 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Neural Dialogue State Tracking Model
Paper and Code
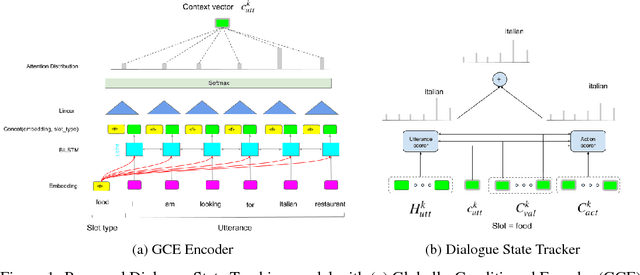



The latency in the current neural based dialogue state tracking models prohibits them from being used efficiently for deployment in production systems, albeit their highly accurate performance. This paper proposes a new scalable and accurate neural dialogue state tracking model, based on the recently proposed Global-Local Self-Attention encoder (GLAD) model by Zhong et al. which uses global modules to share parameters between estimators for different types (called slots) of dialogue states, and uses local modules to learn slot-specific features. By using only one recurrent networks with global conditioning, compared to (1 + \# slots) recurrent networks with global and local conditioning used in the GLAD model, our proposed model reduces the latency in training and inference times by $35\%$ on average, while preserving performance of belief state tracking, by $97.38\%$ on turn request and $88.51\%$ on joint goal and accuracy. Evaluation on Multi-domain dataset (Multi-WoZ) also demonstrates that our model outperforms GLAD on turn inform and joint goal accuracy.