-500 documents are typically annotated. The number is constrained by time and costs and lacks justification of the sample size requirements and their relationship to text vocabulary properties. Methods: Using the publicly available MIMIC-III dataset containing hospital discharge notes with ICD-9 diagnoses as labels, we employed pre-trained BERT embeddings followed by Random Forest classifiers to identify 10 randomly selected diagnoses, varying training corpus sizes from 100 to 10,000 documents, and analyzed vocabulary properties by identifying strong and noisy predictive words through Lasso logistic regression on bag-of-words embeddings. Results: Learning curves varied significantly across the 10 classification tasks despite identical preprocessing and algorithms, with 600 documents sufficient to achieve 95% of the performance attainable with 10,000 documents for all tasks. Vocabulary analysis revealed that more strong predictors and fewer noisy predictors were associated with steeper learning curves, where every 100 additional noisy words decreased accuracy by approximately 0.02 while 100 additional strong predictors increased maximum accuracy by approximately 0.04.
Predicting Deterioration in Mild Cognitive Impairment with Survival Transformers, Extreme Gradient Boosting and Cox Proportional Hazard Modelling
Sep 24, 2024The paper proposes a novel approach of survival transformers and extreme gradient boosting models in predicting cognitive deterioration in individuals with mild cognitive impairment (MCI) using metabolomics data in the ADNI cohort. By leveraging advanced machine learning and transformer-based techniques applied in survival analysis, the proposed approach highlights the potential of these techniques for more accurate early detection and intervention in Alzheimer's dementia disease. This research also underscores the importance of non-invasive biomarkers and innovative modelling tools in enhancing the accuracy of dementia risk assessments, offering new avenues for clinical practice and patient care. A comprehensive Monte Carlo simulation procedure consisting of 100 repetitions of a nested cross-validation in which models were trained and evaluated, indicates that the survival machine learning models based on Transformer and XGBoost achieved the highest mean C-index performances, namely 0.85 and 0.8, respectively, and that they are superior to the conventional survival analysis Cox Proportional Hazards model which achieved a mean C-Index of 0.77. Moreover, based on the standard deviations of the C-Index performances obtained in the Monte Carlo simulation, we established that both survival machine learning models above are more stable than the conventional statistical model.
Sample Size in Natural Language Processing within Healthcare Research
Sep 05, 2023



Sample size calculation is an essential step in most data-based disciplines. Large enough samples ensure representativeness of the population and determine the precision of estimates. This is true for most quantitative studies, including those that employ machine learning methods, such as natural language processing, where free-text is used to generate predictions and classify instances of text. Within the healthcare domain, the lack of sufficient corpora of previously collected data can be a limiting factor when determining sample sizes for new studies. This paper tries to address the issue by making recommendations on sample sizes for text classification tasks in the healthcare domain. Models trained on the MIMIC-III database of critical care records from Beth Israel Deaconess Medical Center were used to classify documents as having or not having Unspecified Essential Hypertension, the most common diagnosis code in the database. Simulations were performed using various classifiers on different sample sizes and class proportions. This was repeated for a comparatively less common diagnosis code within the database of diabetes mellitus without mention of complication. Smaller sample sizes resulted in better results when using a K-nearest neighbours classifier, whereas larger sample sizes provided better results with support vector machines and BERT models. Overall, a sample size larger than 1000 was sufficient to provide decent performance metrics. The simulations conducted within this study provide guidelines that can be used as recommendations for selecting appropriate sample sizes and class proportions, and for predicting expected performance, when building classifiers for textual healthcare data. The methodology used here can be modified for sample size estimates calculations with other datasets.
A Machine Learning Approach for Predicting Deterioration in Alzheimer's Disease
Jun 17, 2023This paper explores deterioration in Alzheimers Disease using Machine Learning. Subjects were split into two datasets based on baseline diagnosis (Cognitively Normal, Mild Cognitive Impairment), with outcome of deterioration at final visit (a binomial essentially yes/no categorisation) using data from the Alzheimers Disease Neuroimaging Initiative (demographics, genetics, CSF, imaging, and neuropsychological testing etc). Six machine learning models, including gradient boosting, were built, and evaluated on these datasets using a nested crossvalidation procedure, with the best performing models being put through repeated nested cross-validation at 100 iterations. We were able to demonstrate good predictive ability using CART predicting which of those in the cognitively normal group deteriorated and received a worse diagnosis (AUC = 0.88). For the mild cognitive impairment group, we were able to achieve good predictive ability for deterioration with Elastic Net (AUC = 0.76).
Predicting Risk of Dementia with Survival Machine Learning and Statistical Methods: Results on the English Longitudinal Study of Ageing Cohort
Jun 17, 2023Machine learning models that aim to predict dementia onset usually follow the classification methodology ignoring the time until an event happens. This study presents an alternative, using survival analysis within the context of machine learning techniques. Two survival method extensions based on machine learning algorithms of Random Forest and Elastic Net are applied to train, optimise, and validate predictive models based on the English Longitudinal Study of Ageing ELSA cohort. The two survival machine learning models are compared with the conventional statistical Cox proportional hazard model, proving their superior predictive capability and stability on the ELSA data, as demonstrated by computationally intensive procedures such as nested cross-validation and Monte Carlo validation. This study is the first to apply survival machine learning to the ELSA data, and demonstrates in this case the superiority of AI based predictive modelling approaches over the widely employed Cox statistical approach in survival analysis. Implications, methodological considerations, and future research directions are discussed.
Predicting Alzheimers Disease Diagnosis Risk over Time with Survival Machine Learning on the ADNI Cohort
Jun 17, 2023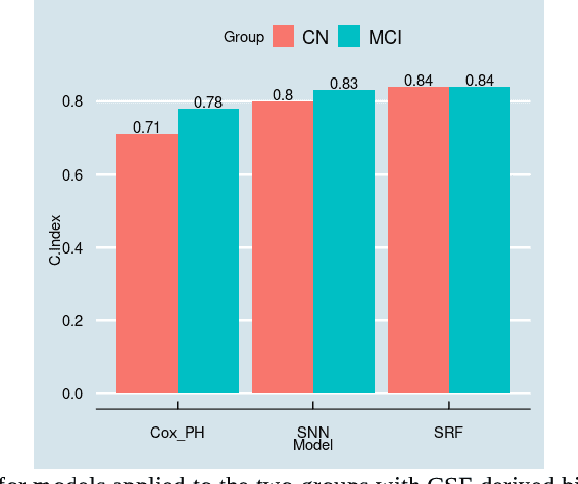



The rise of Alzheimers Disease worldwide has prompted a search for efficient tools which can be used to predict deterioration in cognitive decline leading to dementia. In this paper, we explore the potential of survival machine learning as such a tool for building models capable of predicting not only deterioration but also the likely time to deterioration. We demonstrate good predictive ability (0.86 C-Index), lending support to its use in clinical investigation and prediction of Alzheimers Disease risk.