 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More Robust and Accurate Sequential Recommendation with Cascade-guided Adversarial Training
Apr 11, 2023Sequential recommendation models, models that learn from chronological user-item interactions, outperform traditional recommendation models in many settings. Despite the success of sequential recommendation models, their robustness has recently come into question. Two properties unique to the nature of sequential recommendation models may impair their robustness - the cascade effects induced during training and the model's tendency to rely too heavily on temporal information. To address these vulnerabilities, we propose Cascade-guided Adversarial training, a new adversarial training procedure that is specifically designed for sequential recommendation models. Our approach harnesses the intrinsic cascade effects present in sequential modeling to produce strategic adversarial perturbations to item embeddings during training. Experiments on training state-of-the-art sequential models on four public datasets from different domains show that our training approach produces superior model ranking accuracy and superior model robustness to real item replacement perturbations when compared to both standard model training and generic adversarial training.
Generating Negative Samples for Sequential Recommendation
Aug 07, 2022To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.
ELECRec: Training Sequential Recommenders as Discriminators
Apr 16, 2022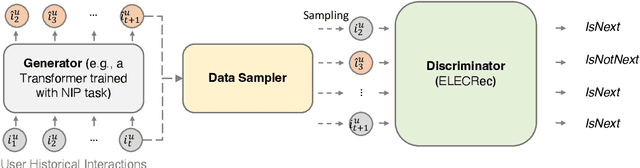
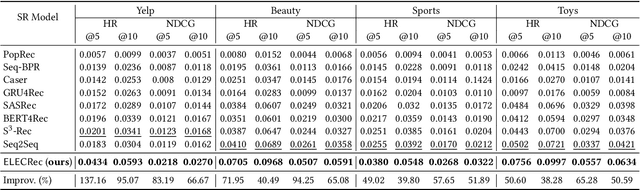
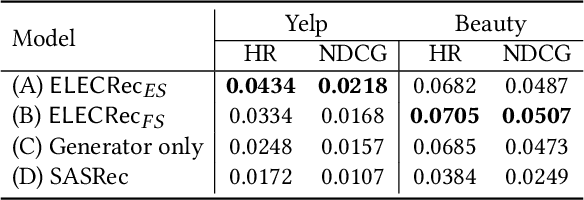

Sequential recommendation is often considered as a generative task, i.e., training a sequential encoder to generate the next item of a user's interests based on her historical interacted items. Despite their prevalence, these methods usually require training with more meaningful samples to be effective, which otherwise will lead to a poorly trained model. In this work, we propose to train the sequential recommenders as discriminators rather than generators. Instead of predicting the next item, our method trains a discriminator to distinguish if a sampled item is a 'real' target item or not. A generator, as an auxiliary model, is trained jointly with the discriminator to sample plausible alternative next items and will be thrown out after training. The trained discriminator is considered as the final SR model and denoted as \modelname. Experiments conducted on four datasets demonstrate the effectiveness and efficiency of the proposed approach.
Improving Contrastive Learning with Model Augmentation
Mar 25, 2022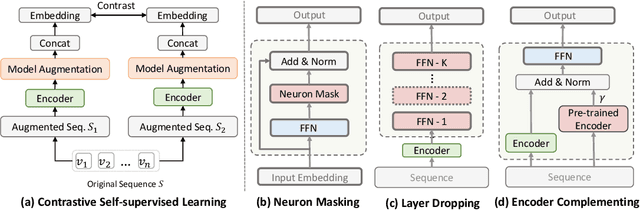

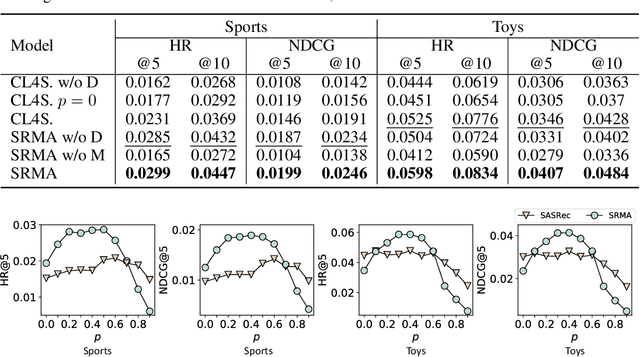
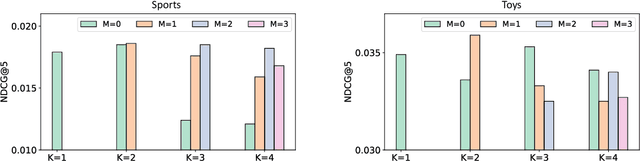
The sequential recommendation aims at predicting the next items in user behaviors, which can be solved by characterizing item relationships in sequences. Due to the data sparsity and noise issues in sequences, a new self-supervised learning (SSL) paradigm is proposed to improve the performance, which employs contrastive learning between positive and negative views of sequences. However, existing methods all construct views by adopting augmentation from data perspectives, while we argue that 1) optimal data augmentation methods are hard to devise, 2) data augmentation methods destroy sequential correlations, and 3) data augmentation fails to incorporate comprehensive self-supervised signals. Therefore, we investigate the possibility of model augmentation to construct view pairs. We propose three levels of model augmentation methods: neuron masking, layer dropping, and encoder complementing. This work opens up a novel direction in constructing views for contrastive SSL. Experiments verify the efficacy of model augmentation for the SSL in the sequential recommendation. Code is available\footnote{\url{https://github.com/salesforce/SRMA}}.
Intent Contrastive Learning for Sequential Recommendation
Feb 05, 2022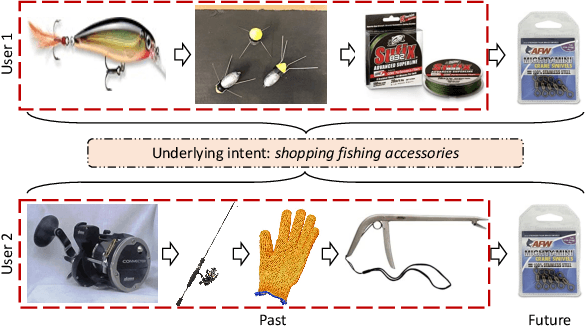
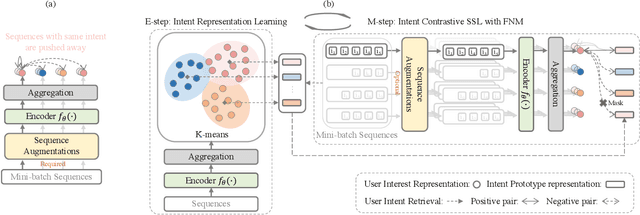

Users' interactions with items are driven by various intents (e.g., preparing for holiday gifts, shopping for fishing equipment, etc.).However, users' underlying intents are often unobserved/latent, making it challenging to leverage such latent intents forSequentialrecommendation(SR). To investigate the benefits of latent intents and leverage them effectively for recommendation, we proposeIntentContrastiveLearning(ICL), a general learning paradigm that leverages a latent intent variable into SR. The core idea is to learn users' intent distribution functions from unlabeled user behavior sequences and optimize SR models with contrastive self-supervised learning (SSL) by considering the learned intents to improve recommendation. Specifically, we introduce a latent variable to represent users' intents and learn the distribution function of the latent variable via clustering. We propose to leverage the learned intents into SR models via contrastive SSL, which maximizes the agreement between a view of sequence and its corresponding intent. The training is alternated between intent representation learning and the SR model optimization steps within the generalized expectation-maximization (EM) framework. Fusing user intent information into SR also improves model robustness. Experiments conducted on four real-world datasets demonstrate the superiority of the proposed learning paradigm, which improves performance, and robustness against data sparsity and noisy interaction issues.
Modeling Dynamic Attributes for Next Basket Recommendation
Sep 23, 2021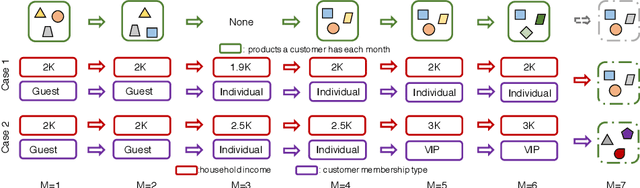

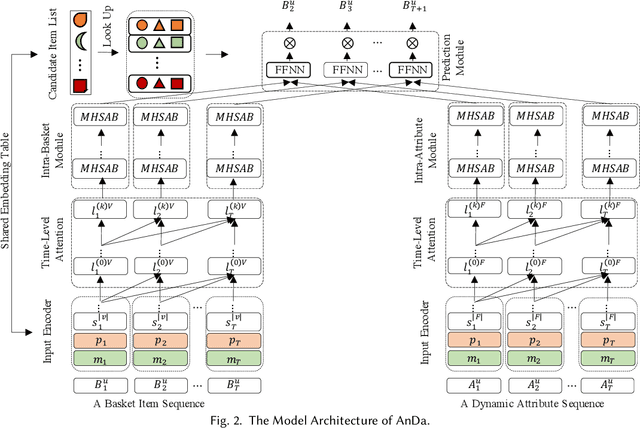

Traditional approaches to next item and next basket recommendation typically extract users' interests based on their past interactions and associated static contextual information (e.g. a user id or item category). However, extracted interests can be inaccurate and become obsolete. Dynamic attributes, such as user income changes, item price changes (etc.), change over time. Such dynamics can intrinsically reflect the evolution of users' interests. We argue that modeling such dynamic attributes can boost recommendation performance. However, properly integrating them into user interest models is challenging since attribute dynamics can be diverse such as time-interval aware, periodic patterns (etc.), and they represent users' behaviors from different perspectives, which can happen asynchronously with interactions. Besides dynamic attributes, items in each basket contain complex interdependencies which might be beneficial but nontrivial to effectively capture. To address these challenges, we propose a novel Attentive network to model Dynamic attributes (named AnDa). AnDa separately encodes dynamic attributes and basket item sequences. We design a periodic aware encoder to allow the model to capture various temporal patterns from dynamic attributes. To effectively learn useful item relationships, intra-basket attention module is proposed. Experimental results on three real-world datasets demonstrate that our method consistently outperforms the state-of-the-art.
Contrastive Self-supervised Sequential Recommendation with Robust Augmentation
Aug 14, 2021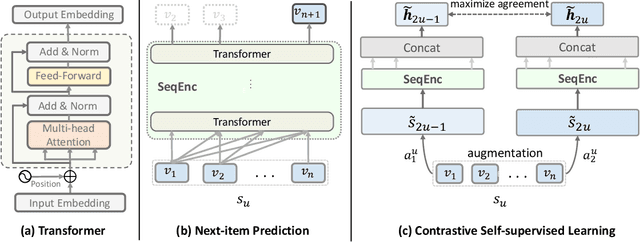
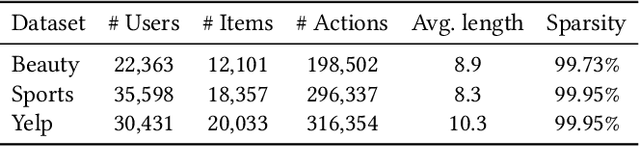
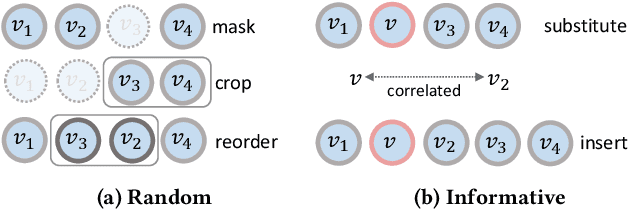
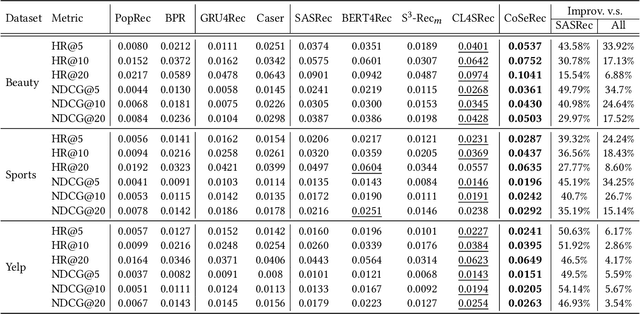
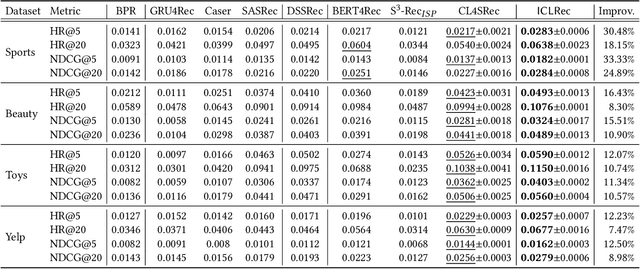
Sequential Recommendationdescribes a set of techniques to model dynamic user behavior in order to predict future interactions in sequential user data. At their core, such approaches model transition probabilities between items in a sequence, whether through Markov chains, recurrent networks, or more recently, Transformers. However both old and new issues remain, including data-sparsity and noisy data; such issues can impair the performance, especially in complex, parameter-hungry models. In this paper, we investigate the application of contrastive Self-Supervised Learning (SSL) to the sequential recommendation, as a way to alleviate some of these issues. Contrastive SSL constructs augmentations from unlabelled instances, where agreements among positive pairs are maximized. It is challenging to devise a contrastive SSL framework for a sequential recommendation, due to its discrete nature, correlations among items, and skewness of length distributions. To this end, we propose a novel framework, Contrastive Self-supervised Learning for sequential Recommendation (CoSeRec). We introduce two informative augmentation operators leveraging item correlations to create high-quality views for contrastive learning. Experimental results on three real-world datasets demonstrate the effectiveness of the proposed method on improving model performance and the robustness against sparse and noisy data. Our implementation is available online at \url{https://github.com/YChen1993/CoSeRec}
Learning Graph Pooling and Hybrid Convolutional Operations for Text Representations
Jan 21, 2019


With the development of graph convolutional networks (GCN), deep learning methods have started to be used on graph data. In additional to convolutional layers, pooling layers are another important components of deep learning. However, no effective pooling methods have been developed for graphs currently. In this work, we propose the graph pooling (gPool) layer, which employs a trainable projection vector to measure the importance of nodes in graphs. By selecting the k-most important nodes to form the new graph, gPool achieves the same objective as regular max pooling layers operating on images. Another limitation of GCN when used on graph-based text representation tasks is that, GCNs do not consider the order information of nodes in graph. To address this limitation, we propose the hybrid convolutional (hConv) layer that combines GCN and regular convolutional operations. The hConv layer is capable of increasing receptive fields quickly and computing features automatically. Based on the proposed gPool and hConv layers, we develop new deep networks for text categorization tasks. Our results show that the networks based on gPool and hConv layers achieves new state-of-the-art performance as compared to baseline methods.
Dense Transformer Networks
Jun 08, 2017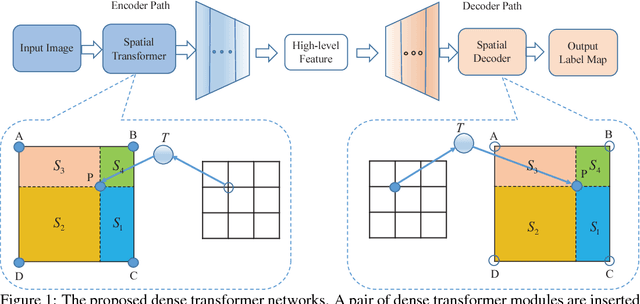



The key idea of current deep learning methods for dense prediction is to apply a model on a regular patch centered on each pixel to make pixel-wise predictions. These methods are limited in the sense that the patches are determined by network architecture instead of learned from data. In this work, we propose the dense transformer networks, which can learn the shapes and sizes of patches from data. The dense transformer networks employ an encoder-decoder architecture, and a pair of dense transformer modules are inserted into each of the encoder and decoder paths. The novelty of this work is that we provide technical solutions for learning the shapes and sizes of patches from data and efficiently restoring the spatial correspondence required for dense prediction. The proposed dense transformer modules are differentiable, thus the entire network can be trained. We apply the proposed networks on natural and biological image segmentation tasks and show superior performance is achieved in comparison to baseline methods.