 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Jun 14, 2024


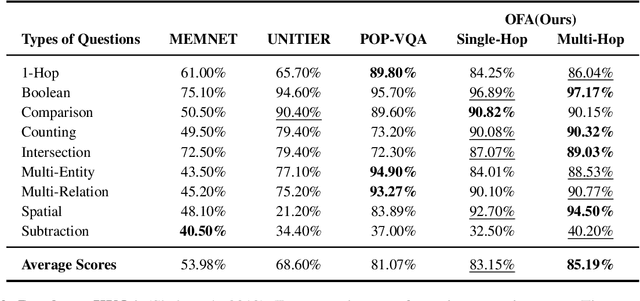
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75\% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Knowledge Graph Anchored Information-Extraction for Domain-Specific Insights
Apr 20, 2021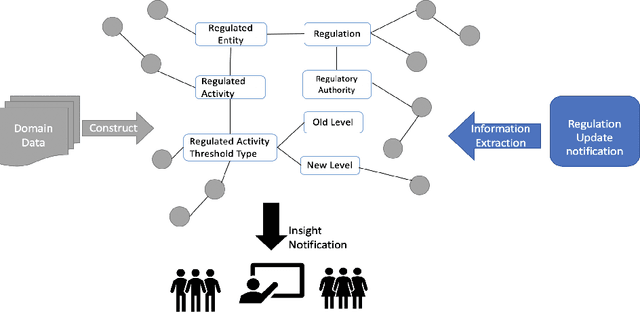
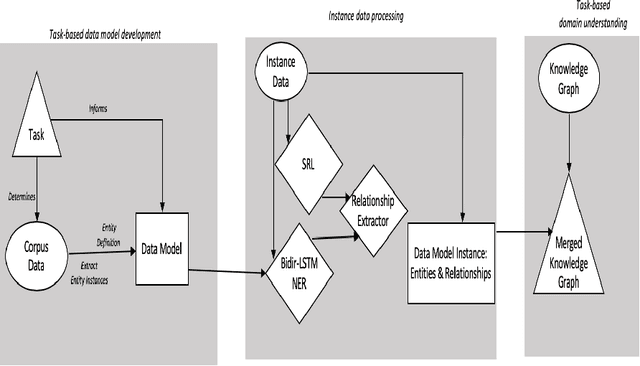
The growing quantity and complexity of data pose challenges for humans to consume information and respond in a timely manner. For businesses in domains with rapidly changing rules and regulations, failure to identify changes can be costly. In contrast to expert analysis or the development of domain-specific ontology and taxonomies, we use a task-based approach for fulfilling specific information needs within a new domain. Specifically, we propose to extract task-based information from incoming instance data. A pipeline constructed of state of the art NLP technologies, including a bi-LSTM-CRF model for entity extraction, attention-based deep Semantic Role Labeling, and an automated verb-based relationship extractor, is used to automatically extract an instance level semantic structure. Each instance is then combined with a larger, domain-specific knowledge graph to produce new and timely insights. Preliminary results, validated manually, show the methodology to be effective for extracting specific information to complete end use-cases.