 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSI-Bench: Benchmarking Time Series Imputation
Jun 18, 2024Effective imputation is a crucial preprocessing step for time series analysis. Despite the development of numerous deep learning algorithms for time series imputation, the community lacks standardized and comprehensive benchmark platforms to effectively evaluate imputation performance across different settings. Moreover, although many deep learning forecasting algorithms have demonstrated excellent performance, whether their modeling achievements can be transferred to time series imputation tasks remains unexplored. To bridge these gaps, we develop TSI-Bench, the first (to our knowledge) comprehensive benchmark suite for time series imputation utilizing deep learning techniques. The TSI-Bench pipeline standardizes experimental settings to enable fair evaluation of imputation algorithms and identification of meaningful insights into the influence of domain-appropriate missingness ratios and patterns on model performance. Furthermore, TSI-Bench innovatively provides a systematic paradigm to tailor time series forecasting algorithms for imputation purposes. Our extensive study across 34,804 experiments, 28 algorithms, and 8 datasets with diverse missingness scenarios demonstrates TSI-Bench's effectiveness in diverse downstream tasks and potential to unlock future directions in time series imputation research and analysis. The source code and experiment logs are available at https://github.com/WenjieDu/AwesomeImputation.
FedTADBench: Federated Time-Series Anomaly Detection Benchmark
Dec 19, 2022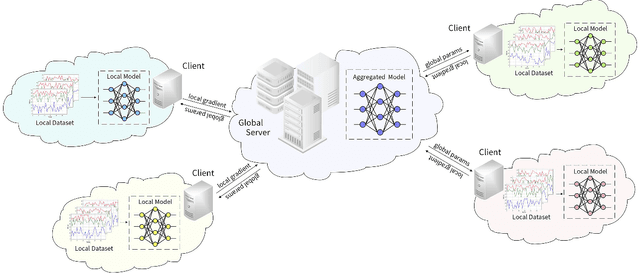
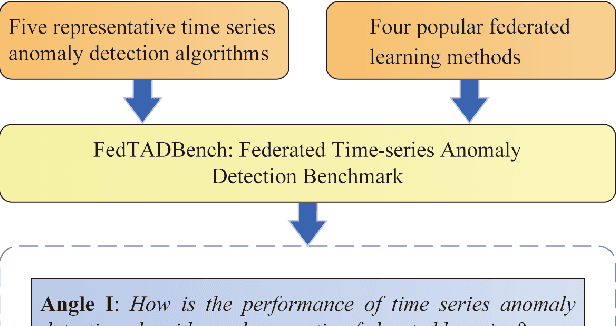
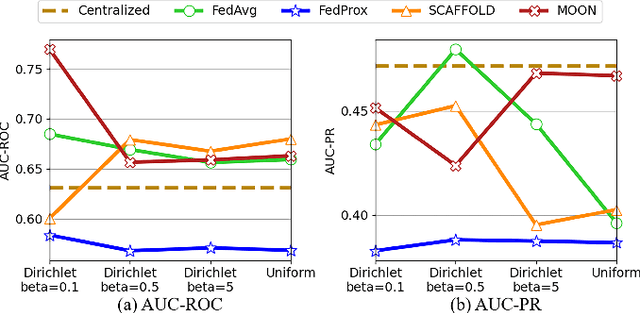
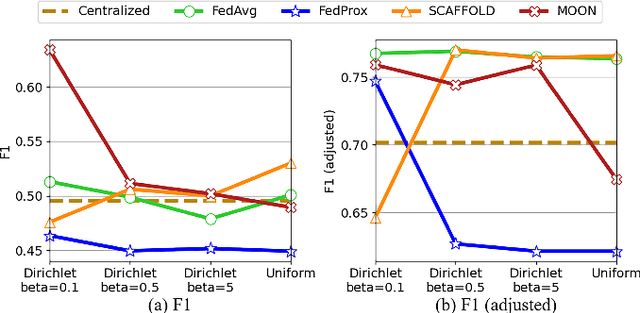
Time series anomaly detection strives to uncover potential abnormal behaviors and patterns from temporal data, and has fundamental significance in diverse application scenarios. Constructing an effective detection model usually requires adequate training data stored in a centralized manner, however, this requirement sometimes could not be satisfied in realistic scenarios. As a prevailing approach to address the above problem, federated learning has demonstrated its power to cooperate with the distributed data available while protecting the privacy of data providers. However, it is still unclear that how existing time series anomaly detection algorithms perform with decentralized data storage and privacy protection through federated learning. To study this, we conduct a federated time series anomaly detection benchmark, named FedTADBench, which involves five representative time series anomaly detection algorithms and four popular federated learning methods. We would like to answer the following questions: (1)How is the performance of time series anomaly detection algorithms when meeting federated learning? (2) Which federated learning method is the most appropriate one for time series anomaly detection? (3) How do federated time series anomaly detection approaches perform on different partitions of data in clients? Numbers of results as well as corresponding analysis are provided from extensive experiments with various settings. The source code of our benchmark is publicly available at https://github.com/fanxingliu2020/FedTADBench.
Feature Encoding with AutoEncoders for Weakly-supervised Anomaly Detection
Jun 03, 2021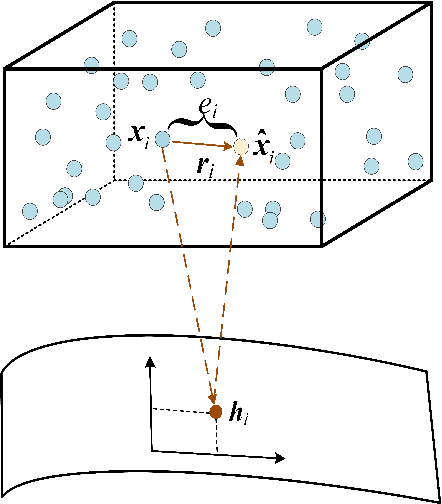
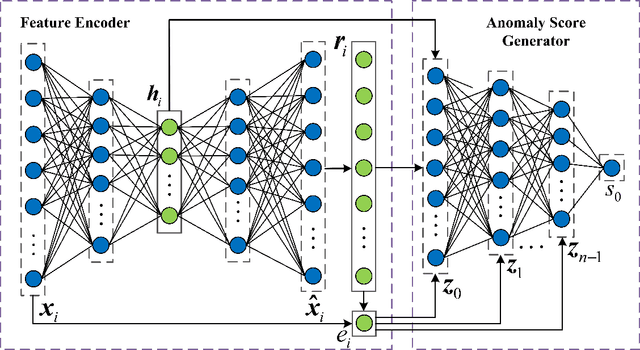
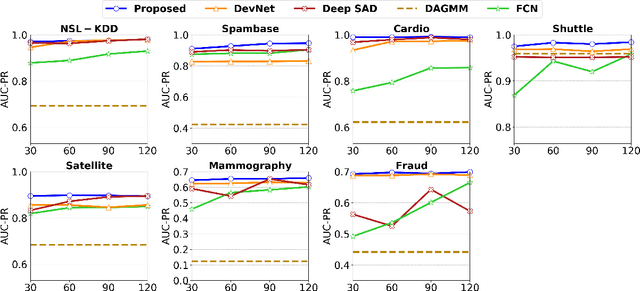
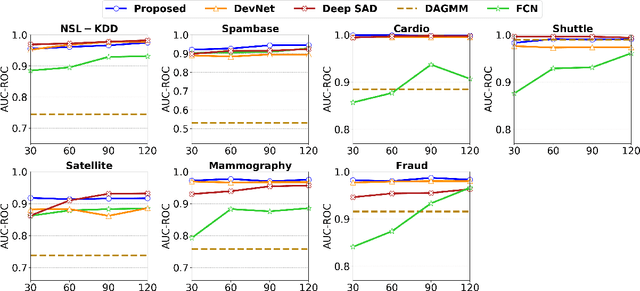
Weakly-supervised anomaly detection aims at learning an anomaly detector from a limited amount of labeled data and abundant unlabeled data. Recent works build deep neural networks for anomaly detection by discriminatively mapping the normal samples and abnormal samples to different regions in the feature space or fitting different distributions. However, due to the limited number of annotated anomaly samples, directly training networks with the discriminative loss may not be sufficient. To overcome this issue, this paper proposes a novel strategy to transform the input data into a more meaningful representation that could be used for anomaly detection. Specifically, we leverage an autoencoder to encode the input data and utilize three factors, hidden representation, reconstruction residual vector, and reconstruction error, as the new representation for the input data. This representation amounts to encode a test sample with its projection on the training data manifold, its direction to its projection and its distance to its projection. In addition to this encoding, we also propose a novel network architecture to seamlessly incorporate those three factors. From our extensive experiments, the benefits of the proposed strategy are clearly demonstrated by its superior performance over the competitive methods.