 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025
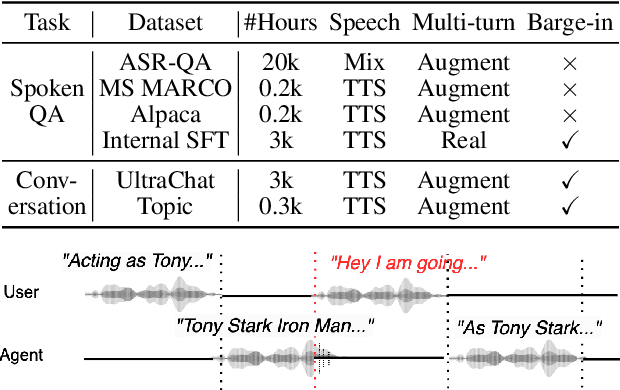
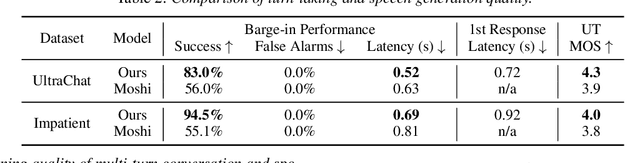

Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis
Apr 11, 2022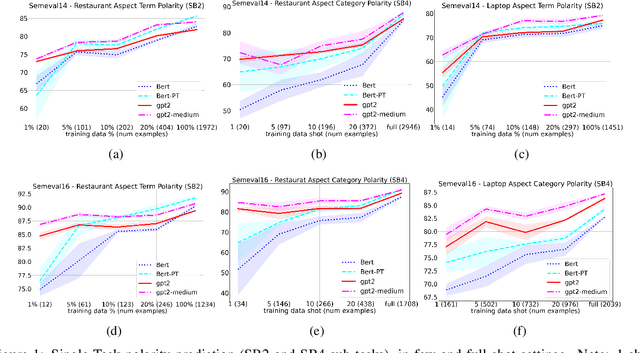
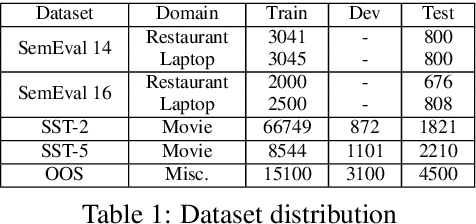
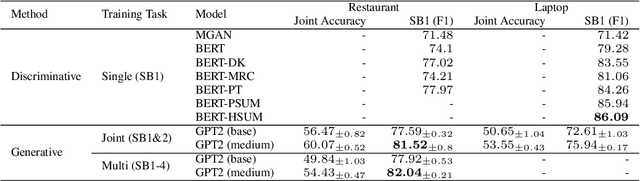
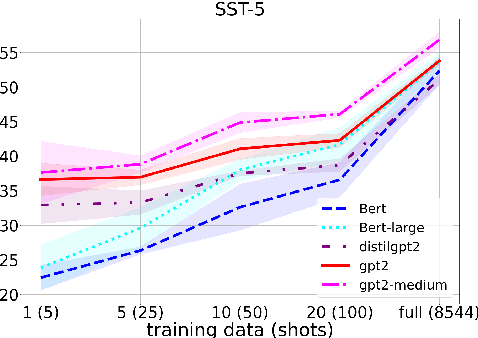
Sentiment analysis is an important task in natural language processing. In recent works, pre-trained language models are often used to achieve state-of-the-art results, especially when training data is scarce. It is common to fine-tune on the downstream task, usually by adding task-specific layers on top of the model. In this paper, we focus on aspect-based sentiment analysis, which involves extracting aspect term, category, and predicting their corresponding polarities. In particular, we are interested in few-shot settings. We propose to reformulate the extraction and prediction tasks into the sequence generation task, using a generative language model with unidirectional attention (GPT2 is used unless stated otherwise). This way, the model learns to accomplish the tasks via language generation without the need of training task-specific layers. Our evaluation results on the single-task polarity prediction show that our approach outperforms the previous state-of-the-art (based on BERT) on average performance by a large margins in few-shot and full-shot settings. More importantly, our generative approach significantly reduces the model variance caused by low-resource data. We further demonstrate that the proposed generative language model can handle joint and multi-task settings, unlike previous work. We observe that the proposed sequence generation method achieves further improved performances on polarity prediction when the model is trained via joint and multi-task settings. Further evaluation on similar sentiment analysis datasets, SST-2, SST- and OOS intent detection validates the superiority and noise robustness of generative language model in few-shot settings.
Joint Energy-based Model Training for Better Calibrated Natural Language Understanding Models
Jan 18, 2021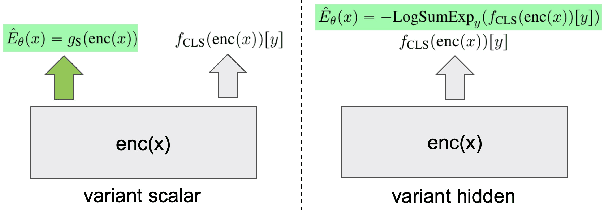
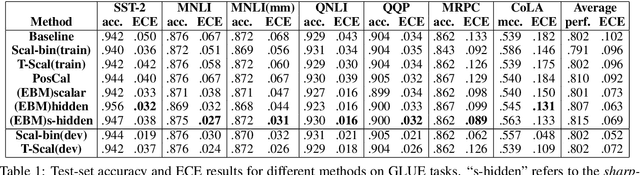
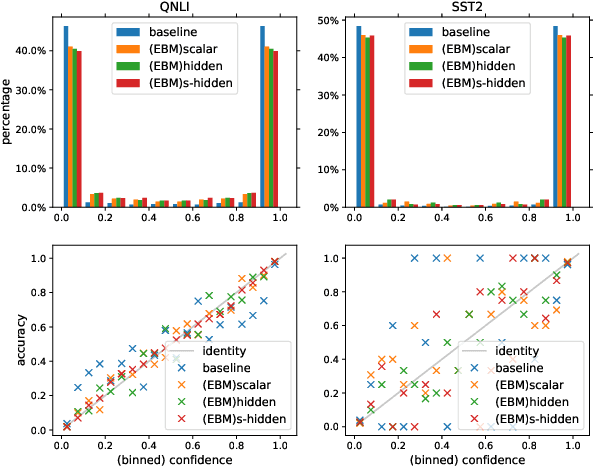
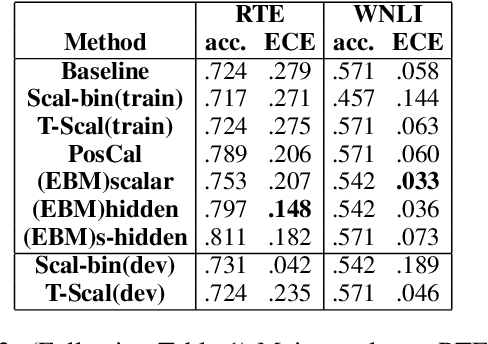
In this work, we explore joint energy-based model (EBM) training during the finetuning of pretrained text encoders (e.g., Roberta) for natural language understanding (NLU) tasks. Our experiments show that EBM training can help the model reach a better calibration that is competitive to strong baselines, with little or no loss in accuracy. We discuss three variants of energy functions (namely scalar, hidden, and sharp-hidden) that can be defined on top of a text encoder, and compare them in experiments. Due to the discreteness of text data, we adopt noise contrastive estimation (NCE) to train the energy-based model. To make NCE training more effective, we train an auto-regressive noise model with the masked language model (MLM) objective.
A Simple Language Model for Task-Oriented Dialogue
May 25, 2020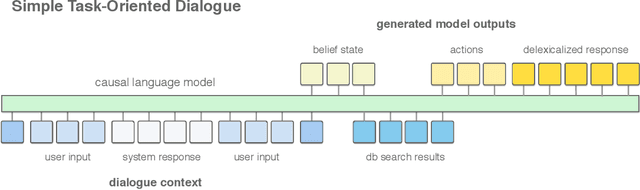


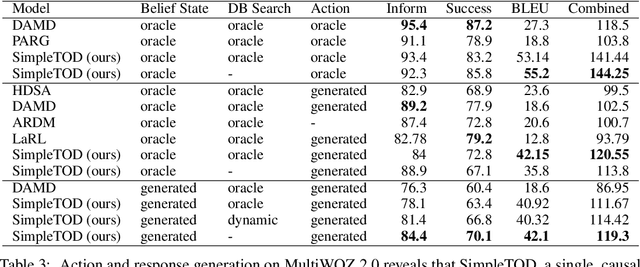
Task-oriented dialogue is often decomposed into three tasks: understanding user input, deciding actions, and generating a response. While such decomposition might suggest a dedicated model for each sub-task, we find a simple, unified approach leads to state-of-the-art performance on the MultiWOZ dataset. SimpleTOD is a simple approach to task-oriented dialogue that uses a single causal language model trained on all sub-tasks recast as a single sequence prediction problem. This allows SimpleTOD to fully leverage transfer learning from pre-trained, open domain, causal language models such as GPT-2. SimpleTOD improves over the prior state-of-the-art by 0.49 points in joint goal accuracy for dialogue state tracking. More impressively, SimpleTOD also improves the main metrics used to evaluate action decisions and response generation in an end-to-end setting for task-oriented dialog systems: inform rate by 8.1 points, success rate by 9.7 points, and combined score by 7.2 points.
Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
May 26, 2019
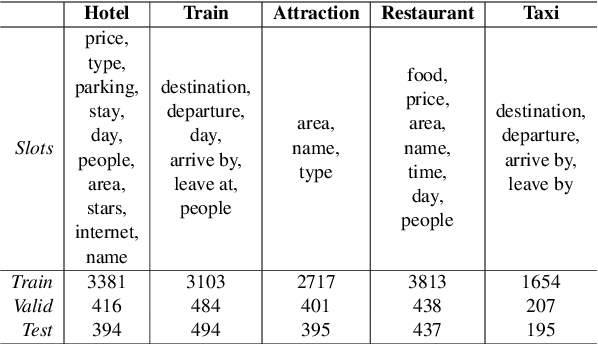
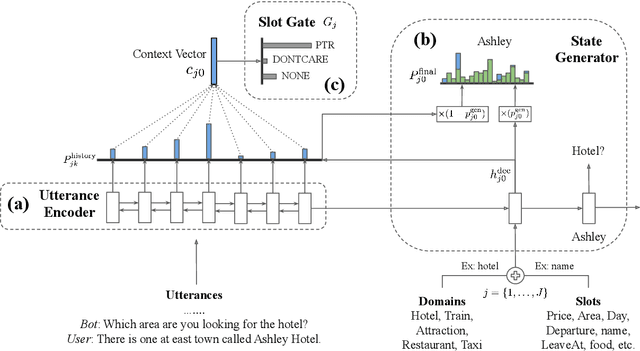
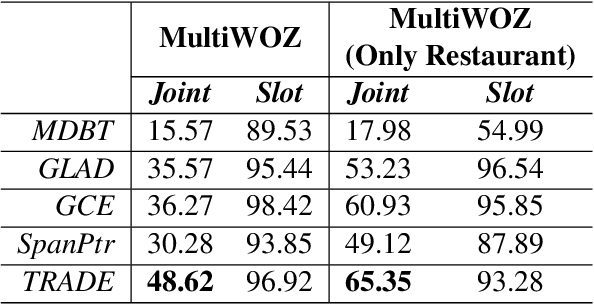
Over-dependence on domain ontology and lack of knowledge sharing across domains are two practical and yet less studied problems of dialogue state tracking. Existing approaches generally fall short in tracking unknown slot values during inference and often have difficulties in adapting to new domains. In this paper, we propose a Transferable Dialogue State Generator (TRADE) that generates dialogue states from utterances using a copy mechanism, facilitating knowledge transfer when predicting (domain, slot, value) triplets not encountered during training. Our model is composed of an utterance encoder, a slot gate, and a state generator, which are shared across domains. Empirical results demonstrate that TRADE achieves state-of-the-art joint goal accuracy of 48.62% for the five domains of MultiWOZ, a human-human dialogue dataset. In addition, we show its transferring ability by simulating zero-shot and few-shot dialogue state tracking for unseen domains. TRADE achieves 60.58% joint goal accuracy in one of the zero-shot domains, and is able to adapt to few-shot cases without forgetting already trained domains.
Toward Scalable Neural Dialogue State Tracking Model
Dec 03, 2018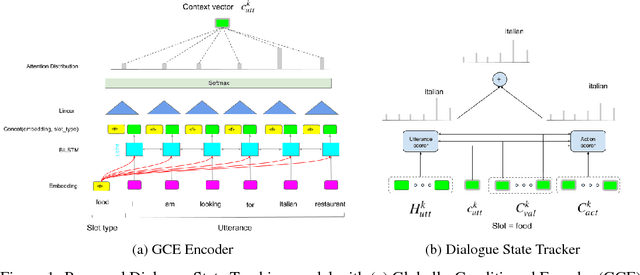



The latency in the current neural based dialogue state tracking models prohibits them from being used efficiently for deployment in production systems, albeit their highly accurate performance. This paper proposes a new scalable and accurate neural dialogue state tracking model, based on the recently proposed Global-Local Self-Attention encoder (GLAD) model by Zhong et al. which uses global modules to share parameters between estimators for different types (called slots) of dialogue states, and uses local modules to learn slot-specific features. By using only one recurrent networks with global conditioning, compared to (1 + \# slots) recurrent networks with global and local conditioning used in the GLAD model, our proposed model reduces the latency in training and inference times by $35\%$ on average, while preserving performance of belief state tracking, by $97.38\%$ on turn request and $88.51\%$ on joint goal and accuracy. Evaluation on Multi-domain dataset (Multi-WoZ) also demonstrates that our model outperforms GLAD on turn inform and joint goal accuracy.
Augmented Cyclic Adversarial Learning for Domain Adaptation
Aug 07, 2018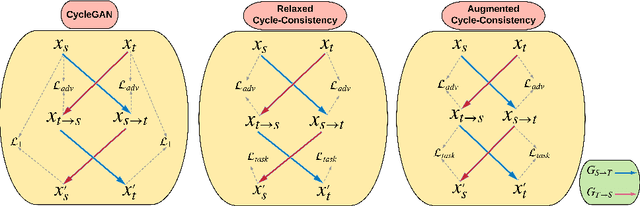
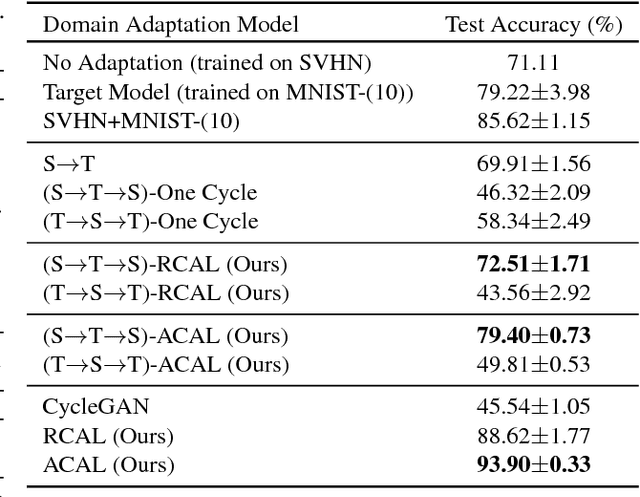
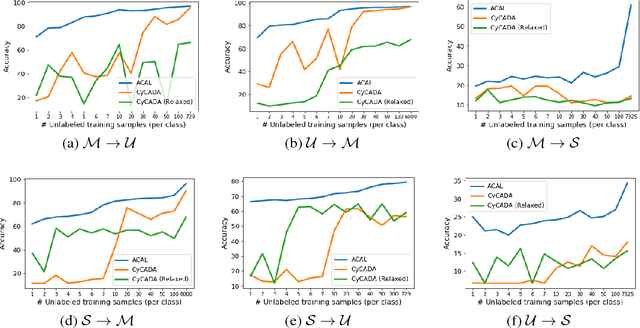
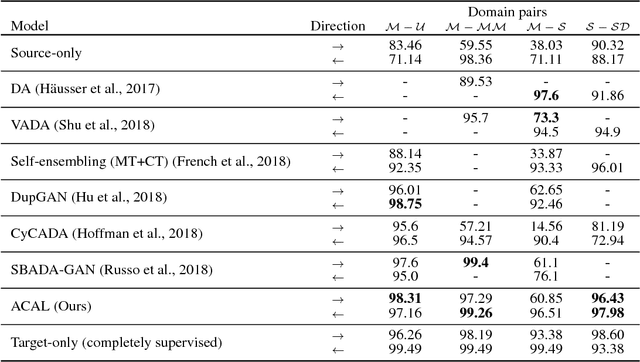
Training a model to perform a task typically requires a large amount of data from the domains in which the task will be applied. However, it is often the case that data are abundant in some domains but scarce in others. Domain adaptation deals with the challenge of adapting a model trained from a data-rich source domain to perform well in a data-poor target domain. In general, this requires learning plausible mappings between domains. CycleGAN is a powerful framework that efficiently learns to map inputs from one domain to another using adversarial training and a cycle-consistency constraint. However, the conventional approach of enforcing cycle-consistency via reconstruction may be overly restrictive in cases where one or more domains have limited training data. In this paper, we propose an augmented cyclic adversarial learning model that enforces the cycle-consistency constraint through an external task specific model, which encourages the preservation of task-relevant content as opposed to exact reconstruction. We explore digit classification with MNIST and SVHN in a low-resource setting in supervised, semi and unsupervised situation. In low-resource supervised setting, the results show that our approach improves absolute performance by $14\%$ and $4\%$ when adapting SVHN to MNIST and vice versa, respectively, which outperforms unsupervised domain adaptation methods that require high-resource unlabeled target domain. Moreover, using only few unsupervised target data, our approach can still outperforms many high-resource unsupervised models. In speech domains, we also adopt a speech recognition model from each domain as the task specific model. Our approach improves absolute performance of speech recognition by $2\%$ for female speakers in the TIMIT dataset, where the majority of training samples are from male voices.
A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation
Jul 09, 2018
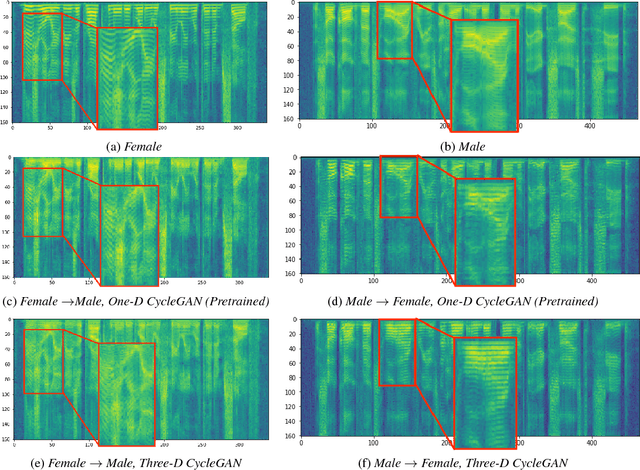
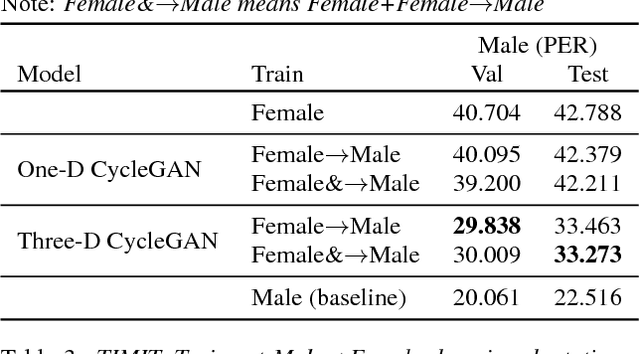
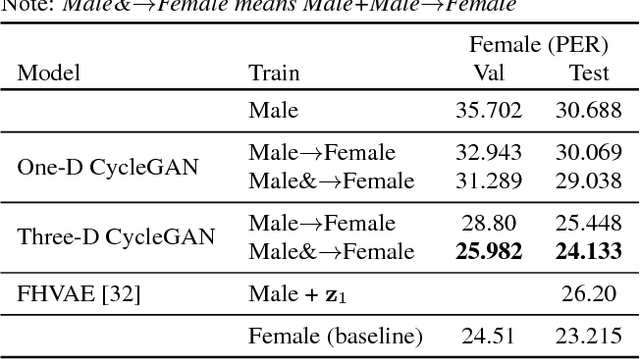
Domain adaptation plays an important role for speech recognition models, in particular, for domains that have low resources. We propose a novel generative model based on cyclic-consistent generative adversarial network (CycleGAN) for unsupervised non-parallel speech domain adaptation. The proposed model employs multiple independent discriminators on the power spectrogram, each in charge of different frequency bands. As a result we have 1) better discriminators that focus on fine-grained details of the frequency features, and 2) a generator that is capable of generating more realistic domain-adapted spectrogram. We demonstrate the effectiveness of our method on speech recognition with gender adaptation, where the model only has access to supervised data from one gender during training, but is evaluated on the other at test time. Our model is able to achieve an average of $7.41\%$ on phoneme error rate, and $11.10\%$ word error rate relative performance improvement as compared to the baseline, on TIMIT and WSJ dataset, respectively. Qualitatively, our model also generates more natural sounding speech, when conditioned on data from the other domain.
Structured Sparse Convolutional Autoencoder
Jan 02, 2017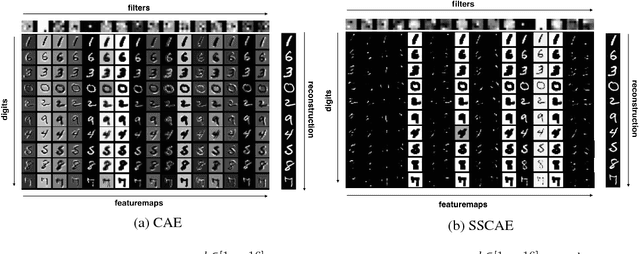
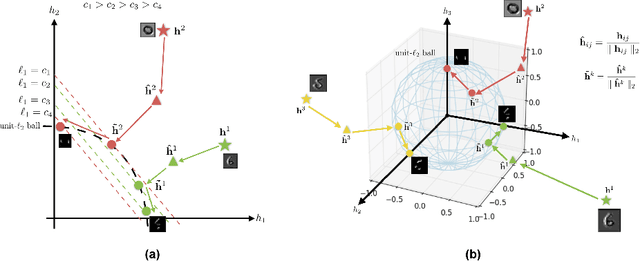
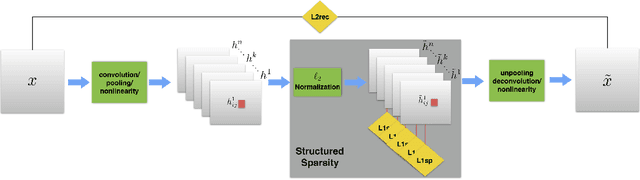

This paper aims to improve the feature learning in Convolutional Networks (Convnet) by capturing the structure of objects. A new sparsity function is imposed on the extracted featuremap to capture the structure and shape of the learned object, extracting interpretable features to improve the prediction performance. The proposed algorithm is based on organizing the activation within and across featuremap by constraining the node activities through $\ell_{2}$ and $\ell_{1}$ normalization in a structured form.
Similarity-based Text Recognition by Deeply Supervised Siamese Network
Jul 05, 2016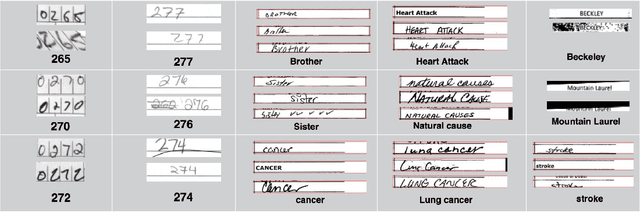

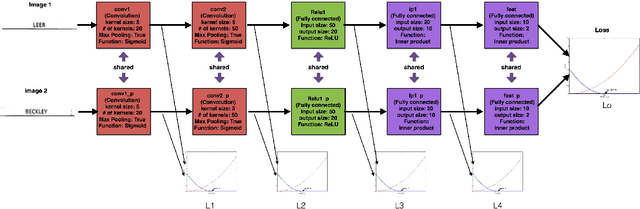

In this paper, we propose a new text recognition model based on measuring the visual similarity of text and predicting the content of unlabeled texts. First a Siamese convolutional network is trained with deep supervision on a labeled training dataset. This network projects texts into a similarity manifold. The Deeply Supervised Siamese network learns visual similarity of texts. Then a K-nearest neighbor classifier is used to predict unlabeled text based on similarity distance to labeled texts. The performance of the model is evaluated on three datasets of machine-print and hand-written text combined. We demonstrate that the model reduces the cost of human estimation by $50\%-85\%$. The error of the system is less than $0.5\%$. The proposed model outperform conventional Siamese network by finding visually-similar barely-readable and readable text, e.g. machine-printed, handwritten, due to deep supervision. The results also demonstrate that the predicted labels are sometimes better than human labels e.g. spelling correction.