 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying causal associations in tweets using deep learning: Use case on diabetes-related tweets from 2017-2021
Nov 04, 2021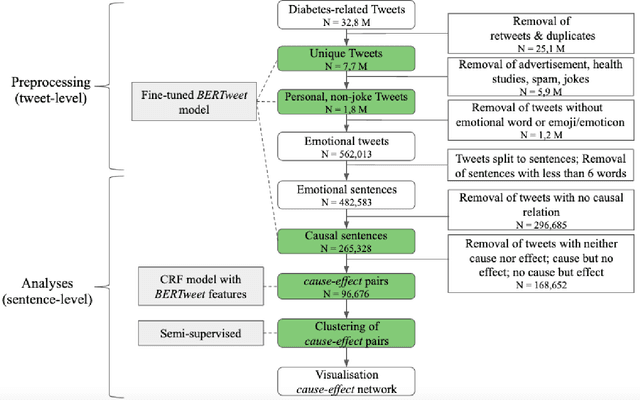
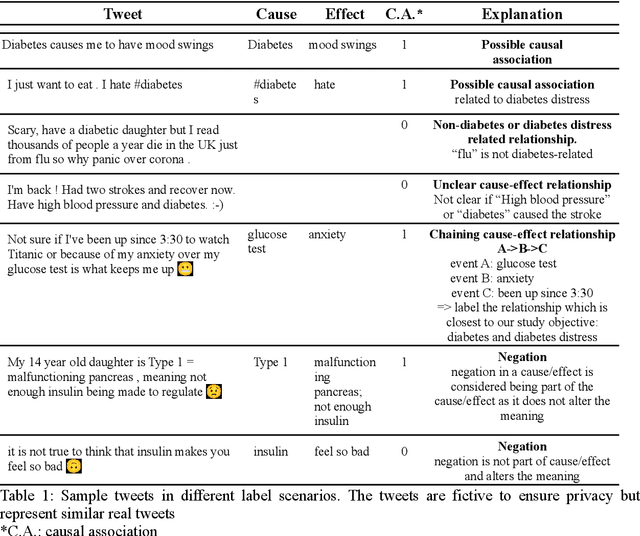
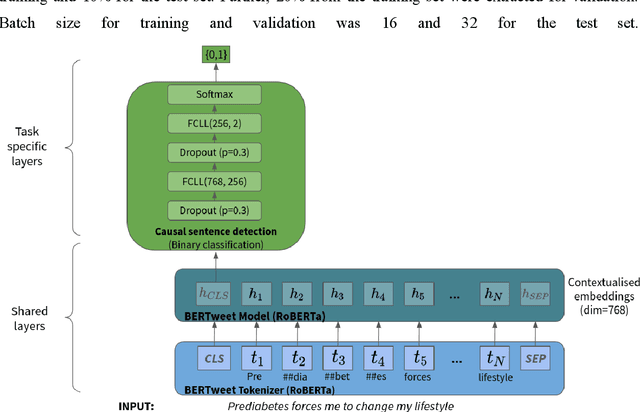
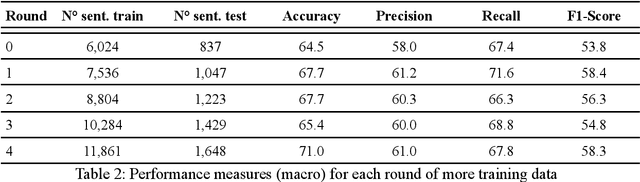
Objective: Leveraging machine learning methods, we aim to extract both explicit and implicit cause-effect associations in patient-reported, diabetes-related tweets and provide a tool to better understand opinion, feelings and observations shared within the diabetes online community from a causality perspective. Materials and Methods: More than 30 million diabetes-related tweets in English were collected between April 2017 and January 2021. Deep learning and natural language processing methods were applied to focus on tweets with personal and emotional content. A cause-effect-tweet dataset was manually labeled and used to train 1) a fine-tuned Bertweet model to detect causal sentences containing a causal association 2) a CRF model with BERT based features to extract possible cause-effect associations. Causes and effects were clustered in a semi-supervised approach and visualised in an interactive cause-effect-network. Results: Causal sentences were detected with a recall of 68% in an imbalanced dataset. A CRF model with BERT based features outperformed a fine-tuned BERT model for cause-effect detection with a macro recall of 68%. This led to 96,676 sentences with cause-effect associations. "Diabetes" was identified as the central cluster followed by "Death" and "Insulin". Insulin pricing related causes were frequently associated with "Death". Conclusions: A novel methodology was developed to detect causal sentences and identify both explicit and implicit, single and multi-word cause and corresponding effect as expressed in diabetes-related tweets leveraging BERT-based architectures and visualised as cause-effect-network. Extracting causal associations on real-life, patient reported outcomes in social media data provides a useful complementary source of information in diabetes research.
Cross-Domain Reasoning via Template Filling
Oct 31, 2021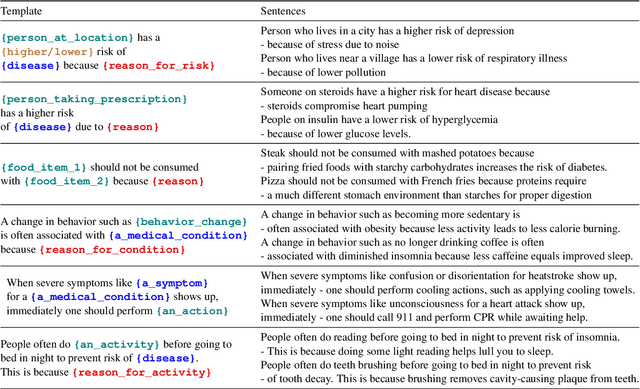
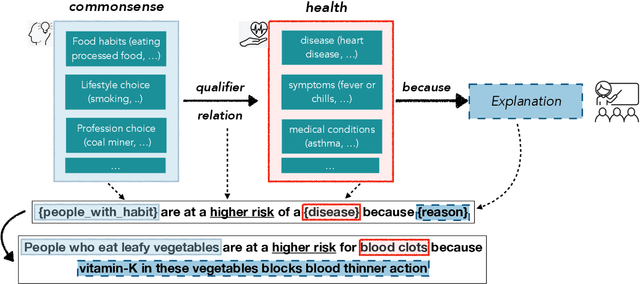

In this paper, we explore the ability of sequence to sequence models to perform cross-domain reasoning. Towards this, we present a prompt-template-filling approach to enable sequence to sequence models to perform cross-domain reasoning. We also present a case-study with commonsense and health and well-being domains, where we study how prompt-template-filling enables pretrained sequence to sequence models across domains. Our experiments across several pretrained encoder-decoder models show that cross-domain reasoning is challenging for current models. We also show an in-depth error analysis and avenues for future research for reasoning across domains
MIMICause : Defining, identifying and predicting types of causal relationships between biomedical concepts from clinical notes
Oct 14, 2021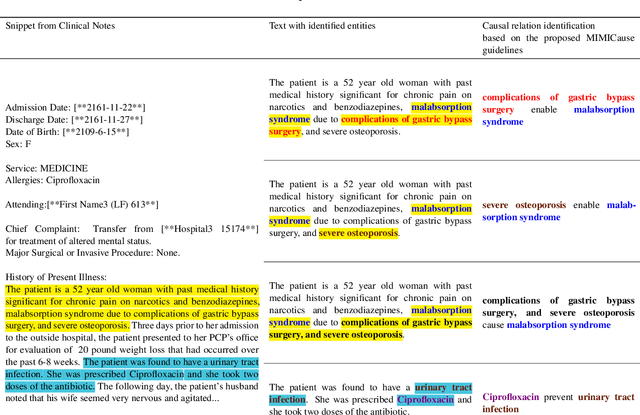
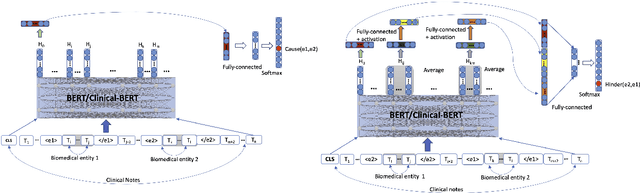
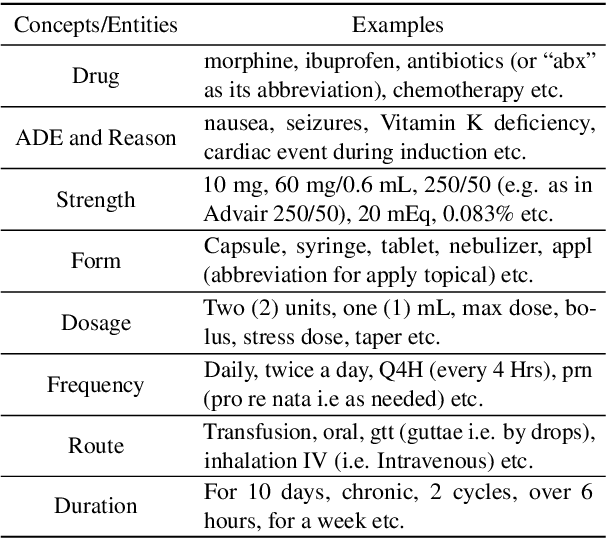
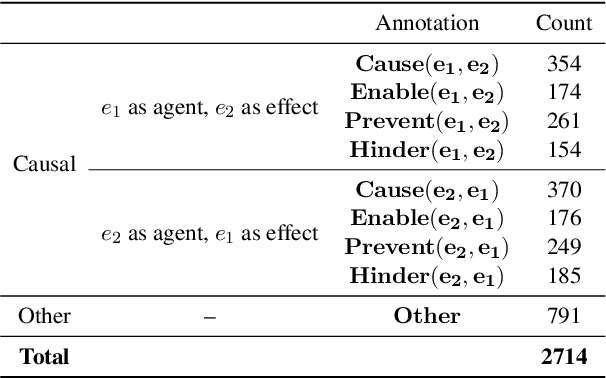
Understanding of causal narratives communicated in clinical notes can help make strides towards personalized healthcare. In this work, MIMICause, we propose annotation guidelines, develop an annotated corpus and provide baseline scores to identify types and direction of causal relations between a pair of biomedical concepts in clinical notes; communicated implicitly or explicitly, identified either in a single sentence or across multiple sentences. We annotate a total of 2714 de-identified examples sampled from the 2018 n2c2 shared task dataset and train four different language model based architectures. Annotation based on our guidelines achieved a high inter-annotator agreement i.e. Fleiss' kappa score of 0.72 and our model for identification of causal relation achieved a macro F1 score of 0.56 on test data. The high inter-annotator agreement for clinical text shows the quality of our annotation guidelines while the provided baseline F1 score sets the direction for future research towards understanding narratives in clinical texts.