 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Multi-hop Question Answering as Single Sequence Prediction
Paper and Code
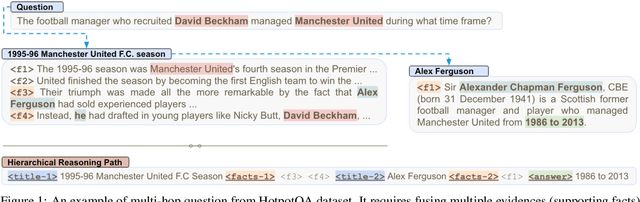
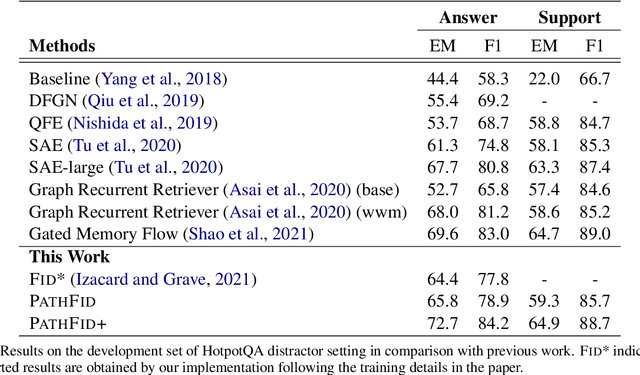
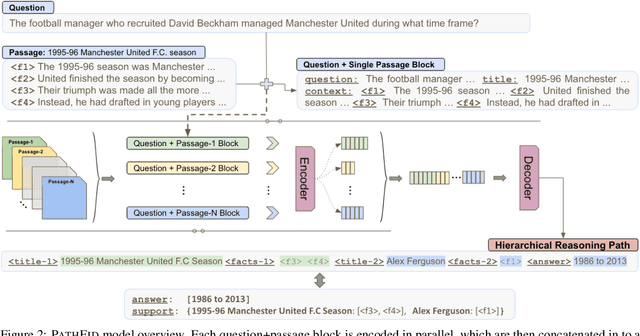
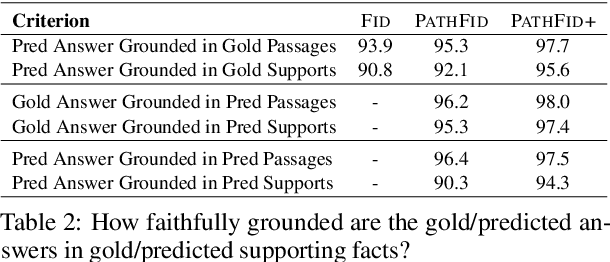
Fusion-in-decoder (Fid) (Izacard and Grave, 2020) is a generative question answering (QA) model that leverages passage retrieval with a pre-trained transformer and pushed the state of the art on single-hop QA. However, the complexity of multi-hop QA hinders the effectiveness of the generative QA approach. In this work, we propose a simple generative approach (PathFid) that extends the task beyond just answer generation by explicitly modeling the reasoning process to resolve the answer for multi-hop questions. By linearizing the hierarchical reasoning path of supporting passages, their key sentences, and finally the factoid answer, we cast the problem as a single sequence prediction task. To facilitate complex reasoning with multiple clues, we further extend the unified flat representation of multiple input documents by encoding cross-passage interactions. Our extensive experiments demonstrate that PathFid leads to strong performance gains on two multi-hop QA datasets: HotpotQA and IIRC. Besides the performance gains, PathFid is more interpretable, which in turn yields answers that are more faithfully grounded to the supporting passages and facts compared to the baseline Fid model.