 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One-Size-Fits-All: Multi-Domain, Multi-Task Framework for Embedding Model Selection
Mar 30, 2024This position paper proposes a systematic approach towards developing a framework to help select the most effective embedding models for natural language processing (NLP) tasks, addressing the challenge posed by the proliferation of both proprietary and open-source encoder models.
DEFT: Data Efficient Fine-Tuning for Large Language Models via Unsupervised Core-Set Selection
Oct 26, 2023Recent advances have led to the availability of many pre-trained language models (PLMs); however, a question that remains is how much data is truly needed to fine-tune PLMs for downstream tasks? In this work, we introduce DEFT, a data-efficient fine-tuning framework that leverages unsupervised core-set selection to minimize the amount of data needed to fine-tune PLMs for downstream tasks. We demonstrate the efficacy of our DEFT framework in the context of text-editing LMs, and compare to the state-of-the art text-editing model, CoEDIT. Our quantitative and qualitative results demonstrate that DEFT models are just as accurate as CoEDIT while being finetuned on ~70% less data.
RedHOT: A Corpus of Annotated Medical Questions, Experiences, and Claims on Social Media
Oct 12, 2022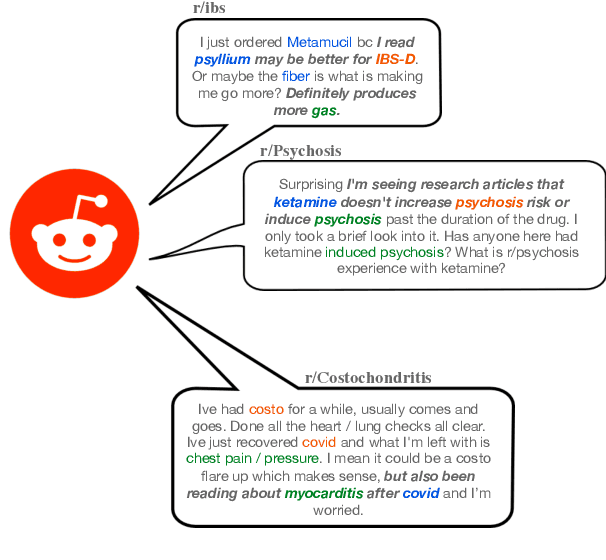
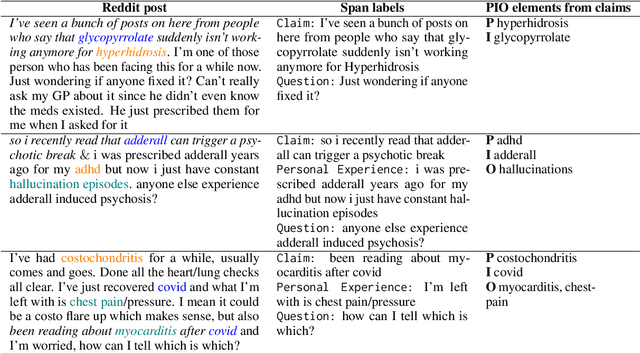
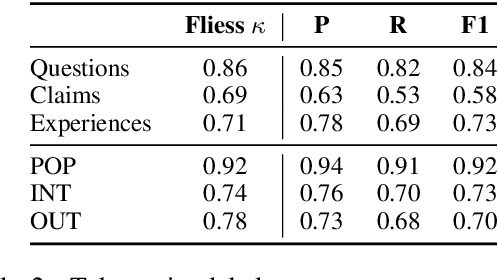
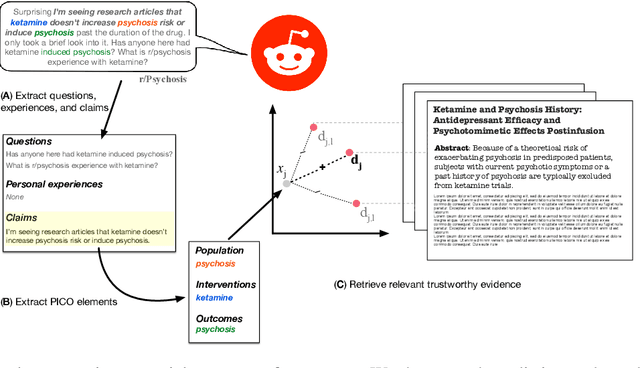
We present Reddit Health Online Talk (RedHOT), a corpus of 22,000 richly annotated social media posts from Reddit spanning 24 health conditions. Annotations include demarcations of spans corresponding to medical claims, personal experiences, and questions. We collect additional granular annotations on identified claims. Specifically, we mark snippets that describe patient Populations, Interventions, and Outcomes (PIO elements) within these. Using this corpus, we introduce the task of retrieving trustworthy evidence relevant to a given claim made on social media. We propose a new method to automatically derive (noisy) supervision for this task which we use to train a dense retrieval model; this outperforms baseline models. Manual evaluation of retrieval results performed by medical doctors indicate that while our system performance is promising, there is considerable room for improvement. Collected annotations (and scripts to assemble the dataset), are available at https://github.com/sominw/redhot.
CHARD: Clinical Health-Aware Reasoning Across Dimensions for Text Generation Models
Oct 09, 2022
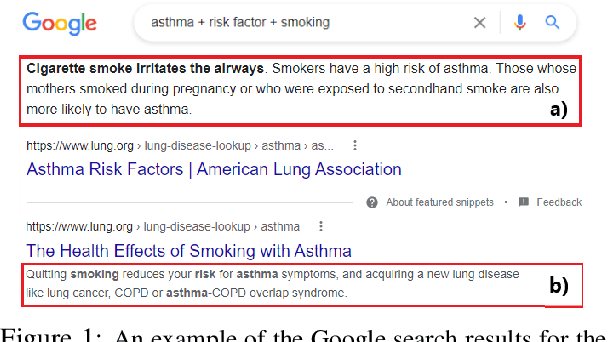
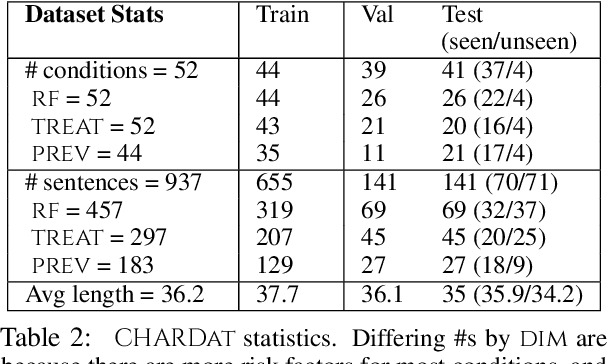
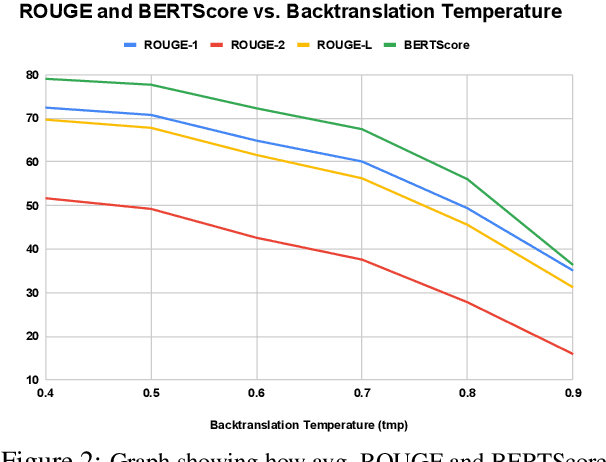
We motivate and introduce CHARD: Clinical Health-Aware Reasoning across Dimensions, to investigate the capability of text generation models to act as implicit clinical knowledge bases and generate free-flow textual explanations about various health-related conditions across several dimensions. We collect and present an associated dataset, CHARDat, consisting of explanations about 52 health conditions across three clinical dimensions. We conduct extensive experiments using BART and T5 along with data augmentation, and perform automatic, human, and qualitative analyses. We show that while our models can perform decently, CHARD is very challenging with strong potential for further exploration.
Identifying causal associations in tweets using deep learning: Use case on diabetes-related tweets from 2017-2021
Nov 04, 2021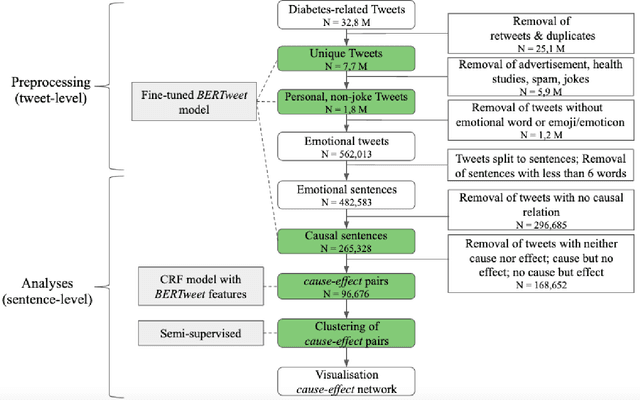
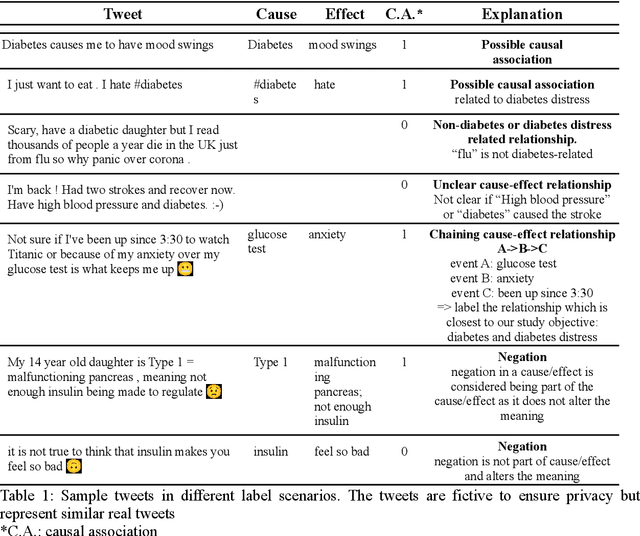
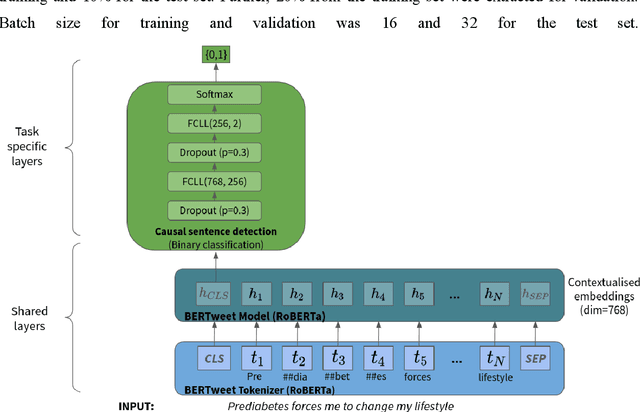
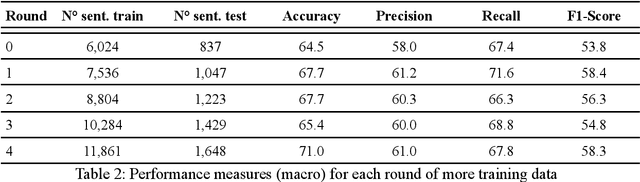
Objective: Leveraging machine learning methods, we aim to extract both explicit and implicit cause-effect associations in patient-reported, diabetes-related tweets and provide a tool to better understand opinion, feelings and observations shared within the diabetes online community from a causality perspective. Materials and Methods: More than 30 million diabetes-related tweets in English were collected between April 2017 and January 2021. Deep learning and natural language processing methods were applied to focus on tweets with personal and emotional content. A cause-effect-tweet dataset was manually labeled and used to train 1) a fine-tuned Bertweet model to detect causal sentences containing a causal association 2) a CRF model with BERT based features to extract possible cause-effect associations. Causes and effects were clustered in a semi-supervised approach and visualised in an interactive cause-effect-network. Results: Causal sentences were detected with a recall of 68% in an imbalanced dataset. A CRF model with BERT based features outperformed a fine-tuned BERT model for cause-effect detection with a macro recall of 68%. This led to 96,676 sentences with cause-effect associations. "Diabetes" was identified as the central cluster followed by "Death" and "Insulin". Insulin pricing related causes were frequently associated with "Death". Conclusions: A novel methodology was developed to detect causal sentences and identify both explicit and implicit, single and multi-word cause and corresponding effect as expressed in diabetes-related tweets leveraging BERT-based architectures and visualised as cause-effect-network. Extracting causal associations on real-life, patient reported outcomes in social media data provides a useful complementary source of information in diabetes research.
Cross-Domain Reasoning via Template Filling
Oct 31, 2021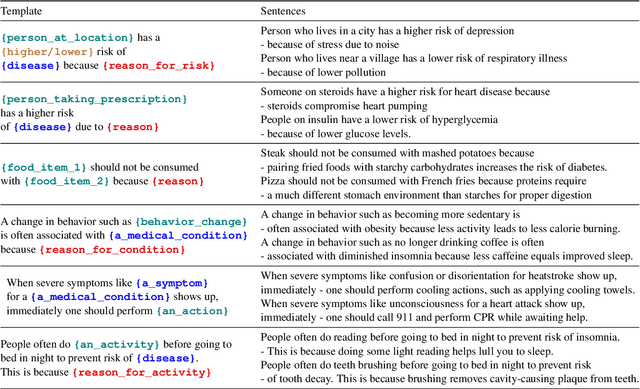
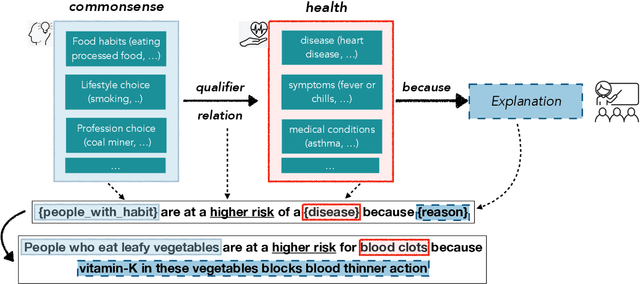
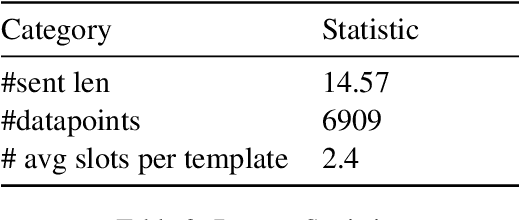

In this paper, we explore the ability of sequence to sequence models to perform cross-domain reasoning. Towards this, we present a prompt-template-filling approach to enable sequence to sequence models to perform cross-domain reasoning. We also present a case-study with commonsense and health and well-being domains, where we study how prompt-template-filling enables pretrained sequence to sequence models across domains. Our experiments across several pretrained encoder-decoder models show that cross-domain reasoning is challenging for current models. We also show an in-depth error analysis and avenues for future research for reasoning across domains
MIMICause : Defining, identifying and predicting types of causal relationships between biomedical concepts from clinical notes
Oct 14, 2021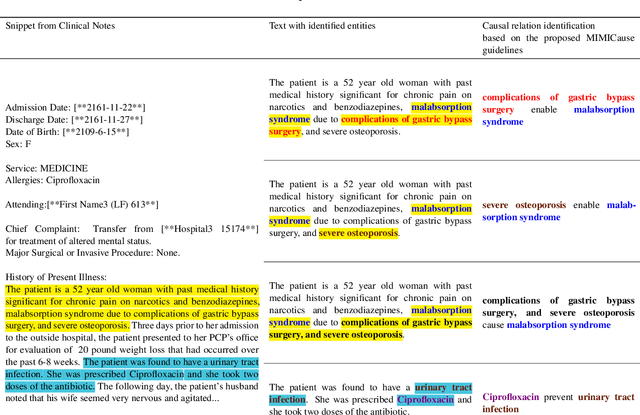
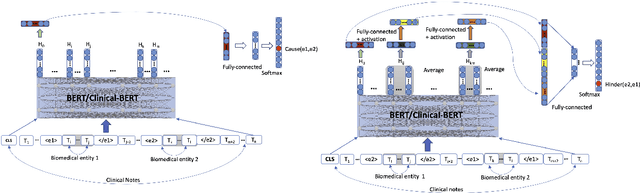
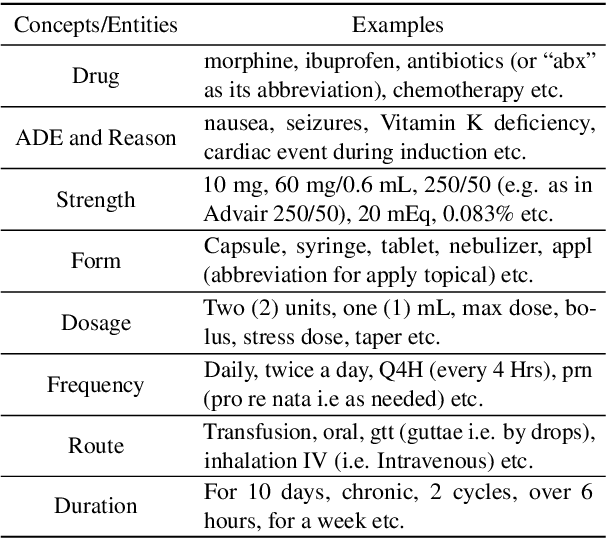
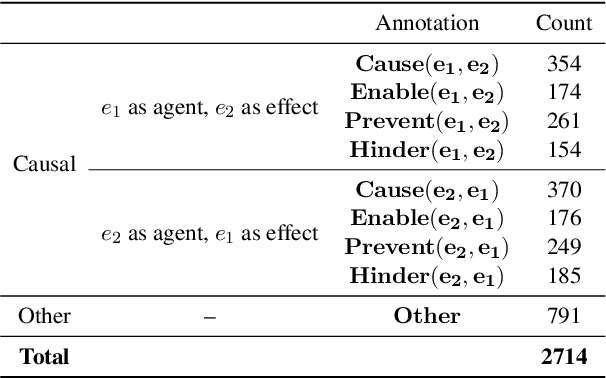
Understanding of causal narratives communicated in clinical notes can help make strides towards personalized healthcare. In this work, MIMICause, we propose annotation guidelines, develop an annotated corpus and provide baseline scores to identify types and direction of causal relations between a pair of biomedical concepts in clinical notes; communicated implicitly or explicitly, identified either in a single sentence or across multiple sentences. We annotate a total of 2714 de-identified examples sampled from the 2018 n2c2 shared task dataset and train four different language model based architectures. Annotation based on our guidelines achieved a high inter-annotator agreement i.e. Fleiss' kappa score of 0.72 and our model for identification of causal relation achieved a macro F1 score of 0.56 on test data. The high inter-annotator agreement for clinical text shows the quality of our annotation guidelines while the provided baseline F1 score sets the direction for future research towards understanding narratives in clinical texts.
Knowledge Graph Anchored Information-Extraction for Domain-Specific Insights
Apr 20, 2021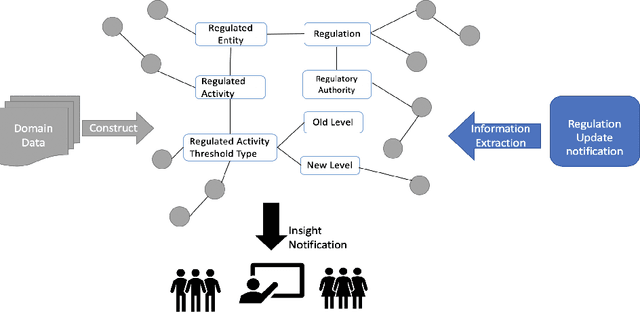
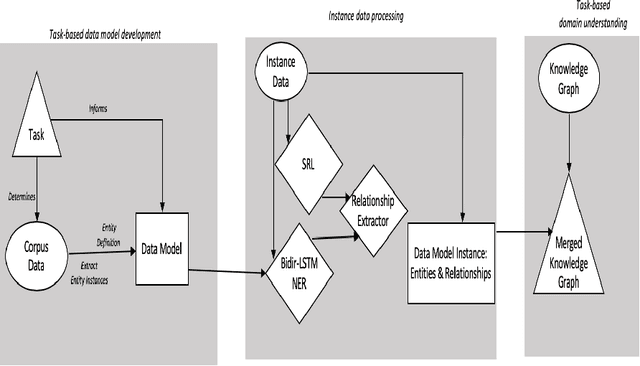
The growing quantity and complexity of data pose challenges for humans to consume information and respond in a timely manner. For businesses in domains with rapidly changing rules and regulations, failure to identify changes can be costly. In contrast to expert analysis or the development of domain-specific ontology and taxonomies, we use a task-based approach for fulfilling specific information needs within a new domain. Specifically, we propose to extract task-based information from incoming instance data. A pipeline constructed of state of the art NLP technologies, including a bi-LSTM-CRF model for entity extraction, attention-based deep Semantic Role Labeling, and an automated verb-based relationship extractor, is used to automatically extract an instance level semantic structure. Each instance is then combined with a larger, domain-specific knowledge graph to produce new and timely insights. Preliminary results, validated manually, show the methodology to be effective for extracting specific information to complete end use-cases.
Causal-BERT : Language models for causality detection between events expressed in text
Dec 10, 2020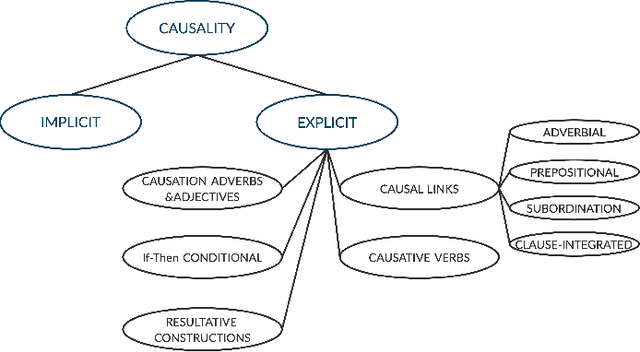



Causality understanding between events is a critical natural language processing task that is helpful in many areas, including health care, business risk management and finance. On close examination, one can find a huge amount of textual content both in the form of formal documents or in content arising from social media like Twitter, dedicated to communicating and exploring various types of causality in the real world. Recognizing these "Cause-Effect" relationships between natural language events continues to remain a challenge simply because it is often expressed implicitly. Implicit causality is hard to detect through most of the techniques employed in literature and can also, at times be perceived as ambiguous or vague. Also, although well-known datasets do exist for this problem, the examples in them are limited in the range and complexity of the causal relationships they depict especially when related to implicit relationships. Most of the contemporary methods are either based on lexico-semantic pattern matching or are feature-driven supervised methods. Therefore, as expected these methods are more geared towards handling explicit causal relationships leading to limited coverage for implicit relationships and are hard to generalize. In this paper, we investigate the language model's capabilities for causal association among events expressed in natural language text using sentence context combined with event information, and by leveraging masked event context with in-domain and out-of-domain data distribution. Our proposed methods achieve the state-of-art performance in three different data distributions and can be leveraged for extraction of a causal diagram and/or building a chain of events from unstructured text.