 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForesight -- Deep Generative Modelling of Patient Timelines using Electronic Health Records
Dec 13, 2022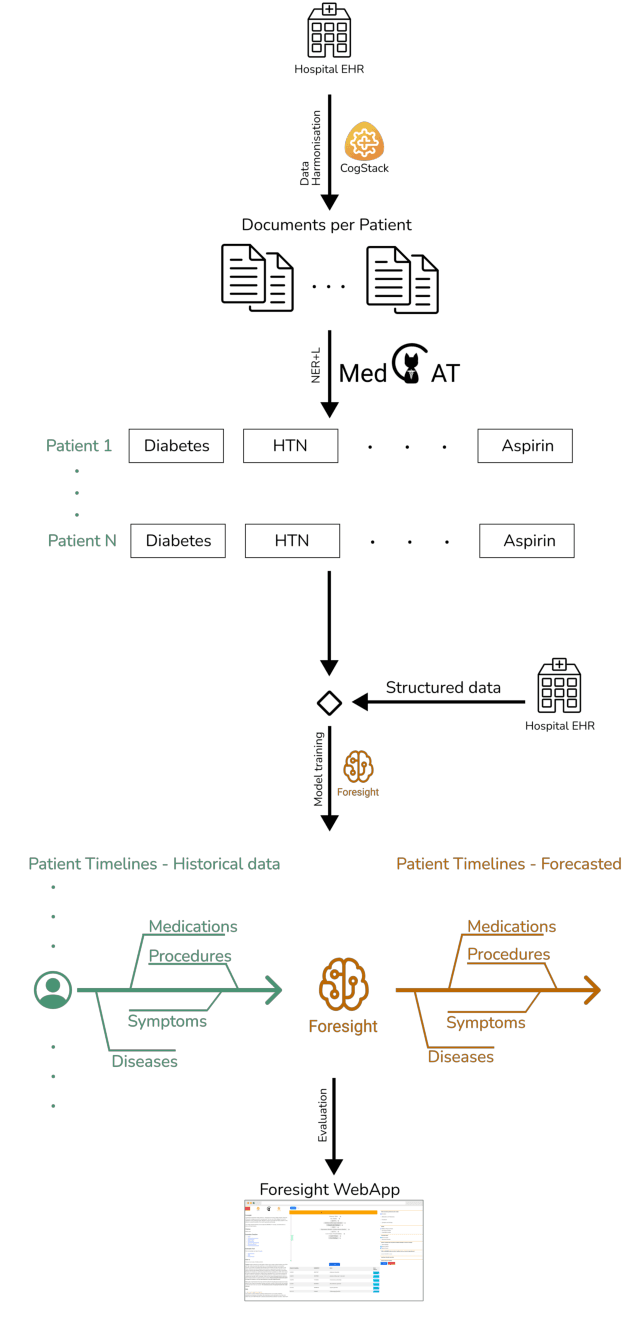
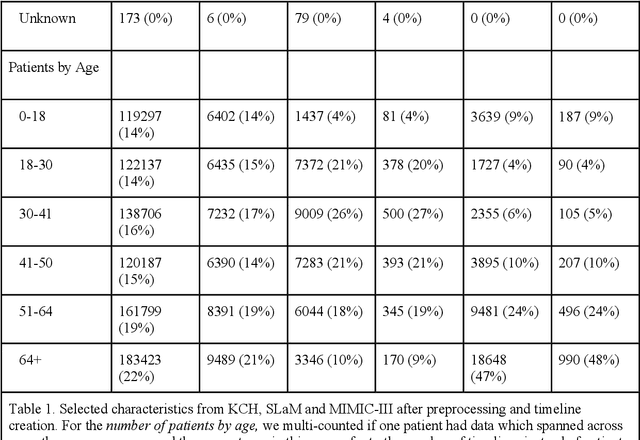
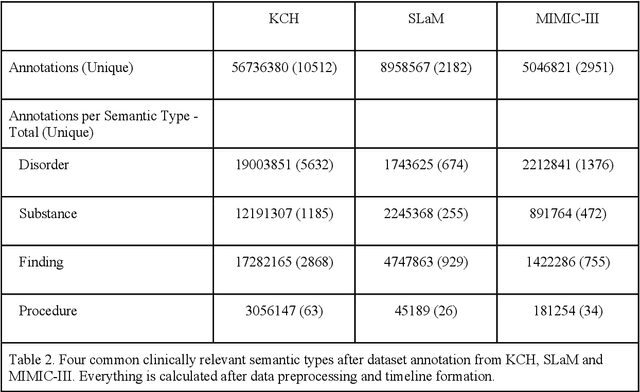
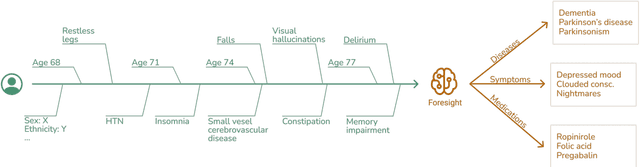
Electronic Health Records (EHRs) hold detailed longitudinal information about each patient's health status and general clinical history, a large portion of which is stored within the unstructured text. Temporal modelling of this medical history, which considers the sequence of events, can be used to forecast and simulate future events, estimate risk, suggest alternative diagnoses or forecast complications. While most prediction approaches use mainly structured data or a subset of single-domain forecasts and outcomes, we processed the entire free-text portion of EHRs for longitudinal modelling. We present Foresight, a novel GPT3-based pipeline that uses NER+L tools (i.e. MedCAT) to convert document text into structured, coded concepts, followed by providing probabilistic forecasts for future medical events such as disorders, medications, symptoms and interventions. Since large portions of EHR data are in text form, such an approach benefits from a granular and detailed view of a patient while introducing modest additional noise. On tests in two large UK hospitals (King's College Hospital, South London and Maudsley) and the US MIMIC-III dataset precision@10 of 0.80, 0.81 and 0.91 was achieved for forecasting the next biomedical concept. Foresight was also validated on 34 synthetic patient timelines by 5 clinicians and achieved relevancy of 97% for the top forecasted candidate disorder. Foresight can be easily trained and deployed locally as it only requires free-text data (as a minimum). As a generative model, it can simulate follow-on disorders, medications and interventions for as many steps as required. Foresight is a general-purpose model for biomedical concept modelling that can be used for real-world risk estimation, virtual trials and clinical research to study the progression of diseases, simulate interventions and counterfactuals, and for educational purposes.
MedGPT: Medical Concept Prediction from Clinical Narratives
Jul 07, 2021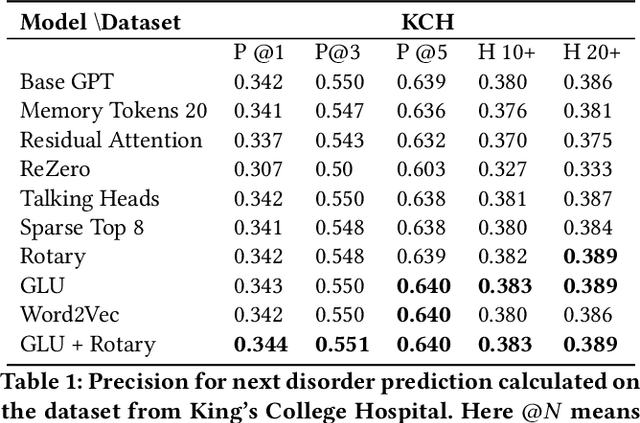
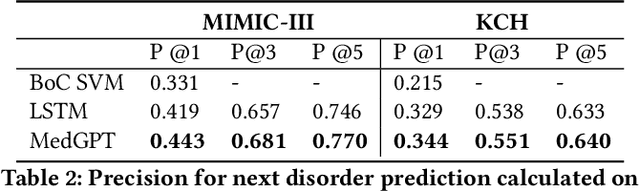
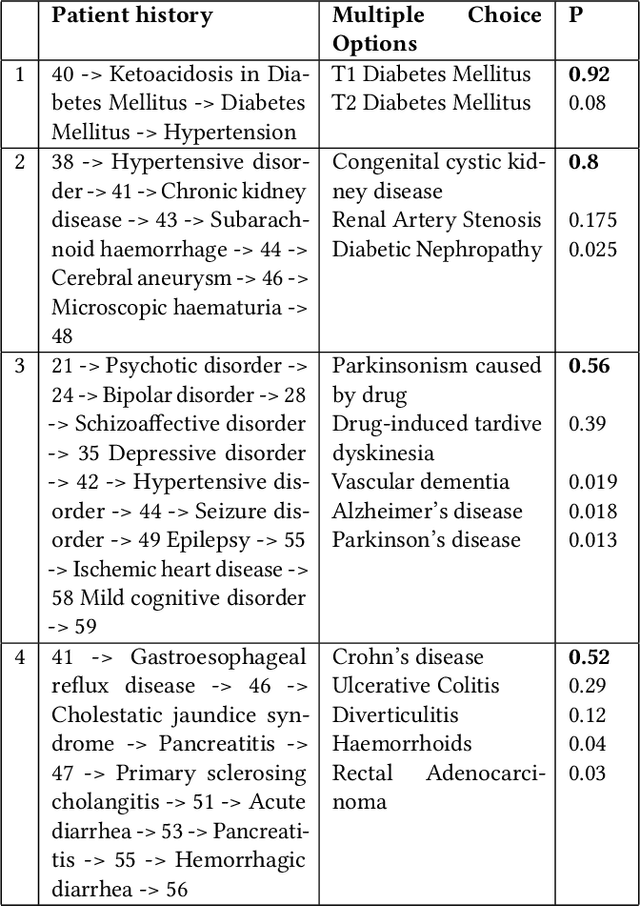
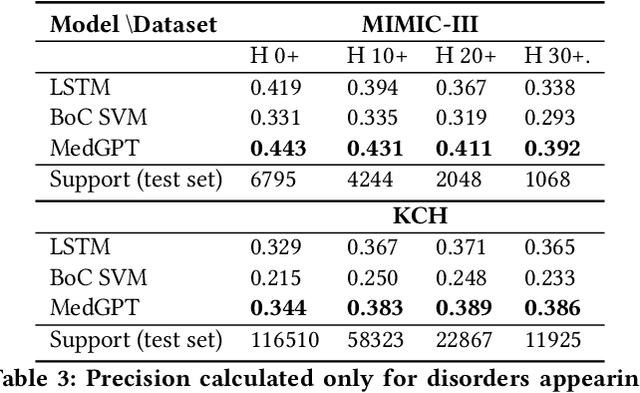
The data available in Electronic Health Records (EHRs) provides the opportunity to transform care, and the best way to provide better care for one patient is through learning from the data available on all other patients. Temporal modelling of a patient's medical history, which takes into account the sequence of past events, can be used to predict future events such as a diagnosis of a new disorder or complication of a previous or existing disorder. While most prediction approaches use mostly the structured data in EHRs or a subset of single-domain predictions and outcomes, we present MedGPT a novel transformer-based pipeline that uses Named Entity Recognition and Linking tools (i.e. MedCAT) to structure and organize the free text portion of EHRs and anticipate a range of future medical events (initially disorders). Since a large portion of EHR data is in text form, such an approach benefits from a granular and detailed view of a patient while introducing modest additional noise. MedGPT effectively deals with the noise and the added granularity, and achieves a precision of 0.344, 0.552 and 0.640 (vs LSTM 0.329, 0.538 and 0.633) when predicting the top 1, 3 and 5 candidate future disorders on real world hospital data from King's College Hospital, London, UK (\textasciitilde600k patients). We also show that our model captures medical knowledge by testing it on an experimental medical multiple choice question answering task, and by examining the attentional focus of the model using gradient-based saliency methods.
Multi-domain Clinical Natural Language Processing with MedCAT: the Medical Concept Annotation Toolkit
Oct 02, 2020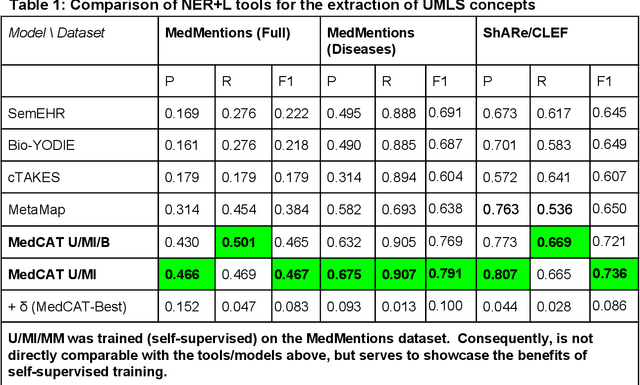
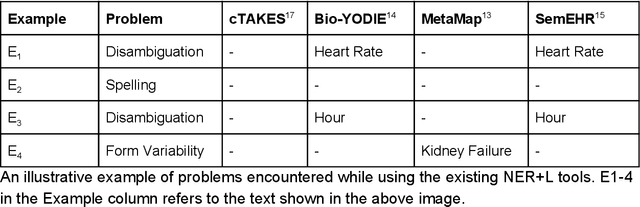
Electronic health records (EHR) contain large volumes of unstructured text, requiring the application of Information Extraction (IE) technologies to enable clinical analysis. We present the open source Medical Concept Annotation Toolkit (MedCAT) that provides: a) a novel self-supervised machine learning algorithm for extracting concepts using any concept vocabulary including UMLS/SNOMED-CT; b) a feature-rich annotation interface for customizing and training IE models; and c) integrations to the broader CogStack ecosystem for vendor-agnostic health system deployment. We show improved performance in extracting UMLS concepts from open datasets ( F1 0.467-0.791 vs 0.384-0.691). Further real-world validation demonstrates SNOMED-CT extraction at 3 large London hospitals with self-supervised training over ~8.8B words from ~17M clinical records and further fine-tuning with ~6K clinician annotated examples. We show strong transferability ( F1 >0.94) between hospitals, datasets and concept types indicating cross-domain EHR-agnostic utility for accelerated clinical and research use cases.
Comparative Analysis of Text Classification Approaches in Electronic Health Records
May 08, 2020
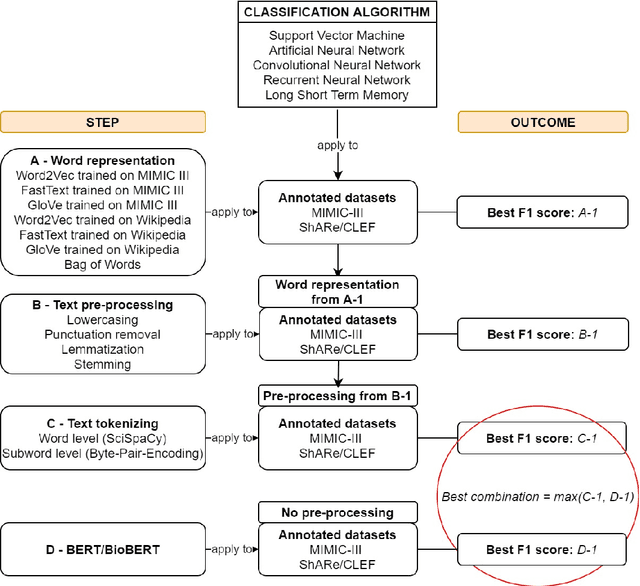

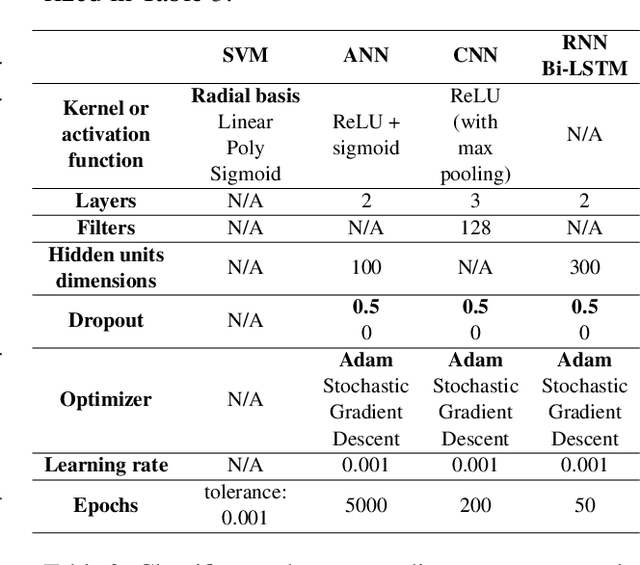
Text classification tasks which aim at harvesting and/or organizing information from electronic health records are pivotal to support clinical and translational research. However these present specific challenges compared to other classification tasks, notably due to the particular nature of the medical lexicon and language used in clinical records. Recent advances in embedding methods have shown promising results for several clinical tasks, yet there is no exhaustive comparison of such approaches with other commonly used word representations and classification models. In this work, we analyse the impact of various word representations, text pre-processing and classification algorithms on the performance of four different text classification tasks. The results show that traditional approaches, when tailored to the specific language and structure of the text inherent to the classification task, can achieve or exceed the performance of more recent ones based on contextual embeddings such as BERT.
Identifying physical health comorbidities in a cohort of individuals with severe mental illness: An application of SemEHR
Feb 07, 2020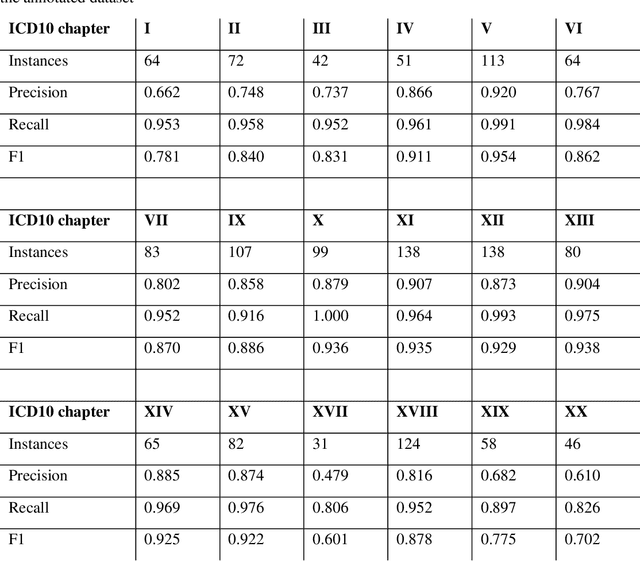
Multimorbidity research in mental health services requires data from physical health conditions which is traditionally limited in mental health care electronic health records. In this study, we aimed to extract data from physical health conditions from clinical notes using SemEHR. Data was extracted from Clinical Record Interactive Search (CRIS) system at South London and Maudsley Biomedical Research Centre (SLaM BRC) and the cohort consisted of all individuals who had received a primary or secondary diagnosis of severe mental illness between 2007 and 2018. Three pairs of annotators annotated 2403 documents with an average Cohen's Kappa of 0.757. Results show that the NLP performance varies across different diseases areas (F1 0.601 - 0.954) suggesting that the language patterns or terminologies of different condition groups entail different technical challenges to the same NLP task.
MedCAT -- Medical Concept Annotation Tool
Dec 18, 2019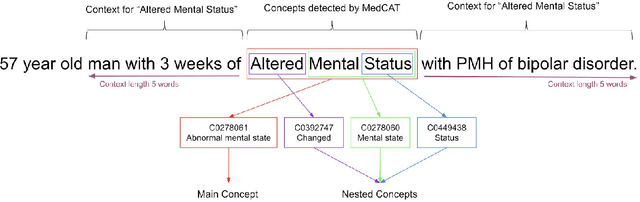
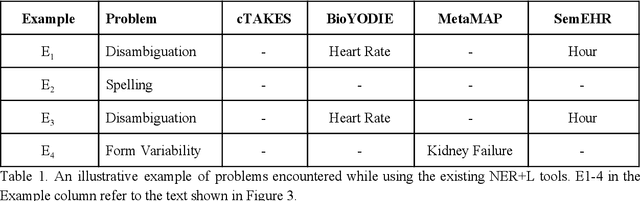
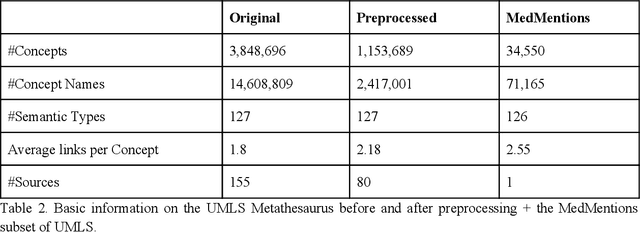
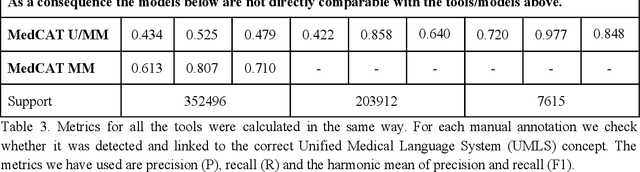
Biomedical documents such as Electronic Health Records (EHRs) contain a large amount of information in an unstructured format. The data in EHRs is a hugely valuable resource documenting clinical narratives and decisions, but whilst the text can be easily understood by human doctors it is challenging to use in research and clinical applications. To uncover the potential of biomedical documents we need to extract and structure the information they contain. The task at hand is Named Entity Recognition and Linking (NER+L). The number of entities, ambiguity of words, overlapping and nesting make the biomedical area significantly more difficult than many others. To overcome these difficulties, we have developed the Medical Concept Annotation Tool (MedCAT), an open-source unsupervised approach to NER+L. MedCAT uses unsupervised machine learning to disambiguate entities. It was validated on MIMIC-III (a freely accessible critical care database) and MedMentions (Biomedical papers annotated with mentions from the Unified Medical Language System). In case of NER+L, the comparison with existing tools shows that MedCAT improves the previous best with only unsupervised learning (F1=0.848 vs 0.691 for disease detection; F1=0.710 vs. 0.222 for general concept detection). A qualitative analysis of the vector embeddings learnt by MedCAT shows that it captures latent medical knowledge available in EHRs (MIMIC-III). Unsupervised learning can improve the performance of large scale entity extraction, but it has some limitations when working with only a couple of entities and a small dataset. In that case options are supervised learning or active learning, both of which are supported in MedCAT via the MedCATtrainer extension. Our approach can detect and link millions of different biomedical concepts with state-of-the-art performance, whilst being lightweight, fast and easy to use.
MedCATTrainer: A Biomedical Free Text Annotation Interface with Active Learning and Research Use Case Specific Customisation
Jul 16, 2019
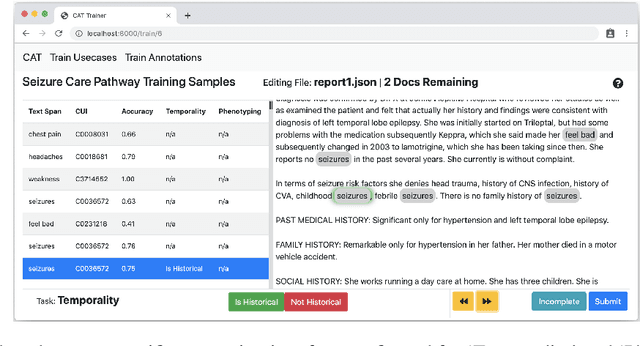
We present MedCATTrainer an interface for building, improving and customising a given Named Entity Recognition and Linking (NER+L) model for biomedical domain text. NER+L is often used as a first step in deriving value from clinical text. Collecting labelled data for training models is difficult due to the need for specialist domain knowledge. MedCATTrainer offers an interactive web-interface to inspect and improve recognised entities from an underlying NER+L model via active learning. Secondary use of data for clinical research often has task and context specific criteria. MedCATTrainer provides a further interface to define and collect supervised learning training data for researcher specific use cases. Initial results suggest our approach allows for efficient and accurate collection of research use case specific training data.