 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFORGE: Multi-modal Attacks Reveal Vulnerable Concept Unlearning in Image Generation Models
Mar 17, 2026Recent progress in image generation models (IGMs) enables high-fidelity content creation but also amplifies risks, including the reproduction of copyrighted content and the generation of offensive content. Image Generation Model Unlearning (IGMU) mitigates these risks by removing harmful concepts without full retraining. Despite growing attention, the robustness under adversarial inputs, particularly image-side threats in black-box settings, remains underexplored. To bridge this gap, we present REFORGE, a black-box red-teaming framework that evaluates IGMU robustness via adversarial image prompts. REFORGE initializes stroke-based images and optimizes perturbations with a cross-attention-guided masking strategy that allocates noise to concept-relevant regions, balancing attack efficacy and visual fidelity. Extensive experiments across representative unlearning tasks and defenses demonstrate that REFORGE significantly improves attack success rate while achieving stronger semantic alignment and higher efficiency than involved baselines. These results expose persistent vulnerabilities in current IGMU methods and highlight the need for robustness-aware unlearning against multi-modal adversarial attacks. Our code is at: https://github.com/Imfatnoily/REFORGE.
U2-KWS: Unified Two-pass Open-vocabulary Keyword Spotting with Keyword Bias
Dec 15, 2023Open-vocabulary keyword spotting (KWS), which allows users to customize keywords, has attracted increasingly more interest. However, existing methods based on acoustic models and post-processing train the acoustic model with ASR training criteria to model all phonemes, making the acoustic model under-optimized for the KWS task. To solve this problem, we propose a novel unified two-pass open-vocabulary KWS (U2-KWS) framework inspired by the two-pass ASR model U2. Specifically, we employ the CTC branch as the first stage model to detect potential keyword candidates and the decoder branch as the second stage model to validate candidates. In order to enhance any customized keywords, we redesign the U2 training procedure for U2-KWS and add keyword information by audio and text cross-attention into both branches. We perform experiments on our internal dataset and Aishell-1. The results show that U2-KWS can achieve a significant relative wake-up rate improvement of 41% compared to the traditional customized KWS systems when the false alarm rate is fixed to 0.5 times per hour.
SpikeSEE: An Energy-Efficient Dynamic Scenes Processing Framework for Retinal Prostheses
Sep 16, 2022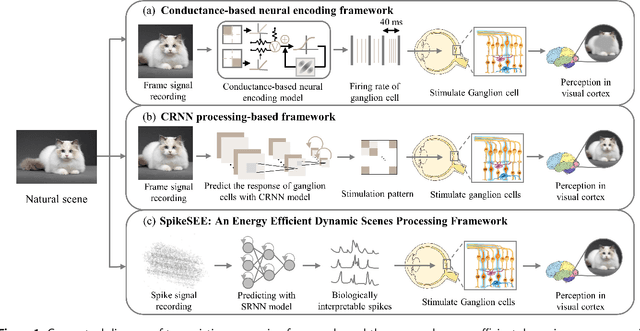
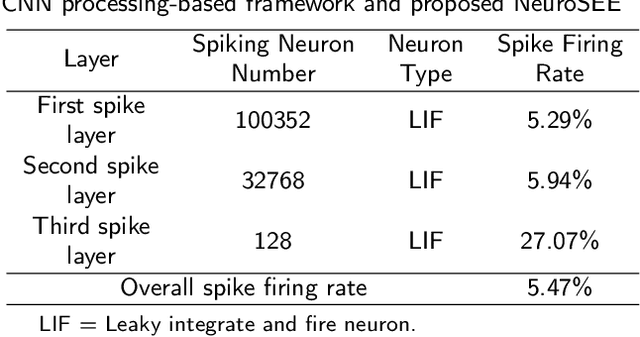
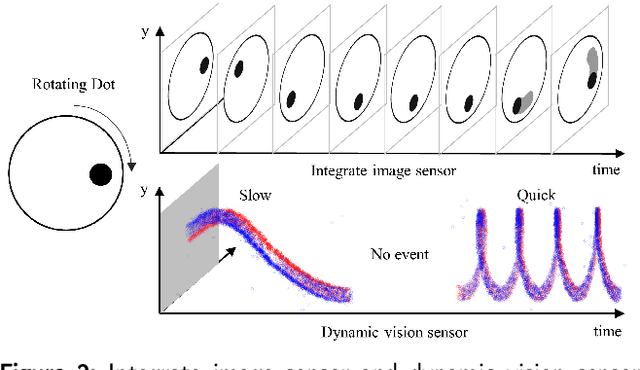
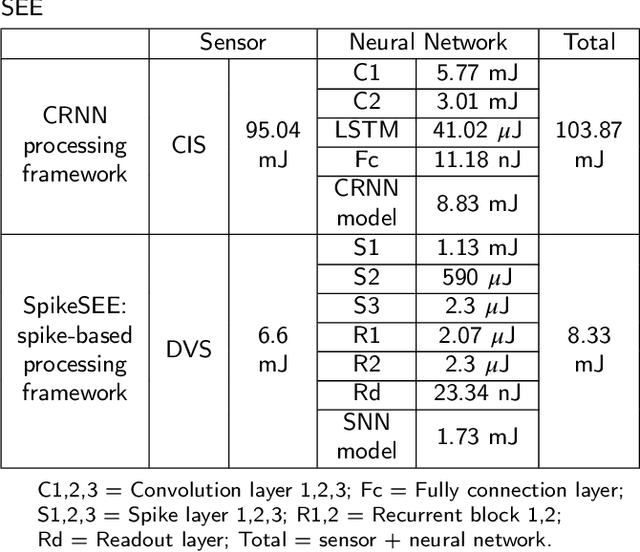
Intelligent and low-power retinal prostheses are highly demanded in this era, where wearable and implantable devices are used for numerous healthcare applications. In this paper, we propose an energy-efficient dynamic scenes processing framework (SpikeSEE) that combines a spike representation encoding technique and a bio-inspired spiking recurrent neural network (SRNN) model to achieve intelligent processing and extreme low-power computation for retinal prostheses. The spike representation encoding technique could interpret dynamic scenes with sparse spike trains, decreasing the data volume. The SRNN model, inspired by the human retina special structure and spike processing method, is adopted to predict the response of ganglion cells to dynamic scenes. Experimental results show that the Pearson correlation coefficient of the proposed SRNN model achieves 0.93, which outperforms the state of the art processing framework for retinal prostheses. Thanks to the spike representation and SRNN processing, the model can extract visual features in a multiplication-free fashion. The framework achieves 12 times power reduction compared with the convolutional recurrent neural network (CRNN) processing-based framework. Our proposed SpikeSEE predicts the response of ganglion cells more accurately with lower energy consumption, which alleviates the precision and power issues of retinal prostheses and provides a potential solution for wearable or implantable prostheses.